 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Robustness in Non-stationary Health Records: Caveats to Deployable Model Performance in Common Clinical Machine Learning Tasks
Aug 02, 2019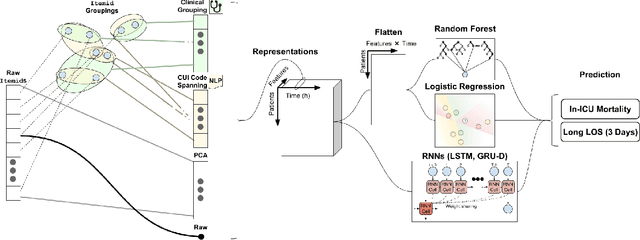
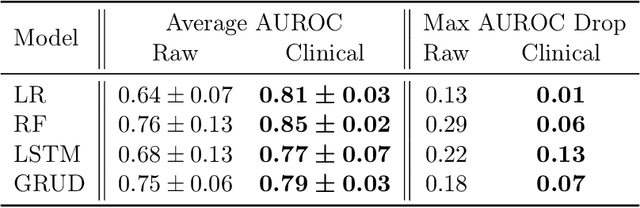
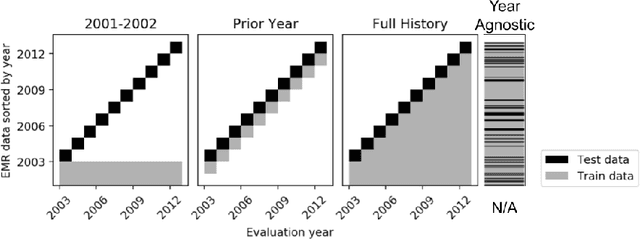

When training clinical prediction models from electronic health records (EHRs), a key concern should be a model's ability to sustain performance over time when deployed, even as care practices, database systems, and population demographics evolve. Due to de-identification requirements, however, current experimental practices for public EHR benchmarks (such as the MIMIC-III critical care dataset) are time agnostic, assigning care records to train or test sets without regard for the actual dates of care. As a result, current benchmarks cannot assess how well models trained on one year generalise to another. In this work, we obtain a Limited Data Use Agreement to access year of care for each record in MIMIC and show that all tested state-of-the-art models decay in prediction quality when trained on historical data and tested on future data, particularly in response to a system-wide record-keeping change in 2008 (0.29 drop in AUROC for mortality prediction, 0.10 drop in AUROC for length-of-stay prediction with a random forest classifier). We further develop a simple yet effective mitigation strategy: by aggregating raw features into expert-defined clinical concepts, we see only a 0.06 drop in AUROC for mortality prediction and a 0.03 drop in AUROC for length-of-stay prediction. We demonstrate that this aggregation strategy outperforms other automatic feature preprocessing techniques aimed at increasing robustness to data drift. We release our aggregated representations and code to encourage more deployable clinical prediction models.