 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Judge Me by My Face : An Indirect Adversarial Approach to Remove Sensitive Information From Multimodal Neural Representation in Asynchronous Job Video Interviews
Oct 18, 2021



se of machine learning for automatic analysis of job interview videos has recently seen increased interest. Despite claims of fair output regarding sensitive information such as gender or ethnicity of the candidates, the current approaches rarely provide proof of unbiased decision-making, or that sensitive information is not used. Recently, adversarial methods have been proved to effectively remove sensitive information from the latent representation of neural networks. However, these methods rely on the use of explicitly labeled protected variables (e.g. gender), which cannot be collected in the context of recruiting in some countries (e.g. France). In this article, we propose a new adversarial approach to remove sensitive information from the latent representation of neural networks without the need to collect any sensitive variable. Using only a few frames of the interview, we train our model to not be able to find the face of the candidate related to the job interview in the inner layers of the model. This, in turn, allows us to remove relevant private information from these layers. Comparing our approach to a standard baseline on a public dataset with gender and ethnicity annotations, we show that it effectively removes sensitive information from the main network. Moreover, to the best of our knowledge, this is the first application of adversarial techniques for obtaining a multimodal fair representation in the context of video job interviews. In summary, our contributions aim at improving fairness of the upcoming automatic systems processing videos of job interviews for equality in job selection.
Slices of Attention in Asynchronous Video Job Interviews
Sep 19, 2019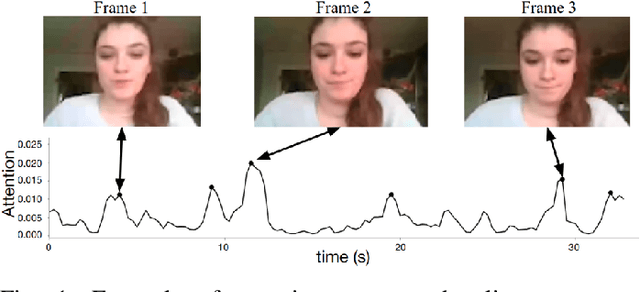


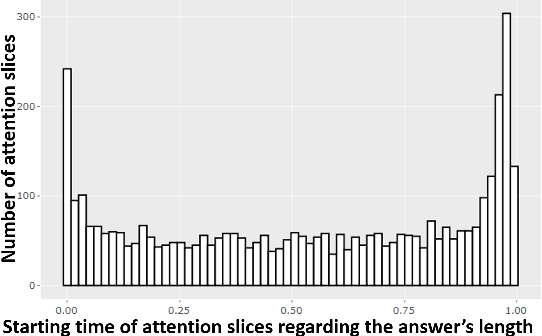
The impact of non verbal behaviour in a hiring decision remains an open question. Investigating this question is important, as it could provide a better understanding on how to train candidates for job interviews and make recruiters be aware of influential non verbal behaviour. This research has recently been accelerated due to the development of tools for the automatic analysis of social signals, and the emergence of machine learning methods. However, these studies are still mainly based on hand engineered features, which imposes a limit to the discovery of influential social signals. On the other side, deep learning methods are a promising tool to discover complex patterns without the necessity of feature engineering. In this paper, we focus on studying influential non verbal social signals in asynchronous job video interviews that are discovered by deep learning methods. We use a previously published deep learning system that aims at inferring the hirability of a candidate with regard to a sequence of interview questions. One particularity of this system is the use of attention mechanisms, which aim at identifying the relevant parts of an answer. Thus, information at a fine-grained temporal level could be extracted using global (at the interview level) annotations on hirability. While most of the deep learning systems use attention mechanisms to offer a quick visualization of slices when a rise of attention occurs, we perform an in-depth analysis to understand what happens during these moments. First, we propose a methodology to automatically extract slices where there is a rise of attention (attention slices). Second, we study the content of attention slices by comparing them with randomly sampled slices. Finally, we show that they bear significantly more information for hirability than randomly sampled slices.
HireNet: a Hierarchical Attention Model for the Automatic Analysis of Asynchronous Video Job Interviews
Jul 25, 2019
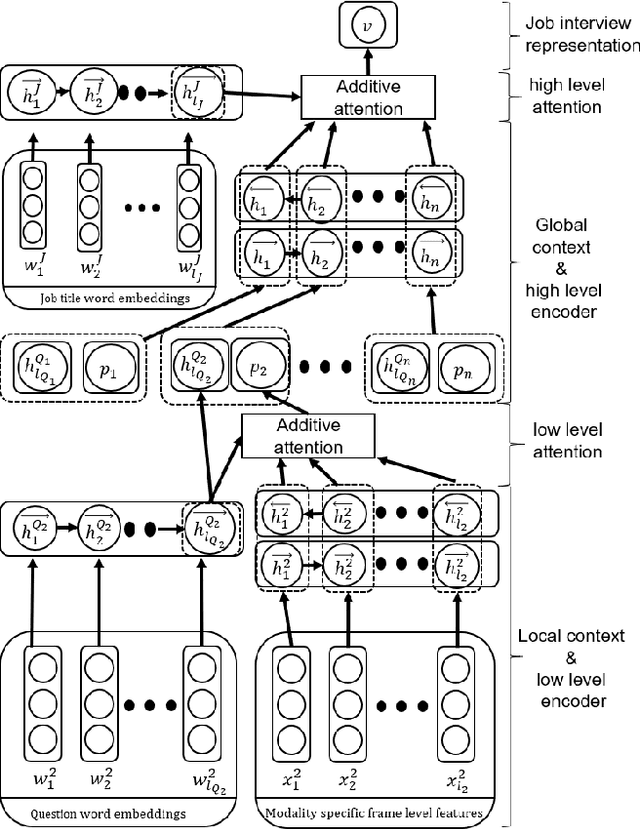


New technologies drastically change recruitment techniques. Some research projects aim at designing interactive systems that help candidates practice job interviews. Other studies aim at the automatic detection of social signals (e.g. smile, turn of speech, etc...) in videos of job interviews. These studies are limited with respect to the number of interviews they process, but also by the fact that they only analyze simulated job interviews (e.g. students pretending to apply for a fake position). Asynchronous video interviewing tools have become mature products on the human resources market, and thus, a popular step in the recruitment process. As part of a project to help recruiters, we collected a corpus of more than 7000 candidates having asynchronous video job interviews for real positions and recording videos of themselves answering a set of questions. We propose a new hierarchical attention model called HireNet that aims at predicting the hirability of the candidates as evaluated by recruiters. In HireNet, an interview is considered as a sequence of questions and answers containing salient socials signals. Two contextual sources of information are modeled in HireNet: the words contained in the question and in the job position. Our model achieves better F1-scores than previous approaches for each modality (verbal content, audio and video). Results from early and late multimodal fusion suggest that more sophisticated fusion schemes are needed to improve on the monomodal results. Finally, some examples of moments captured by the attention mechanisms suggest our model could potentially be used to help finding key moments in an asynchronous job interview.
* AAAI 2019