 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Sentence Representation with Variational Autoencoders and Attention
May 04, 2023In this thesis, we develop methods to enhance the interpretability of recent representation learning techniques in natural language processing (NLP) while accounting for the unavailability of annotated data. We choose to leverage Variational Autoencoders (VAEs) due to their efficiency in relating observations to latent generative factors and their effectiveness in data-efficient learning and interpretable representation learning. As a first contribution, we identify and remove unnecessary components in the functioning scheme of semi-supervised VAEs making them faster, smaller and easier to design. Our second and main contribution is to use VAEs and Transformers to build two models with inductive bias to separate information in latent representations into understandable concepts without annotated data. The first model, Attention-Driven VAE (ADVAE), is able to separately represent and control information about syntactic roles in sentences. The second model, QKVAE, uses separate latent variables to form keys and values for its Transformer decoder and is able to separate syntactic and semantic information in its neural representations. In transfer experiments, QKVAE has competitive performance compared to supervised models and equivalent performance to a supervised model using 50K annotated samples. Additionally, QKVAE displays improved syntactic role disentanglement capabilities compared to ADVAE. Overall, we demonstrate that it is possible to enhance the interpretability of state-of-the-art deep learning architectures for language modeling with unannotated data in situations where text data is abundant but annotations are scarce.
Towards Unsupervised Content Disentanglement in Sentence Representations via Syntactic Roles
Jun 22, 2022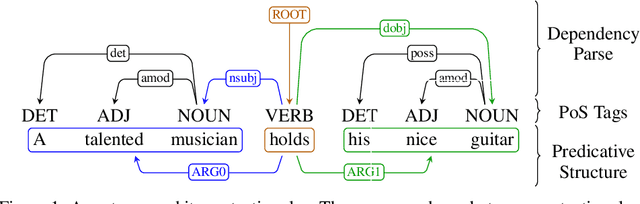
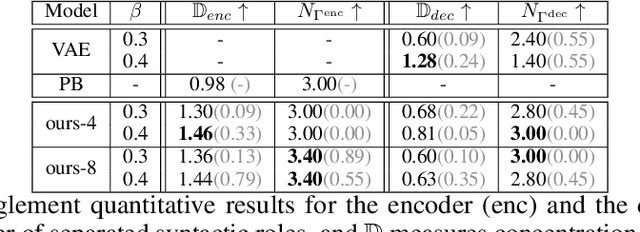
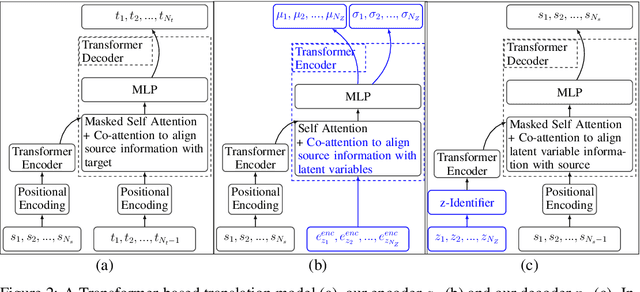
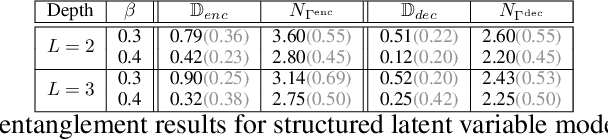
Linking neural representations to linguistic factors is crucial in order to build and analyze NLP models interpretable by humans. Among these factors, syntactic roles (e.g. subjects, direct objects,$\dots$) and their realizations are essential markers since they can be understood as a decomposition of predicative structures and thus the meaning of sentences. Starting from a deep probabilistic generative model with attention, we measure the interaction between latent variables and realizations of syntactic roles and show that it is possible to obtain, without supervision, representations of sentences where different syntactic roles correspond to clearly identified different latent variables. The probabilistic model we propose is an Attention-Driven Variational Autoencoder (ADVAE). Drawing inspiration from Transformer-based machine translation models, ADVAEs enable the analysis of the interactions between latent variables and input tokens through attention. We also develop an evaluation protocol to measure disentanglement with regard to the realizations of syntactic roles. This protocol is based on attention maxima for the encoder and on latent variable perturbations for the decoder. Our experiments on raw English text from the SNLI dataset show that $\textit{i)}$ disentanglement of syntactic roles can be induced without supervision, $\textit{ii)}$ ADVAE separates syntactic roles better than classical sequence VAEs and Transformer VAEs, $\textit{iii)}$ realizations of syntactic roles can be separately modified in sentences by mere intervention on the associated latent variables. Our work constitutes a first step towards unsupervised controllable content generation. The code for our work is publicly available.
Exploiting Inductive Bias in Transformers for Unsupervised Disentanglement of Syntax and Semantics with VAEs
May 19, 2022
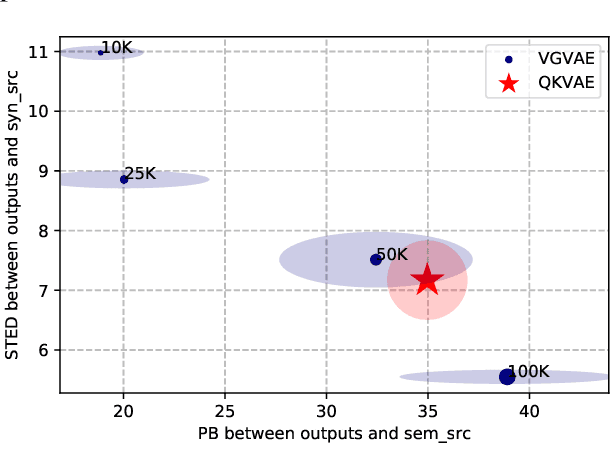
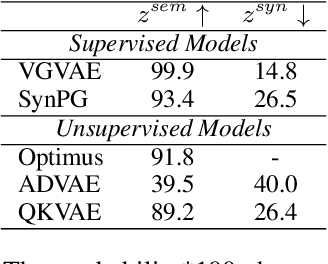
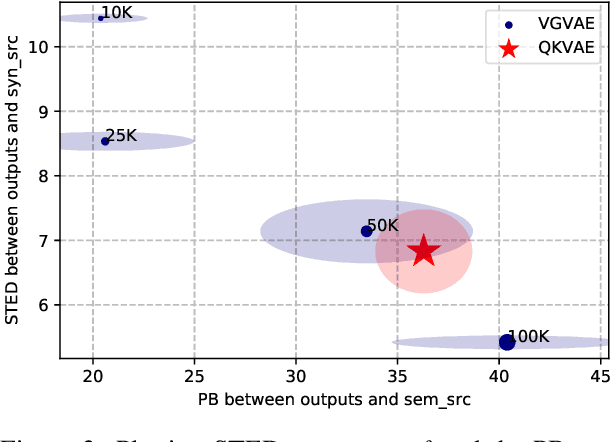
We propose a generative model for text generation, which exhibits disentangled latent representations of syntax and semantics. Contrary to previous work, this model does not need syntactic information such as constituency parses, or semantic information such as paraphrase pairs. Our model relies solely on the inductive bias found in attention-based architectures such as Transformers. In the attention of Transformers, keys handle information selection while values specify what information is conveyed. Our model, dubbed QKVAE, uses Attention in its decoder to read latent variables where one latent variable infers keys while another infers values. We run experiments on latent representations and experiments on syntax/semantics transfer which show that QKVAE displays clear signs of disentangled syntax and semantics. We also show that our model displays competitive syntax transfer capabilities when compared to supervised models and that comparable supervised models need a fairly large amount of data (more than 50K samples) to outperform it on both syntactic and semantic transfer. The code for our experiments is publicly available.
Challenging the Semi-Supervised VAE Framework for Text Classification
Sep 27, 2021
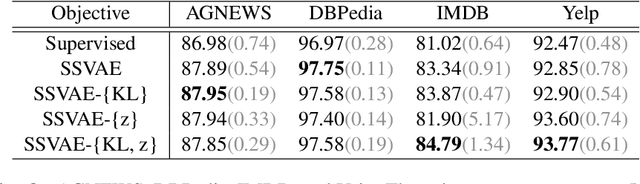


Semi-Supervised Variational Autoencoders (SSVAEs) are widely used models for data efficient learning. In this paper, we question the adequacy of the standard design of sequence SSVAEs for the task of text classification as we exhibit two sources of overcomplexity for which we provide simplifications. These simplifications to SSVAEs preserve their theoretical soundness while providing a number of practical advantages in the semi-supervised setup where the result of training is a text classifier. These simplifications are the removal of (i) the Kullback-Liebler divergence from its objective and (ii) the fully unobserved latent variable from its probabilistic model. These changes relieve users from choosing a prior for their latent variables, make the model smaller and faster, and allow for a better flow of information into the latent variables. We compare the simplified versions to standard SSVAEs on 4 text classification tasks. On top of the above-mentioned simplification, experiments show a speed-up of 26%, while keeping equivalent classification scores. The code to reproduce our experiments is public.
Disentangling semantics in language through VAEs and a certain architectural choice
Dec 28, 2020
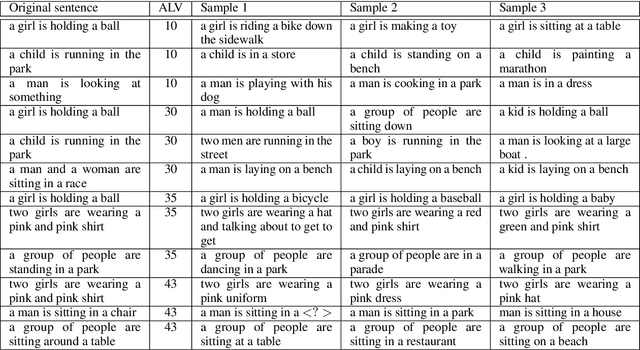
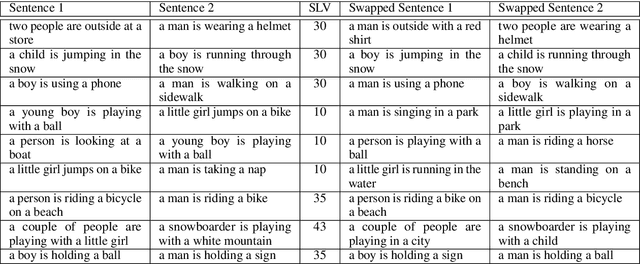
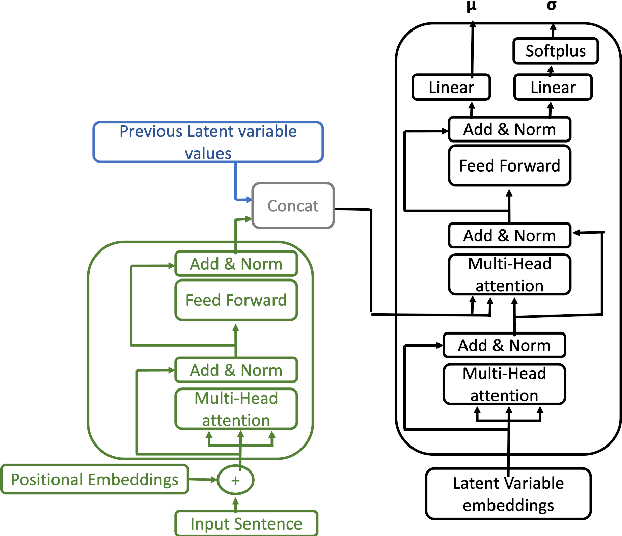
We present an unsupervised method to obtain disentangled representations of sentences that single out semantic content. Using modified Transformers as building blocks, we train a Variational Autoencoder to translate the sentence to a fixed number of hierarchically structured latent variables. We study the influence of each latent variable in generation on the dependency structure of sentences, and on the predicate structure it yields when passed through an Open Information Extraction model. Our model could separate verbs, subjects, direct objects, and prepositional objects into latent variables we identified. We show that varying the corresponding latent variables results in varying these elements in sentences, and that swapping them between couples of sentences leads to the expected partial semantic swap.
Controlling the Interaction Between Generation and Inference in Semi-Supervised Variational Autoencoders Using Importance Weighting
Oct 14, 2020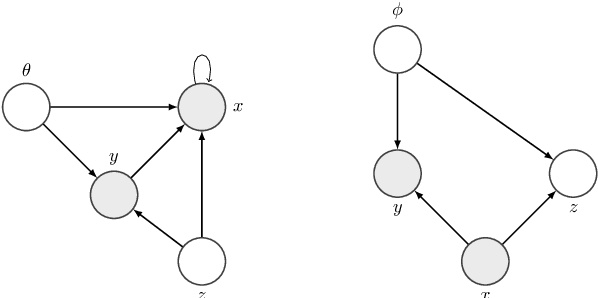
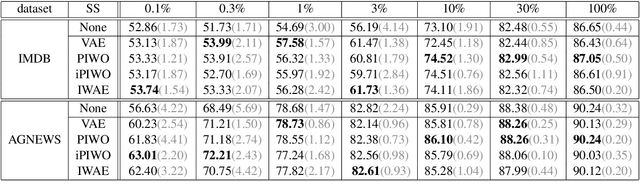
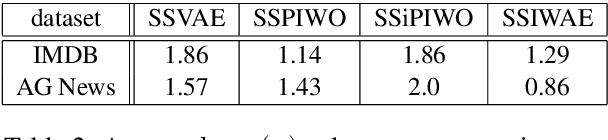
Even though Variational Autoencoders (VAEs) are widely used for semi-supervised learning, the reason why they work remains unclear. In fact, the addition of the unsupervised objective is most often vaguely described as a regularization. The strength of this regularization is controlled by down-weighting the objective on the unlabeled part of the training set. Through an analysis of the objective of semi-supervised VAEs, we observe that they use the posterior of the learned generative model to guide the inference model in learning the partially observed latent variable. We show that given this observation, it is possible to gain finer control on the effect of the unsupervised objective on the training procedure. Using importance weighting, we derive two novel objectives that prioritize either one of the partially observed latent variable, or the unobserved latent variable. Experiments on the IMDB english sentiment analysis dataset and on the AG News topic classification dataset show the improvements brought by our prioritization mechanism and exhibit a behavior that is inline with our description of the inner working of Semi-Supervised VAEs.
Slices of Attention in Asynchronous Video Job Interviews
Sep 19, 2019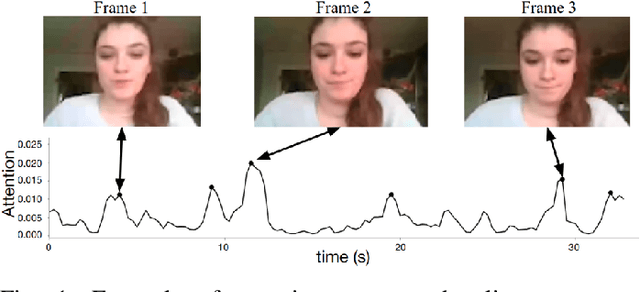


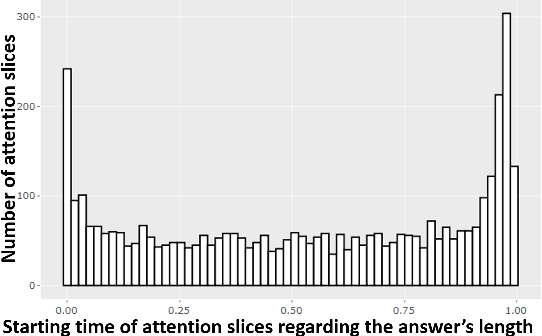
The impact of non verbal behaviour in a hiring decision remains an open question. Investigating this question is important, as it could provide a better understanding on how to train candidates for job interviews and make recruiters be aware of influential non verbal behaviour. This research has recently been accelerated due to the development of tools for the automatic analysis of social signals, and the emergence of machine learning methods. However, these studies are still mainly based on hand engineered features, which imposes a limit to the discovery of influential social signals. On the other side, deep learning methods are a promising tool to discover complex patterns without the necessity of feature engineering. In this paper, we focus on studying influential non verbal social signals in asynchronous job video interviews that are discovered by deep learning methods. We use a previously published deep learning system that aims at inferring the hirability of a candidate with regard to a sequence of interview questions. One particularity of this system is the use of attention mechanisms, which aim at identifying the relevant parts of an answer. Thus, information at a fine-grained temporal level could be extracted using global (at the interview level) annotations on hirability. While most of the deep learning systems use attention mechanisms to offer a quick visualization of slices when a rise of attention occurs, we perform an in-depth analysis to understand what happens during these moments. First, we propose a methodology to automatically extract slices where there is a rise of attention (attention slices). Second, we study the content of attention slices by comparing them with randomly sampled slices. Finally, we show that they bear significantly more information for hirability than randomly sampled slices.
HireNet: a Hierarchical Attention Model for the Automatic Analysis of Asynchronous Video Job Interviews
Jul 25, 2019
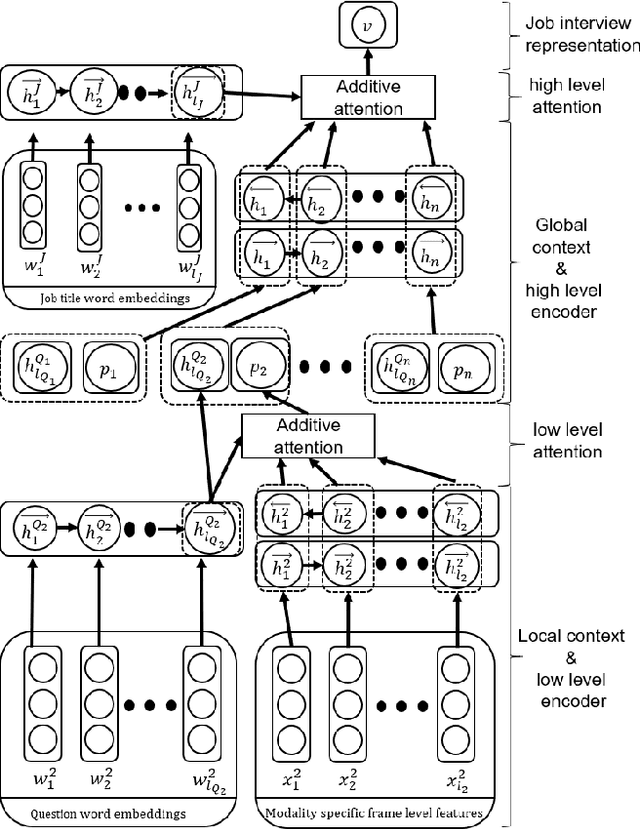


New technologies drastically change recruitment techniques. Some research projects aim at designing interactive systems that help candidates practice job interviews. Other studies aim at the automatic detection of social signals (e.g. smile, turn of speech, etc...) in videos of job interviews. These studies are limited with respect to the number of interviews they process, but also by the fact that they only analyze simulated job interviews (e.g. students pretending to apply for a fake position). Asynchronous video interviewing tools have become mature products on the human resources market, and thus, a popular step in the recruitment process. As part of a project to help recruiters, we collected a corpus of more than 7000 candidates having asynchronous video job interviews for real positions and recording videos of themselves answering a set of questions. We propose a new hierarchical attention model called HireNet that aims at predicting the hirability of the candidates as evaluated by recruiters. In HireNet, an interview is considered as a sequence of questions and answers containing salient socials signals. Two contextual sources of information are modeled in HireNet: the words contained in the question and in the job position. Our model achieves better F1-scores than previous approaches for each modality (verbal content, audio and video). Results from early and late multimodal fusion suggest that more sophisticated fusion schemes are needed to improve on the monomodal results. Finally, some examples of moments captured by the attention mechanisms suggest our model could potentially be used to help finding key moments in an asynchronous job interview.
* AAAI 2019