 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePriSampler: Mitigating Property Inference of Diffusion Models
Jun 08, 2023
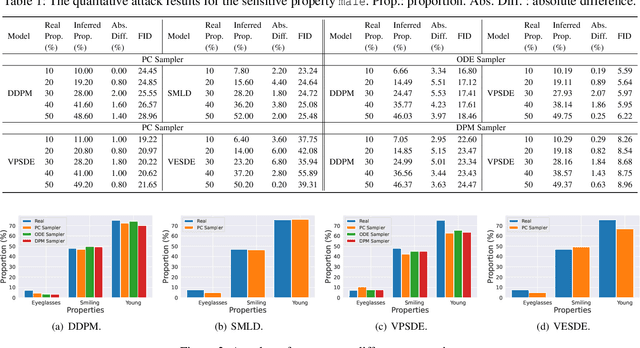


Diffusion models have been remarkably successful in data synthesis. Such successes have also driven diffusion models to apply to sensitive data, such as human face data, but this might bring about severe privacy concerns. In this work, we systematically present the first privacy study about property inference attacks against diffusion models, in which adversaries aim to extract sensitive global properties of the training set from a diffusion model, such as the proportion of the training data for certain sensitive properties. Specifically, we consider the most practical attack scenario: adversaries are only allowed to obtain synthetic data. Under this realistic scenario, we evaluate the property inference attacks on different types of samplers and diffusion models. A broad range of evaluations shows that various diffusion models and their samplers are all vulnerable to property inference attacks. Furthermore, one case study on off-the-shelf pre-trained diffusion models also demonstrates the effectiveness of the attack in practice. Finally, we propose a new model-agnostic plug-in method PriSampler to mitigate the property inference of diffusion models. PriSampler can be directly applied to well-trained diffusion models and support both stochastic and deterministic sampling. Extensive experiments illustrate the effectiveness of our defense and it makes adversaries infer the proportion of properties as close as random guesses. PriSampler also shows its significantly superior performance to diffusion models trained with differential privacy on both model utility and defense performance.
Ownership Protection of Generative Adversarial Networks
Jun 08, 2023Generative adversarial networks (GANs) have shown remarkable success in image synthesis, making GAN models themselves commercially valuable to legitimate model owners. Therefore, it is critical to technically protect the intellectual property of GANs. Prior works need to tamper with the training set or training process, and they are not robust to emerging model extraction attacks. In this paper, we propose a new ownership protection method based on the common characteristics of a target model and its stolen models. Our method can be directly applicable to all well-trained GANs as it does not require retraining target models. Extensive experimental results show that our new method can achieve the best protection performance, compared to the state-of-the-art methods. Finally, we demonstrate the effectiveness of our method with respect to the number of generations of model extraction attacks, the number of generated samples, different datasets, as well as adaptive attacks.
Membership Inference of Diffusion Models
Jan 24, 2023Recent years have witnessed the tremendous success of diffusion models in data synthesis. However, when diffusion models are applied to sensitive data, they also give rise to severe privacy concerns. In this paper, we systematically present the first study about membership inference attacks against diffusion models, which aims to infer whether a sample was used to train the model. Two attack methods are proposed, namely loss-based and likelihood-based attacks. Our attack methods are evaluated on several state-of-the-art diffusion models, over different datasets in relation to privacy-sensitive data. Extensive experimental evaluations show that our attacks can achieve remarkable performance. Furthermore, we exhaustively investigate various factors which can affect attack performance. Finally, we also evaluate the performance of our attack methods on diffusion models trained with differential privacy.
Model Extraction and Defenses on Generative Adversarial Networks
Jan 06, 2021



Model extraction attacks aim to duplicate a machine learning model through query access to a target model. Early studies mainly focus on discriminative models. Despite the success, model extraction attacks against generative models are less well explored. In this paper, we systematically study the feasibility of model extraction attacks against generative adversarial networks (GANs). Specifically, we first define accuracy and fidelity on model extraction attacks against GANs. Then we study model extraction attacks against GANs from the perspective of accuracy extraction and fidelity extraction, according to the adversary's goals and background knowledge. We further conduct a case study where an adversary can transfer knowledge of the extracted model which steals a state-of-the-art GAN trained with more than 3 million images to new domains to broaden the scope of applications of model extraction attacks. Finally, we propose effective defense techniques to safeguard GANs, considering a trade-off between the utility and security of GAN models.