 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHireNet: a Hierarchical Attention Model for the Automatic Analysis of Asynchronous Video Job Interviews
Jul 25, 2019
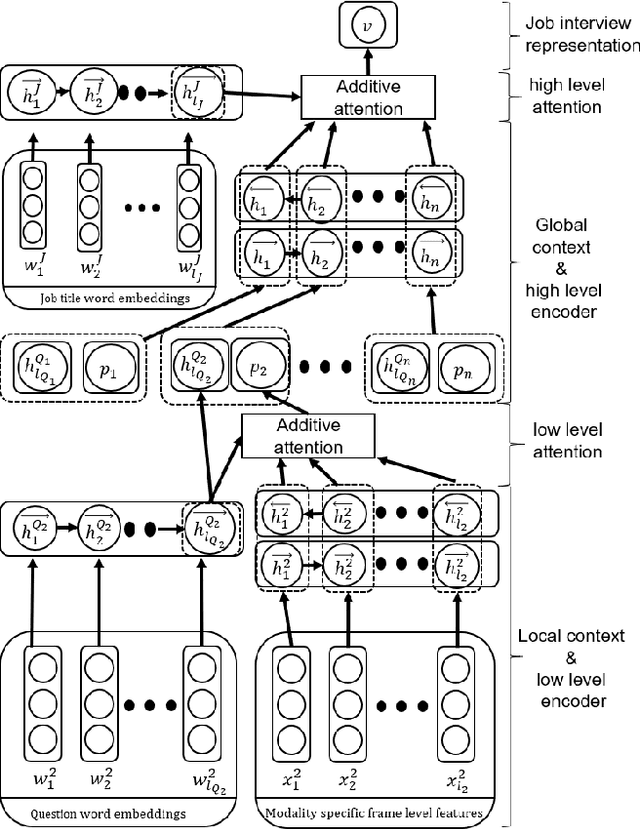


New technologies drastically change recruitment techniques. Some research projects aim at designing interactive systems that help candidates practice job interviews. Other studies aim at the automatic detection of social signals (e.g. smile, turn of speech, etc...) in videos of job interviews. These studies are limited with respect to the number of interviews they process, but also by the fact that they only analyze simulated job interviews (e.g. students pretending to apply for a fake position). Asynchronous video interviewing tools have become mature products on the human resources market, and thus, a popular step in the recruitment process. As part of a project to help recruiters, we collected a corpus of more than 7000 candidates having asynchronous video job interviews for real positions and recording videos of themselves answering a set of questions. We propose a new hierarchical attention model called HireNet that aims at predicting the hirability of the candidates as evaluated by recruiters. In HireNet, an interview is considered as a sequence of questions and answers containing salient socials signals. Two contextual sources of information are modeled in HireNet: the words contained in the question and in the job position. Our model achieves better F1-scores than previous approaches for each modality (verbal content, audio and video). Results from early and late multimodal fusion suggest that more sophisticated fusion schemes are needed to improve on the monomodal results. Finally, some examples of moments captured by the attention mechanisms suggest our model could potentially be used to help finding key moments in an asynchronous job interview.
* AAAI 2019