 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond a Single Explanation of the Adam--SGD Gap
Jun 12, 2026Prior work has identified several factors that can contribute to the performance gap between Adam and SGD, spanning data aspects, architecture design, and optimization properties. Yet these explanations are often studied in isolation, leaving their relative importance unclear. In this work, we revisit these hypotheses through a controlled empirical study across vision, language, genomics, and graph tasks, spanning modern and classical architectures, and carefully designed training setups. Our results suggest that no single factor consistently explains the Adam--SGD gap. For instance, the Adam advantage can (1) persist under a uniform vocabulary distribution yet nearly disappear under a heavy-tailed one; (2) reverse in favor of SGD in softmax-attention models; and (3) become larger under soft architectural modifications, e.g., when ReLU is replaced by a GeLU nonlinearity. This suggests that the gap arises from nontrivial data and architecture interactions, rather than from a single common factor. Yet, we observe a pattern across our settings: a \emph{crossover batch size} at which the relative advantage shifts from SGD to Adam as the batch size scales. These empirical results are captured by our theoretical gap model, which predicts this batch-size-dependent crossover. Our perspective helps reconcile several existing hypotheses while offering practical insights across domains.
Malicious Repurposing of Open Science Artefacts by Using Large Language Models
Jan 26, 2026The rapid evolution of large language models (LLMs) has fuelled enthusiasm about their role in advancing scientific discovery, with studies exploring LLMs that autonomously generate and evaluate novel research ideas. However, little attention has been given to the possibility that such models could be exploited to produce harmful research by repurposing open science artefacts for malicious ends. We fill the gap by introducing an end-to-end pipeline that first bypasses LLM safeguards through persuasion-based jailbreaking, then reinterprets NLP papers to identify and repurpose their artefacts (datasets, methods, and tools) by exploiting their vulnerabilities, and finally assesses the safety of these proposals using our evaluation framework across three dimensions: harmfulness, feasibility of misuse, and soundness of technicality. Overall, our findings demonstrate that LLMs can generate harmful proposals by repurposing ethically designed open artefacts; however, we find that LLMs acting as evaluators strongly disagree with one another on evaluation outcomes: GPT-4.1 assigns higher scores (indicating greater potential harms, higher soundness and feasibility of misuse), Gemini-2.5-pro is markedly stricter, and Grok-3 falls between these extremes. This indicates that LLMs cannot yet serve as reliable judges in a malicious evaluation setup, making human evaluation essential for credible dual-use risk assessment.
Bits for Privacy: Evaluating Post-Training Quantization via Membership Inference
Dec 17, 2025Deep neural networks are widely deployed with quantization techniques to reduce memory and computational costs by lowering the numerical precision of their parameters. While quantization alters model parameters and their outputs, existing privacy analyses primarily focus on full-precision models, leaving a gap in understanding how bit-width reduction can affect privacy leakage. We present the first systematic study of the privacy-utility relationship in post-training quantization (PTQ), a versatile family of methods that can be applied to pretrained models without further training. Using membership inference attacks as our evaluation framework, we analyze three popular PTQ algorithms-AdaRound, BRECQ, and OBC-across multiple precision levels (4-bit, 2-bit, and 1.58-bit) on CIFAR-10, CIFAR-100, and TinyImageNet datasets. Our findings consistently show that low-precision PTQs can reduce privacy leakage. In particular, lower-precision models demonstrate up to an order of magnitude reduction in membership inference vulnerability compared to their full-precision counterparts, albeit at the cost of decreased utility. Additional ablation studies on the 1.58-bit quantization level show that quantizing only the last layer at higher precision enables fine-grained control over the privacy-utility trade-off. These results offer actionable insights for practitioners to balance efficiency, utility, and privacy protection in real-world deployments.
How does the optimizer implicitly bias the model merging loss landscape?
Oct 06, 2025Model merging methods combine models with different capabilities into a single one while maintaining the same inference cost. Two popular approaches are linear interpolation, which linearly interpolates between model weights, and task arithmetic, which combines task vectors obtained by the difference between finetuned and base models. While useful in practice, what properties make merging effective are poorly understood. This paper explores how the optimization process affects the loss landscape geometry and its impact on merging success. We show that a single quantity -- the effective noise scale -- unifies the impact of optimizer and data choices on model merging. Across architectures and datasets, the effectiveness of merging success is a non-monotonic function of effective noise, with a distinct optimum. Decomposing this quantity, we find that larger learning rates, stronger weight decay, smaller batch sizes, and data augmentation all independently modulate the effective noise scale, exhibiting the same qualitative trend. Unlike prior work that connects optimizer noise to the flatness or generalization of individual minima, we show that it also affects the global loss landscape, predicting when independently trained solutions can be merged. Our findings broaden the understanding of how optimization shapes the loss landscape geometry and its downstream consequences for model merging, suggesting the possibility of further manipulating the training dynamics to improve merging effectiveness.
Spurious Privacy Leakage in Neural Networks
May 26, 2025Neural networks are vulnerable to privacy attacks aimed at stealing sensitive data. The risks can be amplified in a real-world scenario, particularly when models are trained on limited and biased data. In this work, we investigate the impact of spurious correlation bias on privacy vulnerability. We introduce \emph{spurious privacy leakage}, a phenomenon where spurious groups are significantly more vulnerable to privacy attacks than non-spurious groups. We further show that group privacy disparity increases in tasks with simpler objectives (e.g. fewer classes) due to the persistence of spurious features. Surprisingly, we find that reducing spurious correlation using spurious robust methods does not mitigate spurious privacy leakage. This leads us to introduce a perspective on privacy disparity based on memorization, where mitigating spurious correlation does not mitigate the memorization of spurious data, and therefore, neither the privacy level. Lastly, we compare the privacy of different model architectures trained with spurious data, demonstrating that, contrary to prior works, architectural choice can affect privacy outcomes.
Efficient Data Selection for Training Genomic Perturbation Models
Mar 18, 2025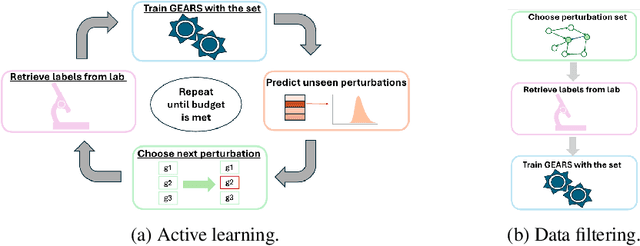
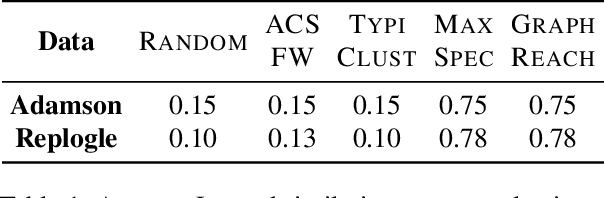
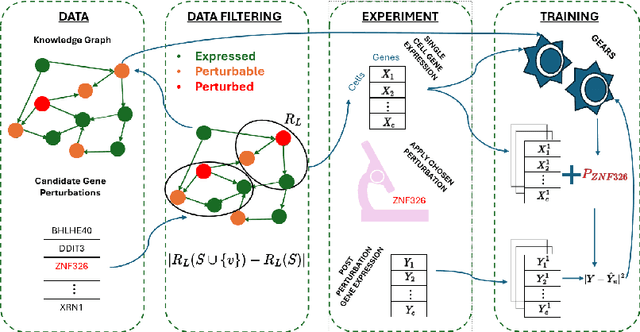
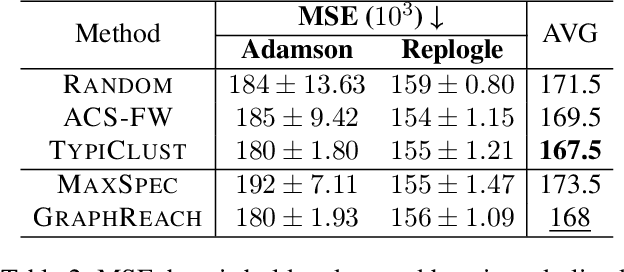
Genomic studies, including CRISPR-based PerturbSeq analyses, face a vast hypothesis space, while gene perturbations remain costly and time-consuming. Gene expression models based on graph neural networks are trained to predict the outcomes of gene perturbations to facilitate such experiments. Active learning methods are often employed to train these models due to the cost of the genomic experiments required to build the training set. However, poor model initialization in active learning can result in suboptimal early selections, wasting time and valuable resources. While typical active learning mitigates this issue over many iterations, the limited number of experimental cycles in genomic studies exacerbates the risk. To this end, we propose graph-based one-shot data selection methods for training gene expression models. Unlike active learning, one-shot data selection predefines the gene perturbations before training, hence removing the initialization bias. The data selection is motivated by theoretical studies of graph neural network generalization. The criteria are defined over the input graph and are optimized with submodular maximization. We compare them empirically to baselines and active learning methods that are state-of-the-art on this problem. The results demonstrate that graph-based one-shot data selection achieves comparable accuracy while alleviating the aforementioned risks.
From Centralized to Decentralized Federated Learning: Theoretical Insights, Privacy Preservation, and Robustness Challenges
Mar 10, 2025



Federated Learning (FL) enables collaborative learning without directly sharing individual's raw data. FL can be implemented in either a centralized (server-based) or decentralized (peer-to-peer) manner. In this survey, we present a novel perspective: the fundamental difference between centralized FL (CFL) and decentralized FL (DFL) is not merely the network topology, but the underlying training protocol: separate aggregation vs. joint optimization. We argue that this distinction in protocol leads to significant differences in model utility, privacy preservation, and robustness to attacks. We systematically review and categorize existing works in both CFL and DFL according to the type of protocol they employ. This taxonomy provides deeper insights into prior research and clarifies how various approaches relate or differ. Through our analysis, we identify key gaps in the literature. In particular, we observe a surprising lack of exploration of DFL approaches based on distributed optimization methods, despite their potential advantages. We highlight this under-explored direction and call for more research on leveraging distributed optimization for federated learning. Overall, this work offers a comprehensive overview from centralized to decentralized FL, sheds new light on the core distinctions between approaches, and outlines open challenges and future directions for the field.
Privacy-Preserving Distributed Maximum Consensus Without Accuracy Loss
Sep 16, 2024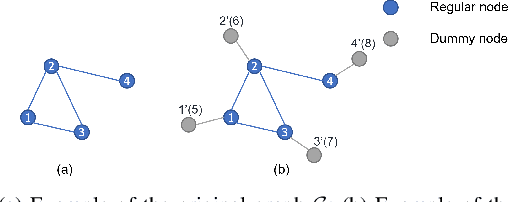
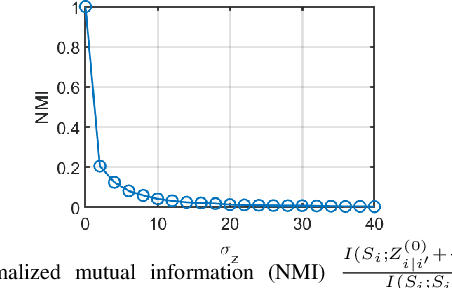
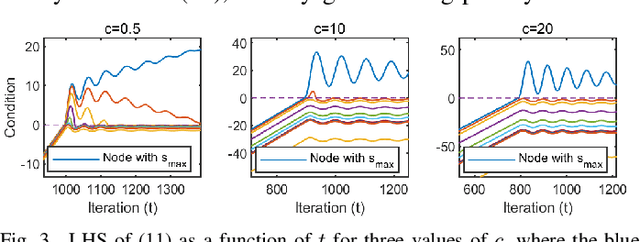
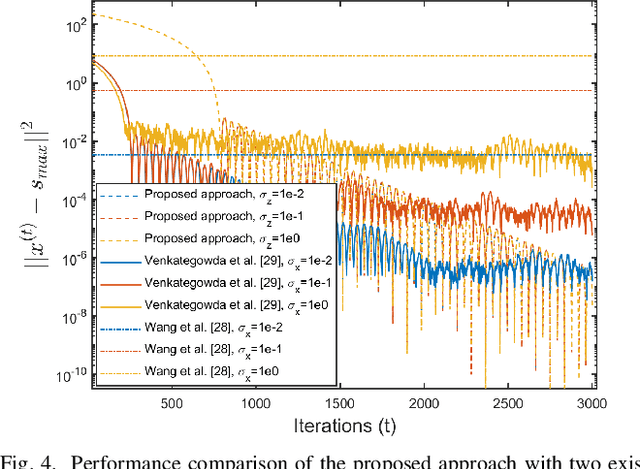
In distributed networks, calculating the maximum element is a fundamental task in data analysis, known as the distributed maximum consensus problem. However, the sensitive nature of the data involved makes privacy protection essential. Despite its importance, privacy in distributed maximum consensus has received limited attention in the literature. Traditional privacy-preserving methods typically add noise to updates, degrading the accuracy of the final result. To overcome these limitations, we propose a novel distributed optimization-based approach that preserves privacy without sacrificing accuracy. Our method introduces virtual nodes to form an augmented graph and leverages a carefully designed initialization process to ensure the privacy of honest participants, even when all their neighboring nodes are dishonest. Through a comprehensive information-theoretical analysis, we derive a sufficient condition to protect private data against both passive and eavesdropping adversaries. Extensive experiments validate the effectiveness of our approach, demonstrating that it not only preserves perfect privacy but also maintains accuracy, outperforming existing noise-based methods that typically suffer from accuracy loss.
KAGNNs: Kolmogorov-Arnold Networks meet Graph Learning
Jun 26, 2024



In recent years, Graph Neural Networks (GNNs) have become the de facto tool for learning node and graph representations. Most GNNs typically consist of a sequence of neighborhood aggregation (a.k.a., message passing) layers. Within each of these layers, the representation of each node is updated from an aggregation and transformation of its neighbours representations at the previous layer. The upper bound for the expressive power of message passing GNNs was reached through the use of MLPs as a transformation, due to their universal approximation capabilities. However, MLPs suffer from well-known limitations, which recently motivated the introduction of Kolmogorov-Arnold Networks (KANs). KANs rely on the Kolmogorov-Arnold representation theorem, rendering them a promising alternative to MLPs. In this work, we compare the performance of KANs against that of MLPs in graph learning tasks. We perform extensive experiments on node classification, graph classification and graph regression datasets. Our preliminary results indicate that while KANs are on-par with MLPs in classification tasks, they seem to have a clear advantage in the graph regression tasks.
Graph Neural Networks for Treatment Effect Prediction
Mar 28, 2024



Estimating causal effects in e-commerce tends to involve costly treatment assignments which can be impractical in large-scale settings. Leveraging machine learning to predict such treatment effects without actual intervention is a standard practice to diminish the risk. However, existing methods for treatment effect prediction tend to rely on training sets of substantial size, which are built from real experiments and are thus inherently risky to create. In this work we propose a graph neural network to diminish the required training set size, relying on graphs that are common in e-commerce data. Specifically, we view the problem as node regression with a restricted number of labeled instances, develop a two-model neural architecture akin to previous causal effect estimators, and test varying message-passing layers for encoding. Furthermore, as an extra step, we combine the model with an acquisition function to guide the creation of the training set in settings with extremely low experimental budget. The framework is flexible since each step can be used separately with other models or policies. The experiments on real large-scale networks indicate a clear advantage of our methodology over the state of the art, which in many cases performs close to random underlining the need for models that can generalize with limited labeled samples to reduce experimental risks.