 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiamese-Driven Optimization for Low-Resolution Image Latent Embedding in Image Captioning
Dec 09, 2025Image captioning is essential in many fields including assisting visually impaired individuals, improving content management systems, and enhancing human-computer interaction. However, a recent challenge in this domain is dealing with low-resolution image (LRI). While performance can be improved by using larger models like transformers for encoding, these models are typically heavyweight, demanding significant computational resources and memory, leading to challenges in retraining. To address this, the proposed SOLI (Siamese-Driven Optimization for Low-Resolution Image Latent Embedding in Image Captioning) approach presents a solution specifically designed for lightweight, low-resolution images captioning. It employs a Siamese network architecture to optimize latent embeddings, enhancing the efficiency and accuracy of the image-to-text translation process. By focusing on a dual-pathway neural network structure, SOLI minimizes computational overhead without sacrificing performance, making it an ideal choice for training on resource-constrained scenarios.
* 6 pages
Analyzing the Impact of Low-Rank Adaptation for Cross-Domain Few-Shot Object Detection in Aerial Images
Apr 08, 2025

This paper investigates the application of Low-Rank Adaptation (LoRA) to small models for cross-domain few-shot object detection in aerial images. Originally designed for large-scale models, LoRA helps mitigate overfitting, making it a promising approach for resource-constrained settings. We integrate LoRA into DiffusionDet, and evaluate its performance on the DOTA and DIOR datasets. Our results show that LoRA applied after an initial fine-tuning slightly improves performance in low-shot settings (e.g., 1-shot and 5-shot), while full fine-tuning remains more effective in higher-shot configurations. These findings highlight LoRA's potential for efficient adaptation in aerial object detection, encouraging further research into parameter-efficient fine-tuning strategies for few-shot learning. Our code is available here: https://github.com/HichTala/LoRA-DiffusionDet.
Interactive Masked Image Modeling for Multimodal Object Detection in Remote Sensing
Sep 13, 2024Object detection in remote sensing imagery plays a vital role in various Earth observation applications. However, unlike object detection in natural scene images, this task is particularly challenging due to the abundance of small, often barely visible objects across diverse terrains. To address these challenges, multimodal learning can be used to integrate features from different data modalities, thereby improving detection accuracy. Nonetheless, the performance of multimodal learning is often constrained by the limited size of labeled datasets. In this paper, we propose to use Masked Image Modeling (MIM) as a pre-training technique, leveraging self-supervised learning on unlabeled data to enhance detection performance. However, conventional MIM such as MAE which uses masked tokens without any contextual information, struggles to capture the fine-grained details due to a lack of interactions with other parts of image. To address this, we propose a new interactive MIM method that can establish interactions between different tokens, which is particularly beneficial for object detection in remote sensing. The extensive ablation studies and evluation demonstrate the effectiveness of our approach.
Universal End-to-End Neural Network for Lossy Image Compression
Sep 10, 2024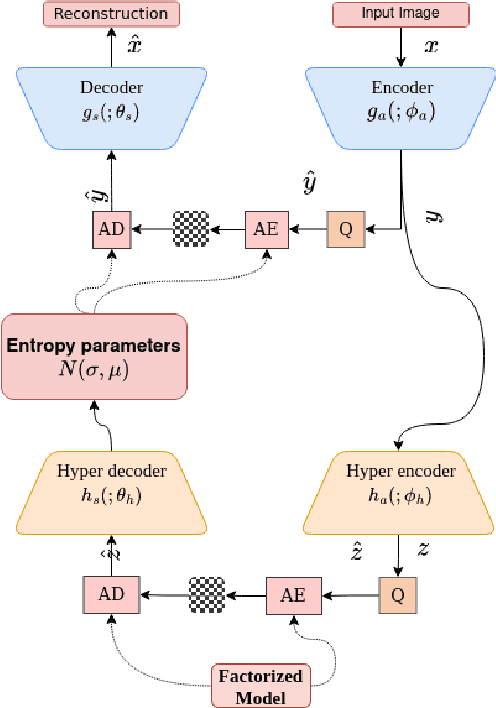
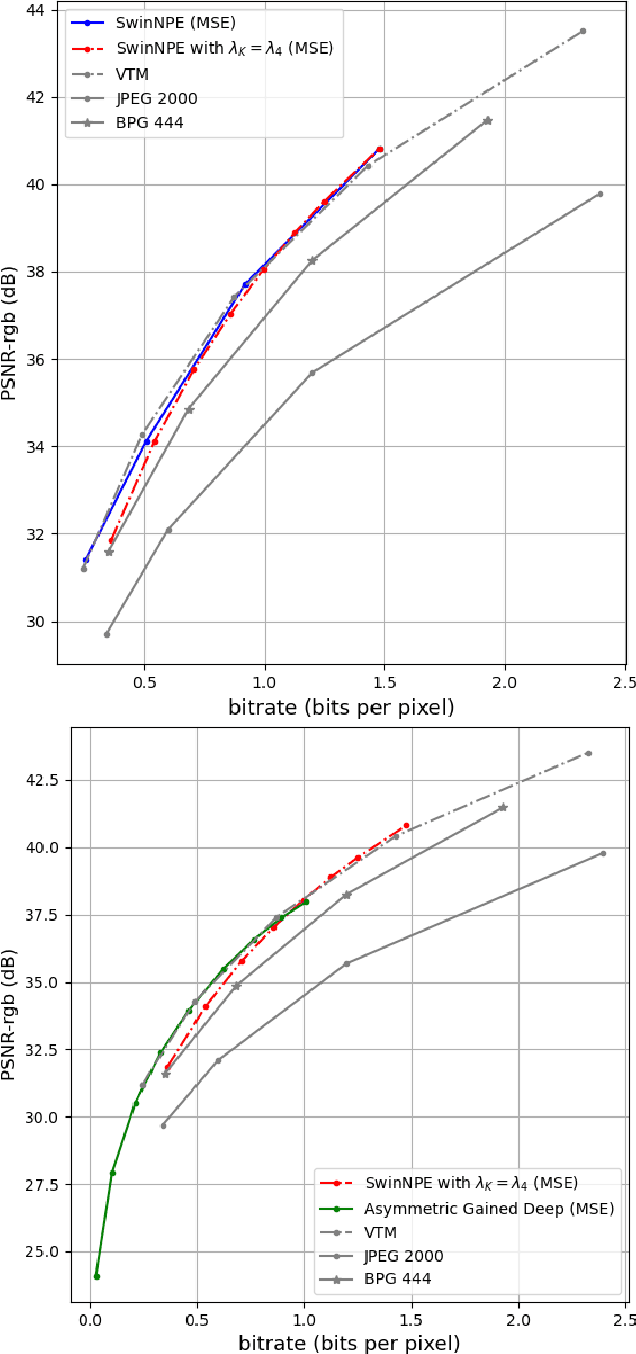
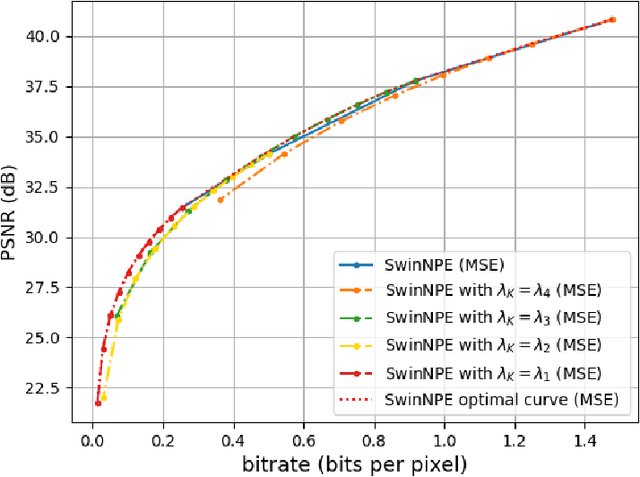
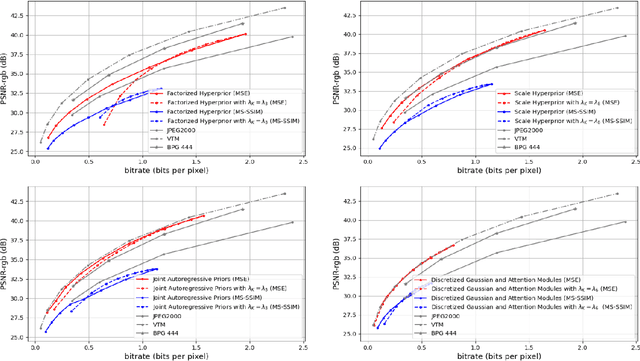
This paper presents variable bitrate lossy image compression using a VAE-based neural network. An adaptable image quality adjustment strategy is proposed. The key innovation involves adeptly adjusting the input scale exclusively during the inference process, resulting in an exceptionally efficient rate-distortion mechanism. Through extensive experimentation, across diverse VAE-based compression architectures (CNN, ViT) and training methodologies (MSE, SSIM), our approach exhibits remarkable universality. This success is attributed to the inherent generalization capacity of neural networks. Unlike methods that adjust model architecture or loss functions, our approach emphasizes simplicity, reducing computational complexity and memory requirements. The experiments not only highlight the effectiveness of our approach but also indicate its potential to drive advancements in variable-rate neural network lossy image compression methodologies.
Convolutional Transformer-Based Image Compression
Sep 06, 2024In this paper, we present a novel transformer-based architecture for end-to-end image compression. Our architecture incorporates blocks that effectively capture local dependencies between tokens, eliminating the need for positional encoding by integrating convolutional operations within the multi-head attention mechanism. We demonstrate through experiments that our proposed framework surpasses state-of-the-art CNN-based architectures in terms of the trade-off between bit-rate and distortion and achieves comparable results to transformer-based methods while maintaining lower computational complexity.
Efficient Image_Compression Using Advanced State Space Models
Sep 04, 2024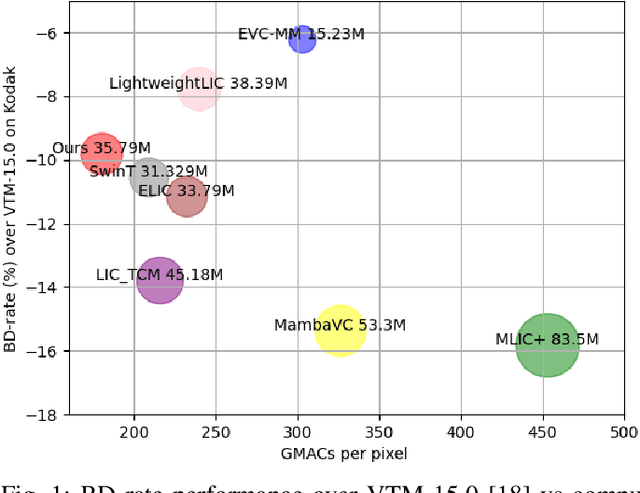
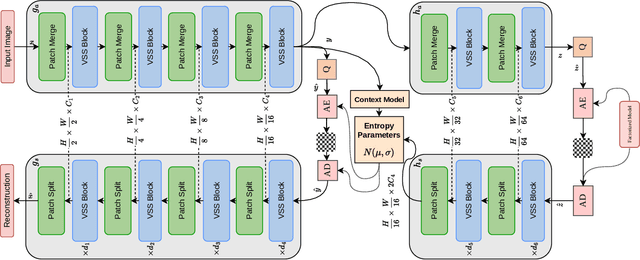
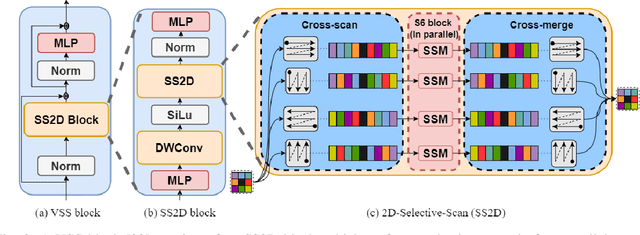
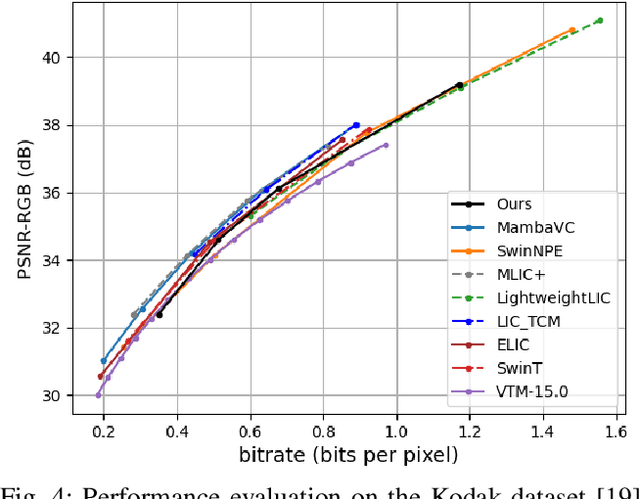
Transformers have led to learning-based image compression methods that outperform traditional approaches. However, these methods often suffer from high complexity, limiting their practical application. To address this, various strategies such as knowledge distillation and lightweight architectures have been explored, aiming to enhance efficiency without significantly sacrificing performance. This paper proposes a State Space Model-based Image Compression (SSMIC) architecture. This novel architecture balances performance and computational efficiency, making it suitable for real-world applications. Experimental evaluations confirm the effectiveness of our model in achieving a superior BD-rate while significantly reducing computational complexity and latency compared to competitive learning-based image compression methods.
Rethinking Intersection Over Union for Small Object Detection in Few-Shot Regime
Jul 17, 2023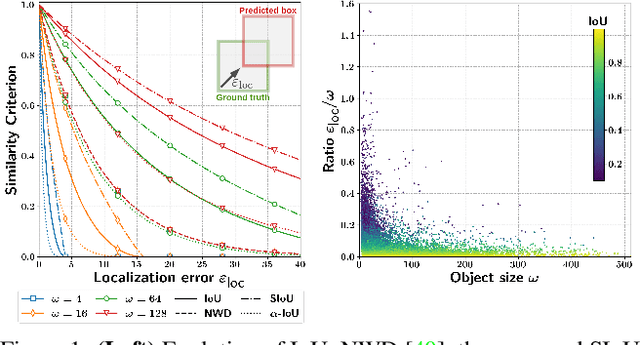

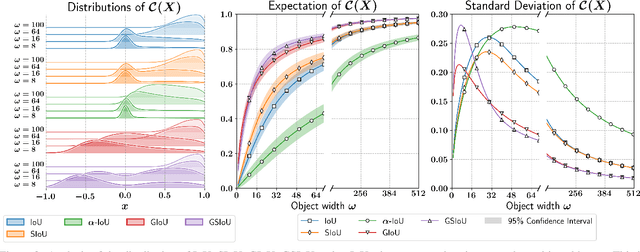
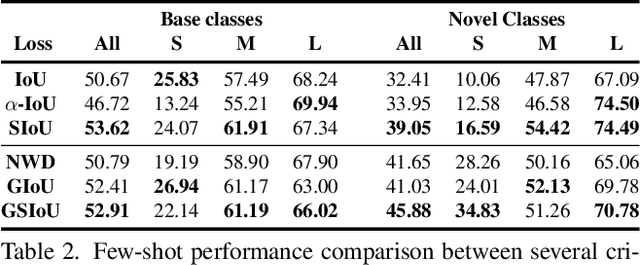
In Few-Shot Object Detection (FSOD), detecting small objects is extremely difficult. The limited supervision cripples the localization capabilities of the models and a few pixels shift can dramatically reduce the Intersection over Union (IoU) between the ground truth and predicted boxes for small objects. To this end, we propose Scale-adaptive Intersection over Union (SIoU), a novel box similarity measure. SIoU changes with the objects' size, it is more lenient with small object shifts. We conducted a user study and SIoU better aligns than IoU with human judgment. Employing SIoU as an evaluation criterion helps to build more user-oriented models. SIoU can also be used as a loss function to prioritize small objects during training, outperforming existing loss functions. SIoU improves small object detection in the non-few-shot regime, but this setting is unrealistic in the industry as annotated detection datasets are often too expensive to acquire. Hence, our experiments mainly focus on the few-shot regime to demonstrate the superiority and versatility of SIoU loss. SIoU improves significantly FSOD performance on small objects in both natural (Pascal VOC and COCO datasets) and aerial images (DOTA and DIOR). In aerial imagery, small objects are critical and SIoU loss achieves new state-of-the-art FSOD on DOTA and DIOR.
A Comparative Attention Framework for Better Few-Shot Object Detection on Aerial Images
Oct 25, 2022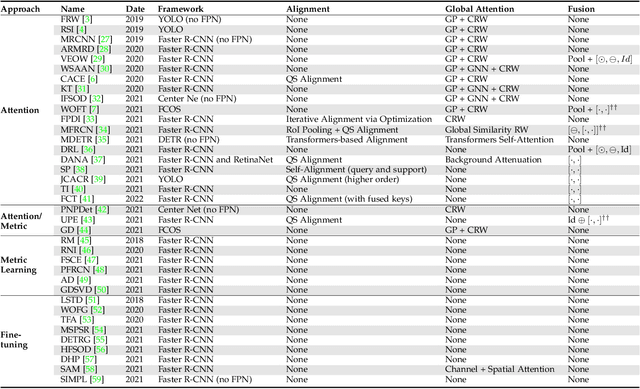
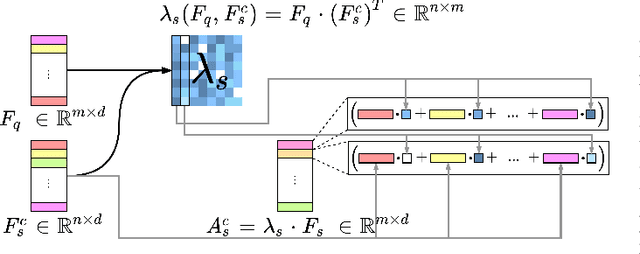
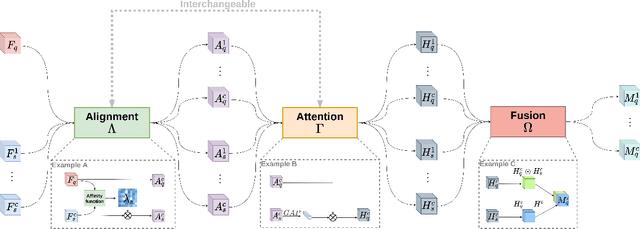

Few-Shot Object Detection (FSOD) methods are mainly designed and evaluated on natural image datasets such as Pascal VOC and MS COCO. However, it is not clear whether the best methods for natural images are also the best for aerial images. Furthermore, direct comparison of performance between FSOD methods is difficult due to the wide variety of detection frameworks and training strategies. Therefore, we propose a benchmarking framework that provides a flexible environment to implement and compare attention-based FSOD methods. The proposed framework focuses on attention mechanisms and is divided into three modules: spatial alignment, global attention, and fusion layer. To remain competitive with existing methods, which often leverage complex training, we propose new augmentation techniques designed for object detection. Using this framework, several FSOD methods are reimplemented and compared. This comparison highlights two distinct performance regimes on aerial and natural images: FSOD performs worse on aerial images. Our experiments suggest that small objects, which are harder to detect in the few-shot setting, account for the poor performance. Finally, we develop a novel multiscale alignment method, Cross-Scales Query-Support Alignment (XQSA) for FSOD, to improve the detection of small objects. XQSA outperforms the state-of-the-art significantly on DOTA and DIOR.
A Unified Framework for Attention-Based Few-Shot Object Detection
Jan 06, 2022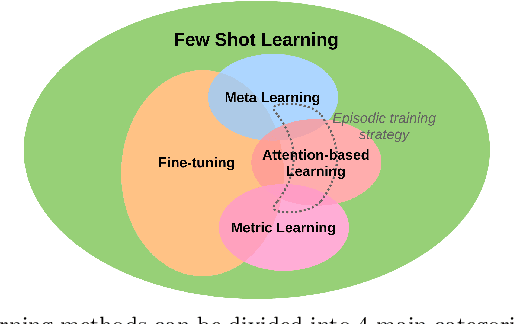
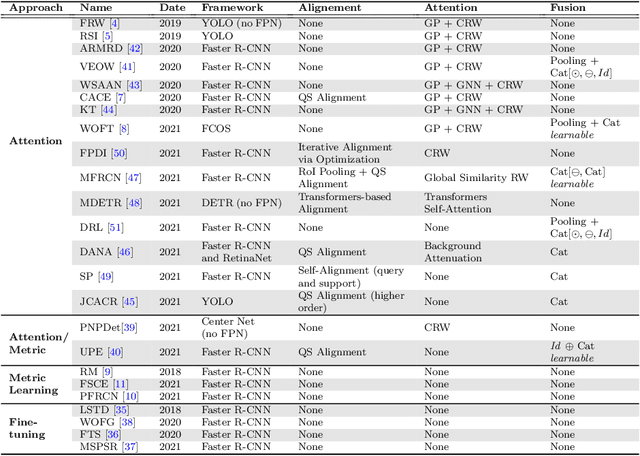
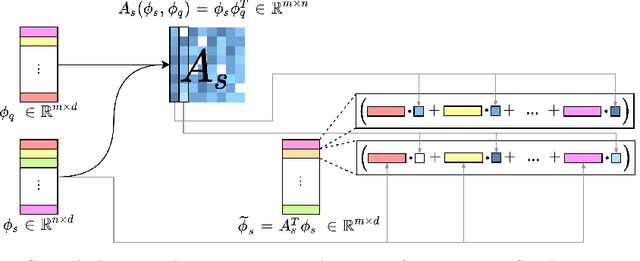

Few-Shot Object Detection (FSOD) is a rapidly growing field in computer vision. It consists in finding all occurrences of a given set of classes with only a few annotated examples for each class. Numerous methods have been proposed to address this challenge and most of them are based on attention mechanisms. However, the great variety of classic object detection frameworks and training strategies makes performance comparison between methods difficult. In particular, for attention-based FSOD methods, it is laborious to compare the impact of the different attention mechanisms on performance. This paper aims at filling this shortcoming. To do so, a flexible framework is proposed to allow the implementation of most of the attention techniques available in the literature. To properly introduce such a framework, a detailed review of the existing FSOD methods is firstly provided. Some different attention mechanisms are then reimplemented within the framework and compared with all other parameters fixed.
Experience feedback using Representation Learning for Few-Shot Object Detection on Aerial Images
Sep 27, 2021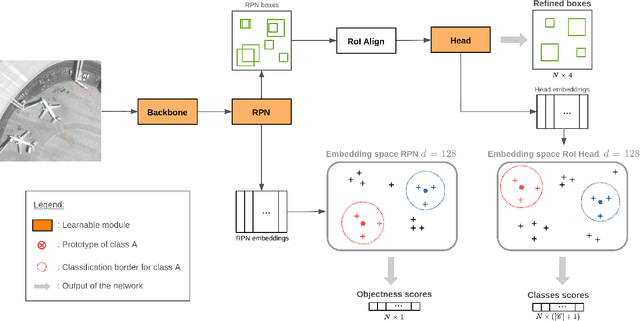
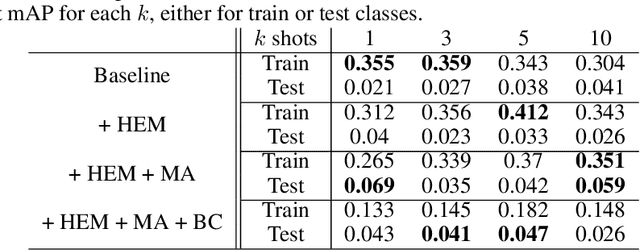
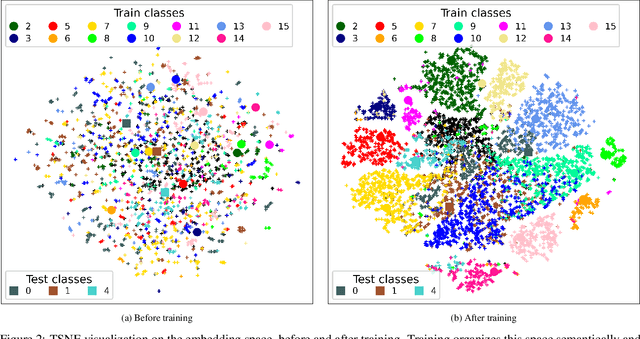
This paper proposes a few-shot method based on Faster R-CNN and representation learning for object detection in aerial images. The two classification branches of Faster R-CNN are replaced by prototypical networks for online adaptation to new classes. These networks produce embeddings vectors for each generated box, which are then compared with class prototypes. The distance between an embedding and a prototype determines the corresponding classification score. The resulting networks are trained in an episodic manner. A new detection task is randomly sampled at each epoch, consisting in detecting only a subset of the classes annotated in the dataset. This training strategy encourages the network to adapt to new classes as it would at test time. In addition, several ideas are explored to improve the proposed method such as a hard negative examples mining strategy and self-supervised clustering for background objects. The performance of our method is assessed on DOTA, a large-scale remote sensing images dataset. The experiments conducted provide a broader understanding of the capabilities of representation learning. It highlights in particular some intrinsic weaknesses for the few-shot object detection task. Finally, some suggestions and perspectives are formulated according to these insights.