 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Lightweight Library for Energy-Based Joint-Embedding Predictive Architectures
Feb 03, 2026We present EB-JEPA, an open-source library for learning representations and world models using Joint-Embedding Predictive Architectures (JEPAs). JEPAs learn to predict in representation space rather than pixel space, avoiding the pitfalls of generative modeling while capturing semantically meaningful features suitable for downstream tasks. Our library provides modular, self-contained implementations that illustrate how representation learning techniques developed for image-level self-supervised learning can transfer to video, where temporal dynamics add complexity, and ultimately to action-conditioned world models, where the model must additionally learn to predict the effects of control inputs. Each example is designed for single-GPU training within a few hours, making energy-based self-supervised learning accessible for research and education. We provide ablations of JEA components on CIFAR-10. Probing these representations yields 91% accuracy, indicating that the model learns useful features. Extending to video, we include a multi-step prediction example on Moving MNIST that demonstrates how the same principles scale to temporal modeling. Finally, we show how these representations can drive action-conditioned world models, achieving a 97% planning success rate on the Two Rooms navigation task. Comprehensive ablations reveal the critical importance of each regularization component for preventing representation collapse. Code is available at https://github.com/facebookresearch/eb_jepa.
Learning from Reward-Free Offline Data: A Case for Planning with Latent Dynamics Models
Feb 20, 2025



A long-standing goal in AI is to build agents that can solve a variety of tasks across different environments, including previously unseen ones. Two dominant approaches tackle this challenge: (i) reinforcement learning (RL), which learns policies through trial and error, and (ii) optimal control, which plans actions using a learned or known dynamics model. However, their relative strengths and weaknesses remain underexplored in the setting where agents must learn from offline trajectories without reward annotations. In this work, we systematically analyze the performance of different RL and control-based methods under datasets of varying quality. On the RL side, we consider goal-conditioned and zero-shot approaches. On the control side, we train a latent dynamics model using the Joint Embedding Predictive Architecture (JEPA) and use it for planning. We study how dataset properties-such as data diversity, trajectory quality, and environment variability-affect the performance of these approaches. Our results show that model-free RL excels when abundant, high-quality data is available, while model-based planning excels in generalization to novel environment layouts, trajectory stitching, and data-efficiency. Notably, planning with a latent dynamics model emerges as a promising approach for zero-shot generalization from suboptimal data.
Light-weight probing of unsupervised representations for Reinforcement Learning
Aug 25, 2022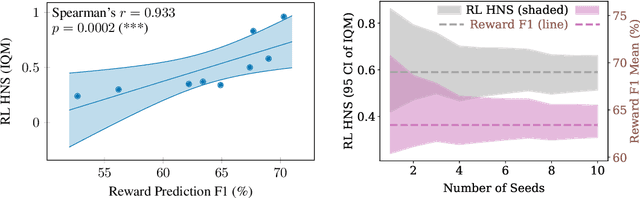
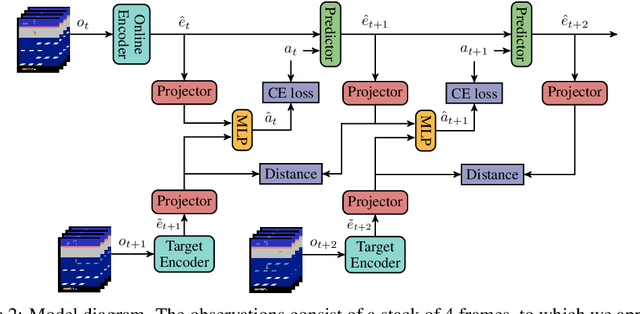
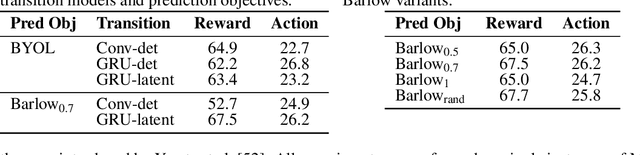

Unsupervised visual representation learning offers the opportunity to leverage large corpora of unlabeled trajectories to form useful visual representations, which can benefit the training of reinforcement learning (RL) algorithms. However, evaluating the fitness of such representations requires training RL algorithms which is computationally intensive and has high variance outcomes. To alleviate this issue, we design an evaluation protocol for unsupervised RL representations with lower variance and up to 600x lower computational cost. Inspired by the vision community, we propose two linear probing tasks: predicting the reward observed in a given state, and predicting the action of an expert in a given state. These two tasks are generally applicable to many RL domains, and we show through rigorous experimentation that they correlate strongly with the actual downstream control performance on the Atari100k Benchmark. This provides a better method for exploring the space of pretraining algorithms without the need of running RL evaluations for every setting. Leveraging this framework, we further improve existing self-supervised learning (SSL) recipes for RL, highlighting the importance of the forward model, the size of the visual backbone, and the precise formulation of the unsupervised objective.
MixUp Training Leads to Reduced Overfitting and Improved Calibration for the Transformer Architecture
Feb 22, 2021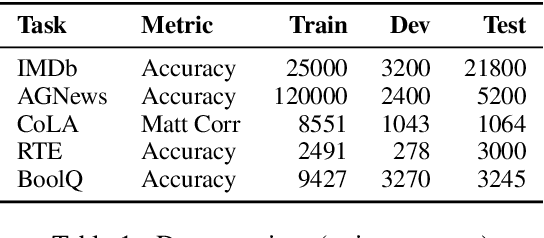
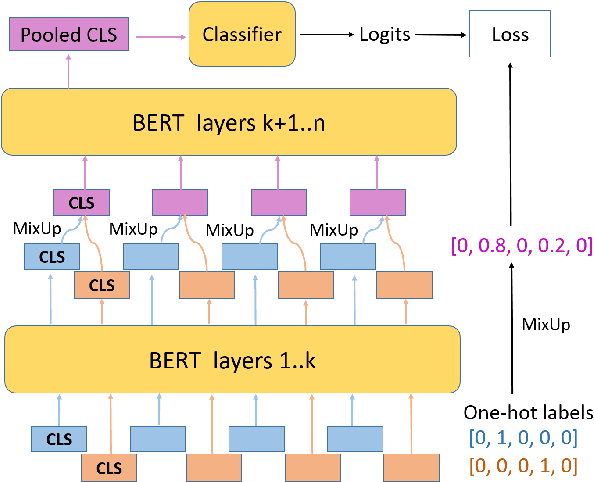
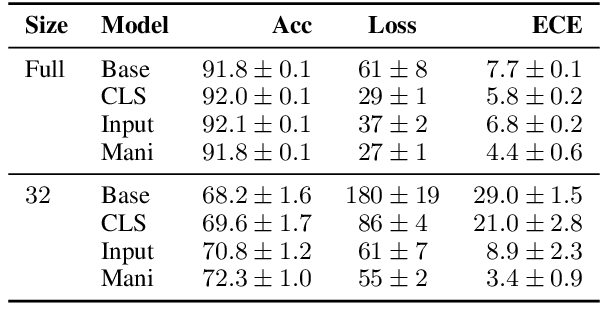
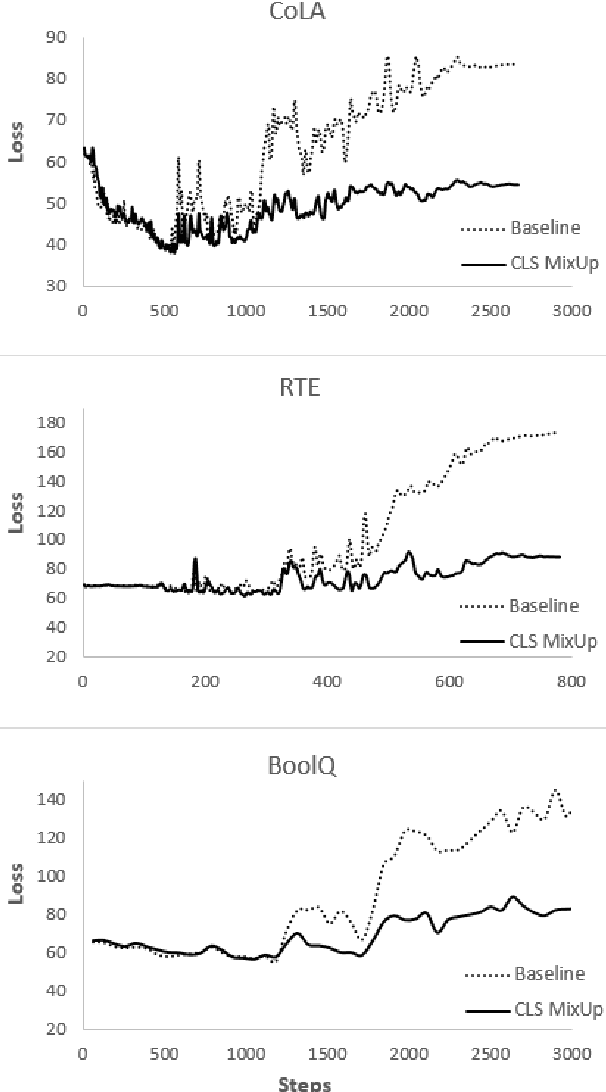
MixUp is a computer vision data augmentation technique that uses convex interpolations of input data and their labels to enhance model generalization during training. However, the application of MixUp to the natural language understanding (NLU) domain has been limited, due to the difficulty of interpolating text directly in the input space. In this study, we propose MixUp methods at the Input, Manifold, and sentence embedding levels for the transformer architecture, and apply them to finetune the BERT model for a diverse set of NLU tasks. We find that MixUp can improve model performance, as well as reduce test loss and model calibration error by up to 50%.
A Comprehensive Evaluation of Multi-task Learning and Multi-task Pre-training on EHR Time-series Data
Jul 20, 2020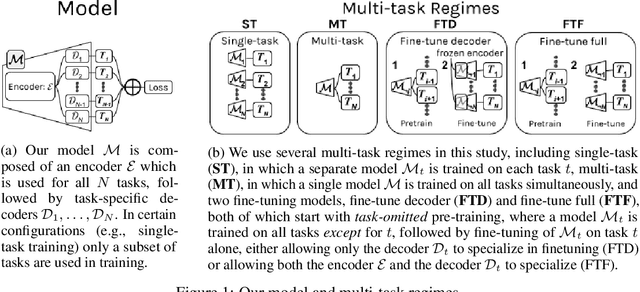
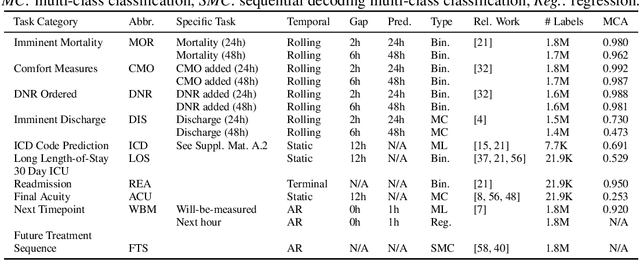
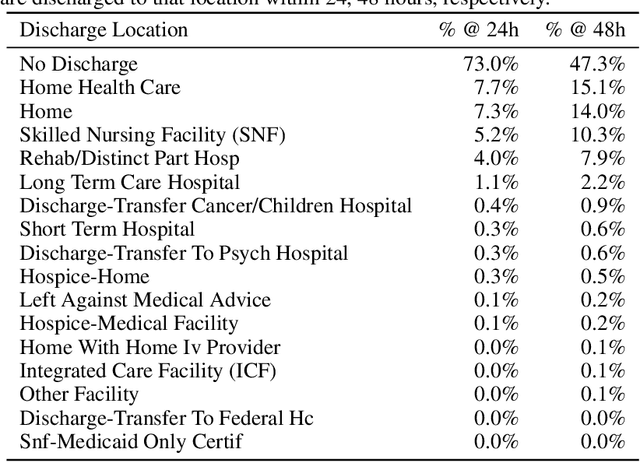
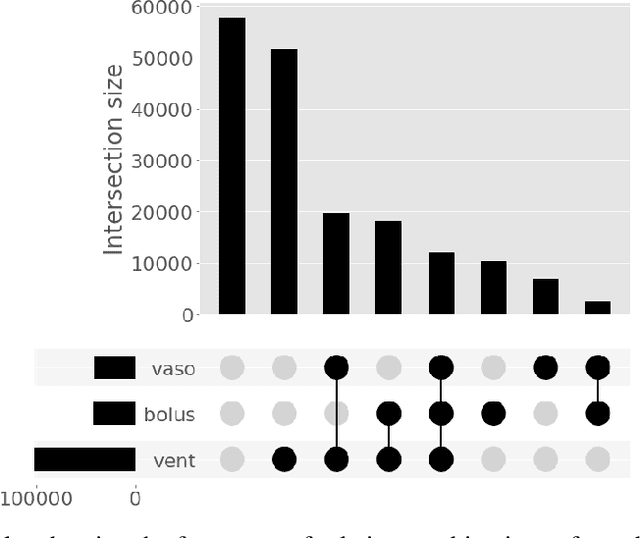
Multi-task learning (MTL) is a machine learning technique aiming to improve model performance by leveraging information across many tasks. It has been used extensively on various data modalities, including electronic health record (EHR) data. However, despite significant use on EHR data, there has been little systematic investigation of the utility of MTL across the diverse set of possible tasks and training schemes of interest in healthcare. In this work, we examine MTL across a battery of tasks on EHR time-series data. We find that while MTL does suffer from common negative transfer, we can realize significant gains via MTL pre-training combined with single-task fine-tuning. We demonstrate that these gains can be achieved in a task-independent manner and offer not only minor improvements under traditional learning, but also notable gains in a few-shot learning context, thereby suggesting this could be a scalable vehicle to offer improved performance in important healthcare contexts.