 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Masked Image Modeling for Multimodal Object Detection in Remote Sensing
Sep 13, 2024Object detection in remote sensing imagery plays a vital role in various Earth observation applications. However, unlike object detection in natural scene images, this task is particularly challenging due to the abundance of small, often barely visible objects across diverse terrains. To address these challenges, multimodal learning can be used to integrate features from different data modalities, thereby improving detection accuracy. Nonetheless, the performance of multimodal learning is often constrained by the limited size of labeled datasets. In this paper, we propose to use Masked Image Modeling (MIM) as a pre-training technique, leveraging self-supervised learning on unlabeled data to enhance detection performance. However, conventional MIM such as MAE which uses masked tokens without any contextual information, struggles to capture the fine-grained details due to a lack of interactions with other parts of image. To address this, we propose a new interactive MIM method that can establish interactions between different tokens, which is particularly beneficial for object detection in remote sensing. The extensive ablation studies and evluation demonstrate the effectiveness of our approach.
Multimodal Transformer Using Cross-Channel attention for Object Detection in Remote Sensing Images
Oct 21, 2023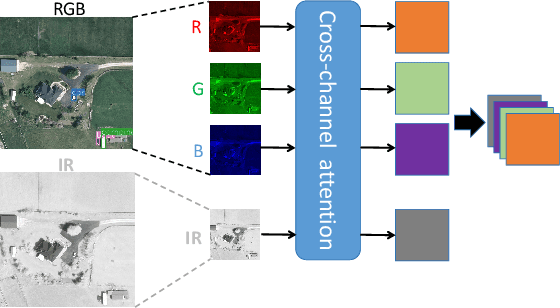



Object detection in Remote Sensing Images (RSI) is a critical task for numerous applications in Earth Observation (EO). Unlike general object detection, object detection in RSI has specific challenges: 1) the scarcity of labeled data in RSI compared to general object detection datasets, and 2) the small objects presented in a high-resolution image with a vast background. To address these challenges, we propose a multimodal transformer exploring multi-source remote sensing data for object detection. Instead of directly combining the multimodal input through a channel-wise concatenation, which ignores the heterogeneity of different modalities, we propose a cross-channel attention module. This module learns the relationship between different channels, enabling the construction of a coherent multimodal input by aligning the different modalities at the early stage. We also introduce a new architecture based on the Swin transformer that incorporates convolution layers in non-shifting blocks while maintaining fixed dimensions, allowing for the generation of fine-to-coarse representations with a favorable accuracy-computation trade-off. The extensive experiments prove the effectiveness of the proposed multimodal fusion module and architecture, demonstrating their applicability to multimodal aerial imagery.