 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow DDAIR you? Disambiguated Data Augmentation for Intent Recognition
Jan 16, 2026Large Language Models (LLMs) are effective for data augmentation in classification tasks like intent detection. In some cases, they inadvertently produce examples that are ambiguous with regard to untargeted classes. We present DDAIR (Disambiguated Data Augmentation for Intent Recognition) to mitigate this problem. We use Sentence Transformers to detect ambiguous class-guided augmented examples generated by LLMs for intent recognition in low-resource scenarios. We identify synthetic examples that are semantically more similar to another intent than to their target one. We also provide an iterative re-generation method to mitigate such ambiguities. Our findings show that sentence embeddings effectively help to (re)generate less ambiguous examples, and suggest promising potential to improve classification performance in scenarios where intents are loosely or broadly defined.
Intent Recognition and Out-of-Scope Detection using LLMs in Multi-party Conversations
Jul 29, 2025Intent recognition is a fundamental component in task-oriented dialogue systems (TODS). Determining user intents and detecting whether an intent is Out-of-Scope (OOS) is crucial for TODS to provide reliable responses. However, traditional TODS require large amount of annotated data. In this work we propose a hybrid approach to combine BERT and LLMs in zero and few-shot settings to recognize intents and detect OOS utterances. Our approach leverages LLMs generalization power and BERT's computational efficiency in such scenarios. We evaluate our method on multi-party conversation corpora and observe that sharing information from BERT outputs to LLMs leads to system performance improvement.
Decompositional Reasoning for Graph Retrieval with Large Language Models
Jun 16, 2025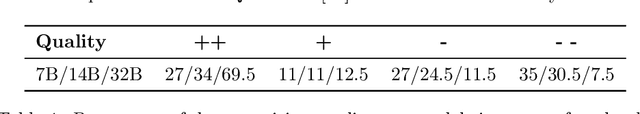


Large Language Models (LLMs) excel at many NLP tasks, but struggle with multi-hop reasoning and factual consistency, limiting their effectiveness on knowledge-intensive tasks like complex question answering (QA). Linking Knowledge Graphs (KG) and LLMs has shown promising results, but LLMs generally lack the ability to reason efficiently over graph-structured information. To tackle this problem, we propose a novel retrieval approach that integrates textual knowledge graphs into the LLM reasoning process via query decomposition. Our method decomposes complex questions into sub-questions, retrieves relevant textual subgraphs, and composes a question-specific knowledge graph to guide answer generation. For that, we use a weighted similarity function that focuses on both the complex question and the generated subquestions to extract a relevant subgraph, which allows efficient and precise retrieval for complex questions and improves the performance of LLMs on multi-hop QA tasks. This structured reasoning pipeline enhances factual grounding and interpretability while leveraging the generative strengths of LLMs. We evaluate our method on standard multi-hop QA benchmarks and show that it achieves comparable or superior performance to competitive existing methods, using smaller models and fewer LLM calls.
From LIMA to DeepLIMA: following a new path of interoperability
Sep 10, 2024In this article, we describe the architecture of the LIMA (Libre Multilingual Analyzer) framework and its recent evolution with the addition of new text analysis modules based on deep neural networks. We extended the functionality of LIMA in terms of the number of supported languages while preserving existing configurable architecture and the availability of previously developed rule-based and statistical analysis components. Models were trained for more than 60 languages on the Universal Dependencies 2.5 corpora, WikiNer corpora, and CoNLL-03 dataset. Universal Dependencies allowed us to increase the number of supported languages and to generate models that could be integrated into other platforms. This integration of ubiquitous Deep Learning Natural Language Processing models and the use of standard annotated collections using Universal Dependencies can be viewed as a new path of interoperability, through the normalization of models and data, that are complementary to a more standard technical interoperability, implemented in LIMA through services available in Docker containers on Docker Hub.
X-RiSAWOZ: High-Quality End-to-End Multilingual Dialogue Datasets and Few-shot Agents
Jun 30, 2023



Task-oriented dialogue research has mainly focused on a few popular languages like English and Chinese, due to the high dataset creation cost for a new language. To reduce the cost, we apply manual editing to automatically translated data. We create a new multilingual benchmark, X-RiSAWOZ, by translating the Chinese RiSAWOZ to 4 languages: English, French, Hindi, Korean; and a code-mixed English-Hindi language. X-RiSAWOZ has more than 18,000 human-verified dialogue utterances for each language, and unlike most multilingual prior work, is an end-to-end dataset for building fully-functioning agents. The many difficulties we encountered in creating X-RiSAWOZ led us to develop a toolset to accelerate the post-editing of a new language dataset after translation. This toolset improves machine translation with a hybrid entity alignment technique that combines neural with dictionary-based methods, along with many automated and semi-automated validation checks. We establish strong baselines for X-RiSAWOZ by training dialogue agents in the zero- and few-shot settings where limited gold data is available in the target language. Our results suggest that our translation and post-editing methodology and toolset can be used to create new high-quality multilingual dialogue agents cost-effectively. Our dataset, code, and toolkit are released open-source.
GeSERA: General-domain Summary Evaluation by Relevance Analysis
Oct 07, 2021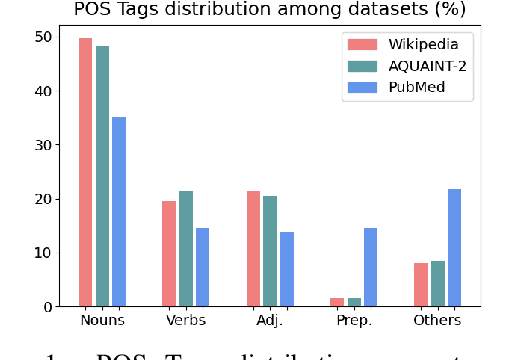
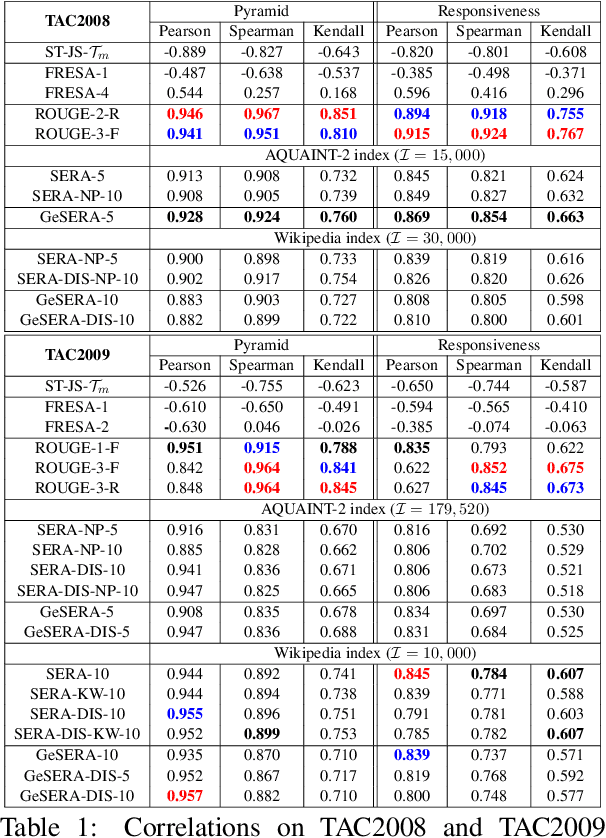

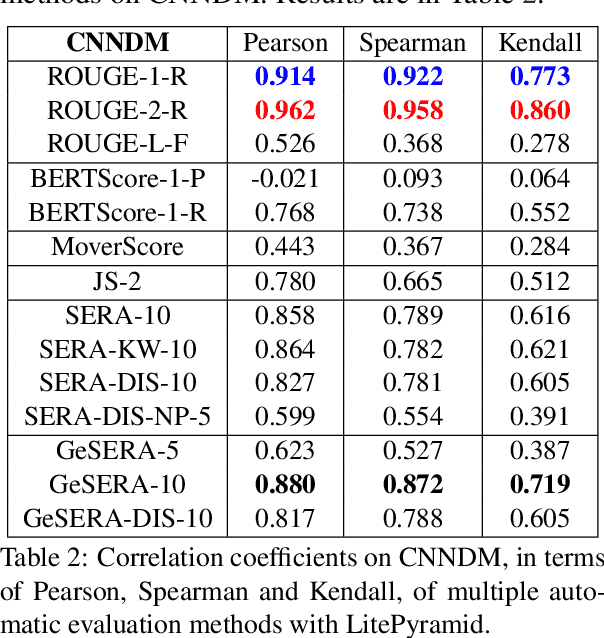
We present GeSERA, an open-source improved version of SERA for evaluating automatic extractive and abstractive summaries from the general domain. SERA is based on a search engine that compares candidate and reference summaries (called queries) against an information retrieval document base (called index). SERA was originally designed for the biomedical domain only, where it showed a better correlation with manual methods than the widely used lexical-based ROUGE method. In this paper, we take out SERA from the biomedical domain to the general one by adapting its content-based method to successfully evaluate summaries from the general domain. First, we improve the query reformulation strategy with POS Tags analysis of general-domain corpora. Second, we replace the biomedical index used in SERA with two article collections from AQUAINT-2 and Wikipedia. We conduct experiments with TAC2008, TAC2009, and CNNDM datasets. Results show that, in most cases, GeSERA achieves higher correlations with manual evaluation methods than SERA, while it reduces its gap with ROUGE for general-domain summary evaluation. GeSERA even surpasses ROUGE in two cases of TAC2009. Finally, we conduct extensive experiments and provide a comprehensive study of the impact of human annotators and the index size on summary evaluation with SERA and GeSERA.
Semantic Similarity To Improve Question Understanding in a Virtual Patient
Dec 16, 2019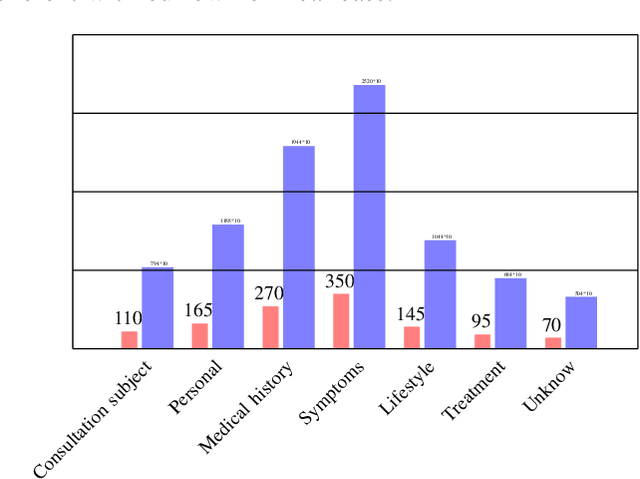
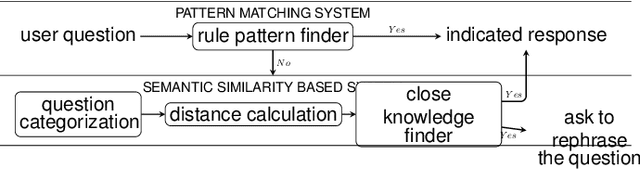

In medicine, a communicating virtual patient or doctor allows students to train in medical diagnosis and develop skills to conduct a medical consultation. In this paper, we describe a conversational virtual standardized patient system to allow medical students to simulate a diagnosis strategy of an abdominal surgical emergency. We exploited the semantic properties captured by distributed word representations to search for similar questions in the virtual patient dialogue system. We created two dialogue systems that were evaluated on datasets collected during tests with students. The first system based on hand-crafted rules obtains $92.29\%$ as $F1$-score on the studied clinical case while the second system that combines rules and semantic similarity achieves $94.88\%$. It represents an error reduction of $9.70\%$ as compared to the rules-only-based system.