 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithmic Collective Action with Multiple Collectives
Aug 26, 2025As learning systems increasingly influence everyday decisions, user-side steering via Algorithmic Collective Action (ACA)-coordinated changes to shared data-offers a complement to regulator-side policy and firm-side model design. Although real-world actions have been traditionally decentralized and fragmented into multiple collectives despite sharing overarching objectives-with each collective differing in size, strategy, and actionable goals, most of the ACA literature focused on single collective settings. In this work, we present the first theoretical framework for ACA with multiple collectives acting on the same system. In particular, we focus on collective action in classification, studying how multiple collectives can plant signals, i.e., bias a classifier to learn an association between an altered version of the features and a chosen, possibly overlapping, set of target classes. We provide quantitative results about the role and the interplay of collectives' sizes and their alignment of goals. Our framework, by also complementing previous empirical results, opens a path for a holistic treatment of ACA with multiple collectives.
Event Stream GPT: A Data Pre-processing and Modeling Library for Generative, Pre-trained Transformers over Continuous-time Sequences of Complex Events
Jun 21, 2023Generative, pre-trained transformers (GPTs, a.k.a. "Foundation Models") have reshaped natural language processing (NLP) through their versatility in diverse downstream tasks. However, their potential extends far beyond NLP. This paper provides a software utility to help realize this potential, extending the applicability of GPTs to continuous-time sequences of complex events with internal dependencies, such as medical record datasets. Despite their potential, the adoption of foundation models in these domains has been hampered by the lack of suitable tools for model construction and evaluation. To bridge this gap, we introduce Event Stream GPT (ESGPT), an open-source library designed to streamline the end-to-end process for building GPTs for continuous-time event sequences. ESGPT allows users to (1) build flexible, foundation-model scale input datasets by specifying only a minimal configuration file, (2) leverage a Hugging Face compatible modeling API for GPTs over this modality that incorporates intra-event causal dependency structures and autoregressive generation capabilities, and (3) evaluate models via standardized processes that can assess few and even zero-shot performance of pre-trained models on user-specified fine-tuning tasks.
A Comprehensive Evaluation of Multi-task Learning and Multi-task Pre-training on EHR Time-series Data
Jul 20, 2020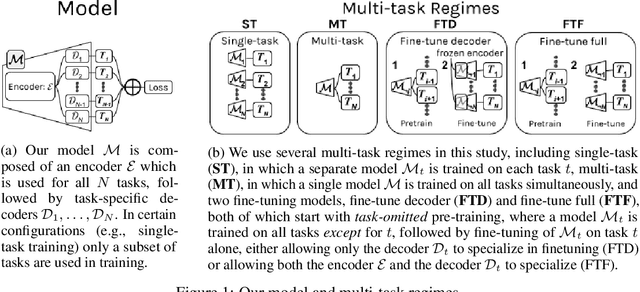
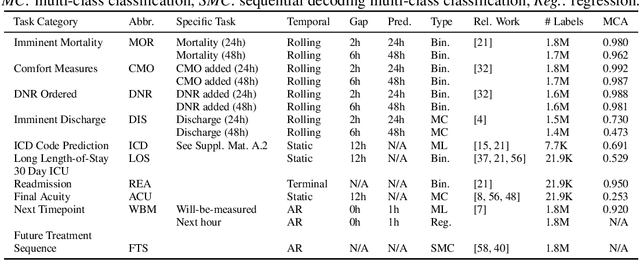
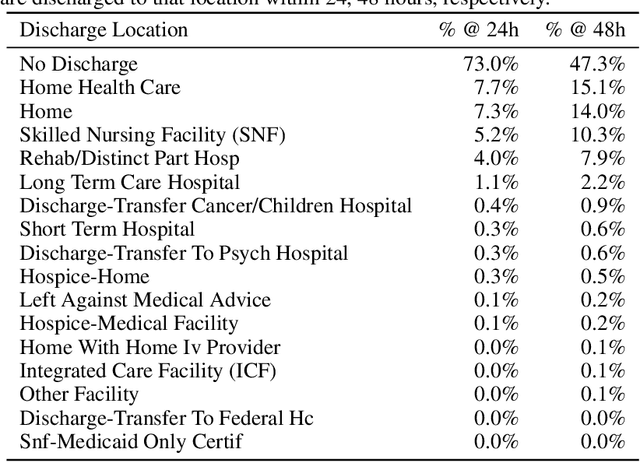
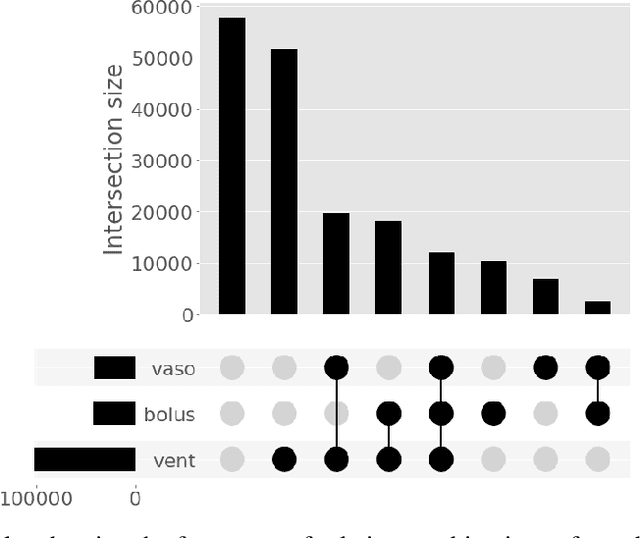
Multi-task learning (MTL) is a machine learning technique aiming to improve model performance by leveraging information across many tasks. It has been used extensively on various data modalities, including electronic health record (EHR) data. However, despite significant use on EHR data, there has been little systematic investigation of the utility of MTL across the diverse set of possible tasks and training schemes of interest in healthcare. In this work, we examine MTL across a battery of tasks on EHR time-series data. We find that while MTL does suffer from common negative transfer, we can realize significant gains via MTL pre-training combined with single-task fine-tuning. We demonstrate that these gains can be achieved in a task-independent manner and offer not only minor improvements under traditional learning, but also notable gains in a few-shot learning context, thereby suggesting this could be a scalable vehicle to offer improved performance in important healthcare contexts.
Cross-Language Aphasia Detection using Optimal Transport Domain Adaptation
Dec 04, 2019
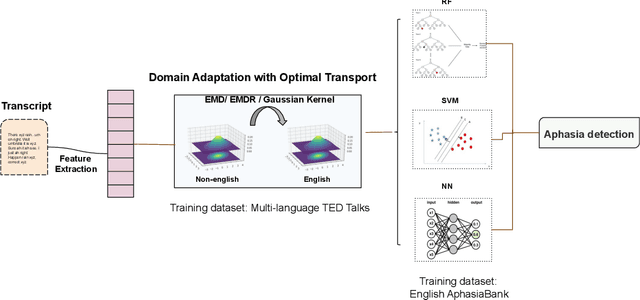

Multi-language speech datasets are scarce and often have small sample sizes in the medical domain. Robust transfer of linguistic features across languages could improve rates of early diagnosis and therapy for speakers of low-resource languages when detecting health conditions from speech. We utilize out-of-domain, unpaired, single-speaker, healthy speech data for training multiple Optimal Transport (OT) domain adaptation systems. We learn mappings from other languages to English and detect aphasia from linguistic characteristics of speech, and show that OT domain adaptation improves aphasia detection over unilingual baselines for French (6% increased F1) and Mandarin (5% increased F1). Further, we show that adding aphasic data to the domain adaptation system significantly increases performance for both French and Mandarin, increasing the F1 scores further (10% and 8% increase in F1 scores for French and Mandarin, respectively, over unilingual baselines).
Feature Robustness in Non-stationary Health Records: Caveats to Deployable Model Performance in Common Clinical Machine Learning Tasks
Aug 02, 2019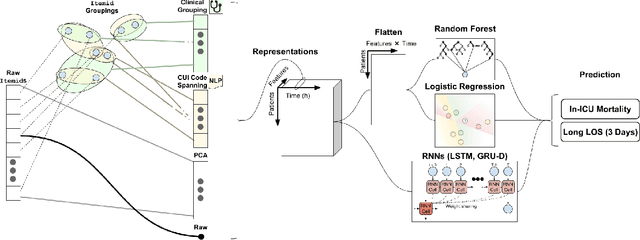
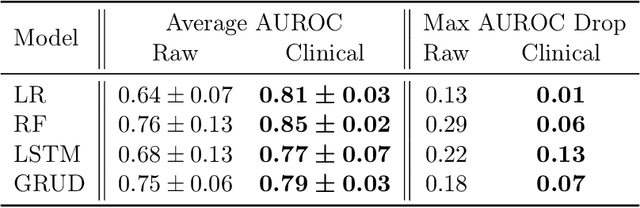
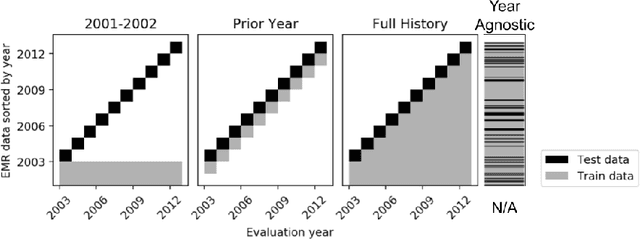

When training clinical prediction models from electronic health records (EHRs), a key concern should be a model's ability to sustain performance over time when deployed, even as care practices, database systems, and population demographics evolve. Due to de-identification requirements, however, current experimental practices for public EHR benchmarks (such as the MIMIC-III critical care dataset) are time agnostic, assigning care records to train or test sets without regard for the actual dates of care. As a result, current benchmarks cannot assess how well models trained on one year generalise to another. In this work, we obtain a Limited Data Use Agreement to access year of care for each record in MIMIC and show that all tested state-of-the-art models decay in prediction quality when trained on historical data and tested on future data, particularly in response to a system-wide record-keeping change in 2008 (0.29 drop in AUROC for mortality prediction, 0.10 drop in AUROC for length-of-stay prediction with a random forest classifier). We further develop a simple yet effective mitigation strategy: by aggregating raw features into expert-defined clinical concepts, we see only a 0.06 drop in AUROC for mortality prediction and a 0.03 drop in AUROC for length-of-stay prediction. We demonstrate that this aggregation strategy outperforms other automatic feature preprocessing techniques aimed at increasing robustness to data drift. We release our aggregated representations and code to encourage more deployable clinical prediction models.
Rethinking clinical prediction: Why machine learning must consider year of care and feature aggregation
Nov 30, 2018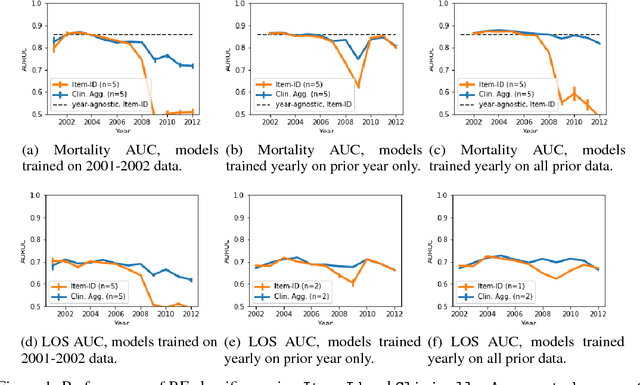
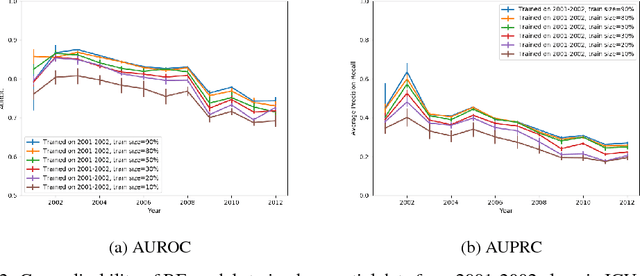
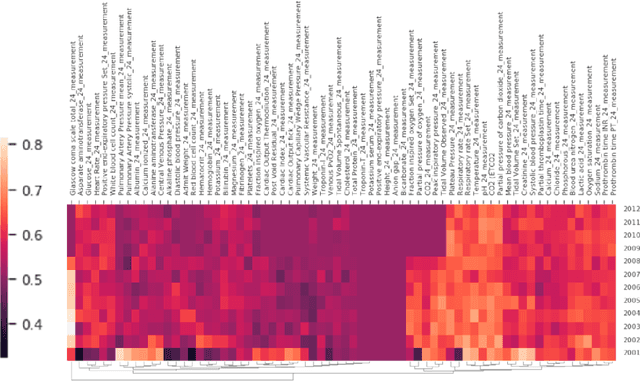
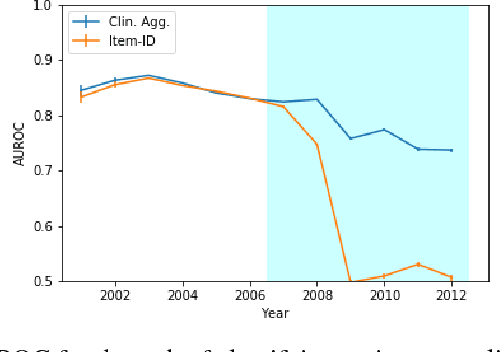
Machine learning for healthcare often trains models on de-identified datasets with randomly-shifted calendar dates, ignoring the fact that data were generated under hospital operation practices that change over time. These changing practices induce definitive changes in observed data which confound evaluations which do not account for dates and limit the generalisability of date-agnostic models. In this work, we establish the magnitude of this problem on MIMIC, a public hospital dataset, and showcase a simple solution. We augment MIMIC with the year in which care was provided and show that a model trained using standard feature representations will significantly degrade in quality over time. We find a deterioration of 0.3 AUC when evaluating mortality prediction on data from 10 years later. We find a similar deterioration of 0.15 AUC for length-of-stay. In contrast, we demonstrate that clinically-oriented aggregates of raw features significantly mitigate future deterioration. Our suggested aggregated representations, when retrained yearly, have prediction quality comparable to year-agnostic models.