 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Lightweight Library for Energy-Based Joint-Embedding Predictive Architectures
Feb 03, 2026We present EB-JEPA, an open-source library for learning representations and world models using Joint-Embedding Predictive Architectures (JEPAs). JEPAs learn to predict in representation space rather than pixel space, avoiding the pitfalls of generative modeling while capturing semantically meaningful features suitable for downstream tasks. Our library provides modular, self-contained implementations that illustrate how representation learning techniques developed for image-level self-supervised learning can transfer to video, where temporal dynamics add complexity, and ultimately to action-conditioned world models, where the model must additionally learn to predict the effects of control inputs. Each example is designed for single-GPU training within a few hours, making energy-based self-supervised learning accessible for research and education. We provide ablations of JEA components on CIFAR-10. Probing these representations yields 91% accuracy, indicating that the model learns useful features. Extending to video, we include a multi-step prediction example on Moving MNIST that demonstrates how the same principles scale to temporal modeling. Finally, we show how these representations can drive action-conditioned world models, achieving a 97% planning success rate on the Two Rooms navigation task. Comprehensive ablations reveal the critical importance of each regularization component for preventing representation collapse. Code is available at https://github.com/facebookresearch/eb_jepa.
Learning Latent Action World Models In The Wild
Jan 08, 2026Agents capable of reasoning and planning in the real world require the ability of predicting the consequences of their actions. While world models possess this capability, they most often require action labels, that can be complex to obtain at scale. This motivates the learning of latent action models, that can learn an action space from videos alone. Our work addresses the problem of learning latent actions world models on in-the-wild videos, expanding the scope of existing works that focus on simple robotics simulations, video games, or manipulation data. While this allows us to capture richer actions, it also introduces challenges stemming from the video diversity, such as environmental noise, or the lack of a common embodiment across videos. To address some of the challenges, we discuss properties that actions should follow as well as relevant architectural choices and evaluations. We find that continuous, but constrained, latent actions are able to capture the complexity of actions from in-the-wild videos, something that the common vector quantization does not. We for example find that changes in the environment coming from agents, such as humans entering the room, can be transferred across videos. This highlights the capability of learning actions that are specific to in-the-wild videos. In the absence of a common embodiment across videos, we are mainly able to learn latent actions that become localized in space, relative to the camera. Nonetheless, we are able to train a controller that maps known actions to latent ones, allowing us to use latent actions as a universal interface and solve planning tasks with our world model with similar performance as action-conditioned baselines. Our analyses and experiments provide a step towards scaling latent action models to the real world.
What Drives Success in Physical Planning with Joint-Embedding Predictive World Models?
Dec 30, 2025A long-standing challenge in AI is to develop agents capable of solving a wide range of physical tasks and generalizing to new, unseen tasks and environments. A popular recent approach involves training a world model from state-action trajectories and subsequently use it with a planning algorithm to solve new tasks. Planning is commonly performed in the input space, but a recent family of methods has introduced planning algorithms that optimize in the learned representation space of the world model, with the promise that abstracting irrelevant details yields more efficient planning. In this work, we characterize models from this family as JEPA-WMs and investigate the technical choices that make algorithms from this class work. We propose a comprehensive study of several key components with the objective of finding the optimal approach within the family. We conducted experiments using both simulated environments and real-world robotic data, and studied how the model architecture, the training objective, and the planning algorithm affect planning success. We combine our findings to propose a model that outperforms two established baselines, DINO-WM and V-JEPA-2-AC, in both navigation and manipulation tasks. Code, data and checkpoints are available at https://github.com/facebookresearch/jepa-wms.
Improving Molecular Modeling with Geometric GNNs: an Empirical Study
Jul 11, 2024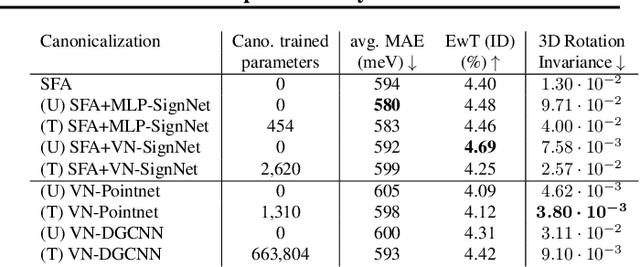

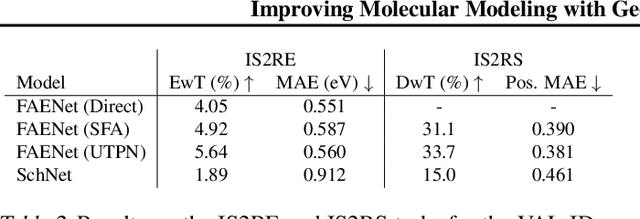

Rapid advancements in machine learning (ML) are transforming materials science by significantly speeding up material property calculations. However, the proliferation of ML approaches has made it challenging for scientists to keep up with the most promising techniques. This paper presents an empirical study on Geometric Graph Neural Networks for 3D atomic systems, focusing on the impact of different (1) canonicalization methods, (2) graph creation strategies, and (3) auxiliary tasks, on performance, scalability and symmetry enforcement. Our findings and insights aim to guide researchers in selecting optimal modeling components for molecular modeling tasks.