 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScience Checker Reloaded: A Bidirectional Paradigm for Transparency and Logical Reasoning
Feb 21, 2024Information retrieval is a rapidly evolving field. However it still faces significant limitations in the scientific and industrial vast amounts of information, such as semantic divergence and vocabulary gaps in sparse retrieval, low precision and lack of interpretability in semantic search, or hallucination and outdated information in generative models. In this paper, we introduce a two-block approach to tackle these hurdles for long documents. The first block enhances language understanding in sparse retrieval by query expansion to retrieve relevant documents. The second block deepens the result by providing comprehensive and informative answers to the complex question using only the information spread in the long document, enabling bidirectional engagement. At various stages of the pipeline, intermediate results are presented to users to facilitate understanding of the system's reasoning. We believe this bidirectional approach brings significant advancements in terms of transparency, logical thinking, and comprehensive understanding in the field of scientific information retrieval.
Attention-Based Recurrent Neural Network For Automatic Behavior Laying Hen Recognition
Jan 18, 2024One of the interests of modern poultry farming is the vocalization of laying hens which contain very useful information on health behavior. This information is used as health and well-being indicators that help breeders better monitor laying hens, which involves early detection of problems for rapid and more effective intervention. In this work, we focus on the sound analysis for the recognition of the types of calls of the laying hens in order to propose a robust system of characterization of their behavior for a better monitoring. To do this, we first collected and annotated laying hen call signals, then designed an optimal acoustic characterization based on the combination of time and frequency domain features. We then used these features to build the multi-label classification models based on recurrent neural network to assign a semantic class to the vocalization that characterize the laying hen behavior. The results show an overall performance with our model based on the combination of time and frequency domain features that obtained the highest F1-score (F1=92.75) with a gain of 17% on the models using the frequency domain features and of 8% on the compared approaches from the litterature.
Leveraging Knowledge Graph Embeddings to Enhance Contextual Representations for Relation Extraction
Jun 07, 2023Relation extraction task is a crucial and challenging aspect of Natural Language Processing. Several methods have surfaced as of late, exhibiting notable performance in addressing the task; however, most of these approaches rely on vast amounts of data from large-scale knowledge graphs or language models pretrained on voluminous corpora. In this paper, we hone in on the effective utilization of solely the knowledge supplied by a corpus to create a high-performing model. Our objective is to showcase that by leveraging the hierarchical structure and relational distribution of entities within a corpus without introducing external knowledge, a relation extraction model can achieve significantly enhanced performance. We therefore proposed a relation extraction approach based on the incorporation of pretrained knowledge graph embeddings at the corpus scale into the sentence-level contextual representation. We conducted a series of experiments which revealed promising and very interesting results for our proposed approach.The obtained results demonstrated an outperformance of our method compared to context-based relation extraction models.
Semantic Similarity To Improve Question Understanding in a Virtual Patient
Dec 16, 2019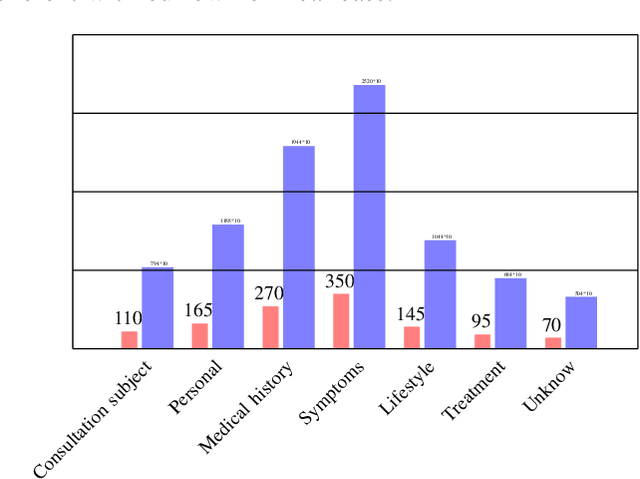
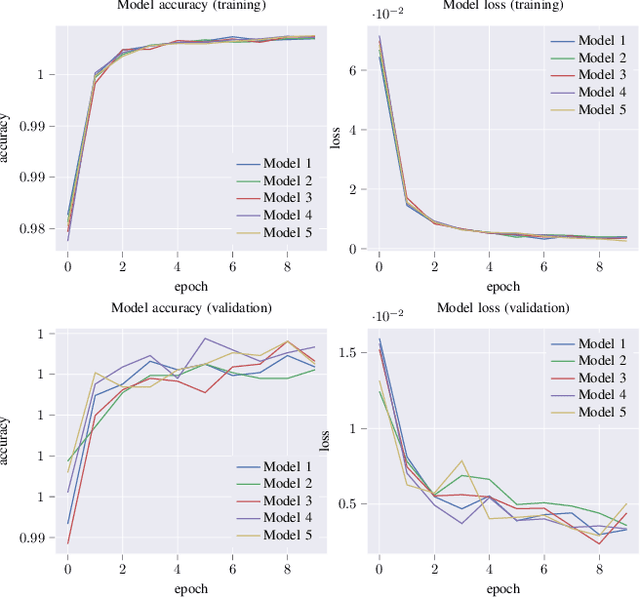
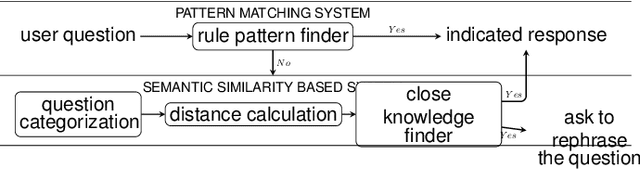

In medicine, a communicating virtual patient or doctor allows students to train in medical diagnosis and develop skills to conduct a medical consultation. In this paper, we describe a conversational virtual standardized patient system to allow medical students to simulate a diagnosis strategy of an abdominal surgical emergency. We exploited the semantic properties captured by distributed word representations to search for similar questions in the virtual patient dialogue system. We created two dialogue systems that were evaluated on datasets collected during tests with students. The first system based on hand-crafted rules obtains $92.29\%$ as $F1$-score on the studied clinical case while the second system that combines rules and semantic similarity achieves $94.88\%$. It represents an error reduction of $9.70\%$ as compared to the rules-only-based system.