 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Transformer Using Cross-Channel attention for Object Detection in Remote Sensing Images
Oct 21, 2023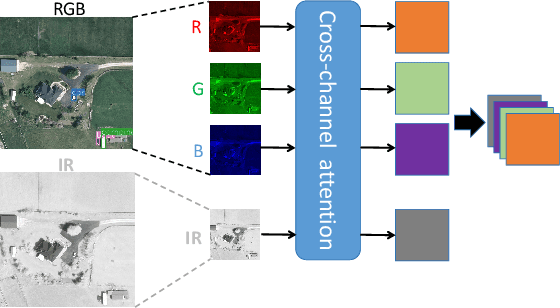



Object detection in Remote Sensing Images (RSI) is a critical task for numerous applications in Earth Observation (EO). Unlike general object detection, object detection in RSI has specific challenges: 1) the scarcity of labeled data in RSI compared to general object detection datasets, and 2) the small objects presented in a high-resolution image with a vast background. To address these challenges, we propose a multimodal transformer exploring multi-source remote sensing data for object detection. Instead of directly combining the multimodal input through a channel-wise concatenation, which ignores the heterogeneity of different modalities, we propose a cross-channel attention module. This module learns the relationship between different channels, enabling the construction of a coherent multimodal input by aligning the different modalities at the early stage. We also introduce a new architecture based on the Swin transformer that incorporates convolution layers in non-shifting blocks while maintaining fixed dimensions, allowing for the generation of fine-to-coarse representations with a favorable accuracy-computation trade-off. The extensive experiments prove the effectiveness of the proposed multimodal fusion module and architecture, demonstrating their applicability to multimodal aerial imagery.