 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Physics in Video World Models
Feb 04, 2026A long-standing question in physical reasoning is whether video-based models need to rely on factorized representations of physical variables in order to make physically accurate predictions, or whether they can implicitly represent such variables in a task-specific, distributed manner. While modern video world models achieve strong performance on intuitive physics benchmarks, it remains unclear which of these representational regimes they implement internally. Here, we present the first interpretability study to directly examine physical representations inside large-scale video encoders. Using layerwise probing, subspace geometry, patch-level decoding, and targeted attention ablations, we characterize where physical information becomes accessible and how it is organized within encoder-based video transformers. Across architectures, we identify a sharp intermediate-depth transition -- which we call the Physics Emergence Zone -- at which physical variables become accessible. Physics-related representations peak shortly after this transition and degrade toward the output layers. Decomposing motion into explicit variables, we find that scalar quantities such as speed and acceleration are available from early layers onwards, whereas motion direction becomes accessible only at the Physics Emergence Zone. Notably, we find that direction is encoded through a high-dimensional population structure with circular geometry, requiring coordinated multi-feature intervention to control. These findings suggest that modern video models do not use factorized representations of physical variables like a classical physics engine. Instead, they use a distributed representation that is nonetheless sufficient for making physical predictions.
A Lightweight Library for Energy-Based Joint-Embedding Predictive Architectures
Feb 03, 2026We present EB-JEPA, an open-source library for learning representations and world models using Joint-Embedding Predictive Architectures (JEPAs). JEPAs learn to predict in representation space rather than pixel space, avoiding the pitfalls of generative modeling while capturing semantically meaningful features suitable for downstream tasks. Our library provides modular, self-contained implementations that illustrate how representation learning techniques developed for image-level self-supervised learning can transfer to video, where temporal dynamics add complexity, and ultimately to action-conditioned world models, where the model must additionally learn to predict the effects of control inputs. Each example is designed for single-GPU training within a few hours, making energy-based self-supervised learning accessible for research and education. We provide ablations of JEA components on CIFAR-10. Probing these representations yields 91% accuracy, indicating that the model learns useful features. Extending to video, we include a multi-step prediction example on Moving MNIST that demonstrates how the same principles scale to temporal modeling. Finally, we show how these representations can drive action-conditioned world models, achieving a 97% planning success rate on the Two Rooms navigation task. Comprehensive ablations reveal the critical importance of each regularization component for preventing representation collapse. Code is available at https://github.com/facebookresearch/eb_jepa.
Learning Latent Action World Models In The Wild
Jan 08, 2026Agents capable of reasoning and planning in the real world require the ability of predicting the consequences of their actions. While world models possess this capability, they most often require action labels, that can be complex to obtain at scale. This motivates the learning of latent action models, that can learn an action space from videos alone. Our work addresses the problem of learning latent actions world models on in-the-wild videos, expanding the scope of existing works that focus on simple robotics simulations, video games, or manipulation data. While this allows us to capture richer actions, it also introduces challenges stemming from the video diversity, such as environmental noise, or the lack of a common embodiment across videos. To address some of the challenges, we discuss properties that actions should follow as well as relevant architectural choices and evaluations. We find that continuous, but constrained, latent actions are able to capture the complexity of actions from in-the-wild videos, something that the common vector quantization does not. We for example find that changes in the environment coming from agents, such as humans entering the room, can be transferred across videos. This highlights the capability of learning actions that are specific to in-the-wild videos. In the absence of a common embodiment across videos, we are mainly able to learn latent actions that become localized in space, relative to the camera. Nonetheless, we are able to train a controller that maps known actions to latent ones, allowing us to use latent actions as a universal interface and solve planning tasks with our world model with similar performance as action-conditioned baselines. Our analyses and experiments provide a step towards scaling latent action models to the real world.
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Jun 11, 2025A major challenge for modern AI is to learn to understand the world and learn to act largely by observation. This paper explores a self-supervised approach that combines internet-scale video data with a small amount of interaction data (robot trajectories), to develop models capable of understanding, predicting, and planning in the physical world. We first pre-train an action-free joint-embedding-predictive architecture, V-JEPA 2, on a video and image dataset comprising over 1 million hours of internet video. V-JEPA 2 achieves strong performance on motion understanding (77.3 top-1 accuracy on Something-Something v2) and state-of-the-art performance on human action anticipation (39.7 recall-at-5 on Epic-Kitchens-100) surpassing previous task-specific models. Additionally, after aligning V-JEPA 2 with a large language model, we demonstrate state-of-the-art performance on multiple video question-answering tasks at the 8 billion parameter scale (e.g., 84.0 on PerceptionTest, 76.9 on TempCompass). Finally, we show how self-supervised learning can be applied to robotic planning tasks by post-training a latent action-conditioned world model, V-JEPA 2-AC, using less than 62 hours of unlabeled robot videos from the Droid dataset. We deploy V-JEPA 2-AC zero-shot on Franka arms in two different labs and enable picking and placing of objects using planning with image goals. Notably, this is achieved without collecting any data from the robots in these environments, and without any task-specific training or reward. This work demonstrates how self-supervised learning from web-scale data and a small amount of robot interaction data can yield a world model capable of planning in the physical world.
A Shortcut-aware Video-QA Benchmark for Physical Understanding via Minimal Video Pairs
Jun 11, 2025



Existing benchmarks for assessing the spatio-temporal understanding and reasoning abilities of video language models are susceptible to score inflation due to the presence of shortcut solutions based on superficial visual or textual cues. This paper mitigates the challenges in accurately assessing model performance by introducing the Minimal Video Pairs (MVP) benchmark, a simple shortcut-aware video QA benchmark for assessing the physical understanding of video language models. The benchmark is comprised of 55K high-quality multiple-choice video QA examples focusing on physical world understanding. Examples are curated from nine video data sources, spanning first-person egocentric and exocentric videos, robotic interaction data, and cognitive science intuitive physics benchmarks. To mitigate shortcut solutions that rely on superficial visual or textual cues and biases, each sample in MVP has a minimal-change pair -- a visually similar video accompanied by an identical question but an opposing answer. To answer a question correctly, a model must provide correct answers for both examples in the minimal-change pair; as such, models that solely rely on visual or textual biases would achieve below random performance. Human performance on MVP is 92.9\%, while the best open-source state-of-the-art video-language model achieves 40.2\% compared to random performance at 25\%.
IntPhys 2: Benchmarking Intuitive Physics Understanding In Complex Synthetic Environments
Jun 11, 2025



We present IntPhys 2, a video benchmark designed to evaluate the intuitive physics understanding of deep learning models. Building on the original IntPhys benchmark, IntPhys 2 focuses on four core principles related to macroscopic objects: Permanence, Immutability, Spatio-Temporal Continuity, and Solidity. These conditions are inspired by research into intuitive physical understanding emerging during early childhood. IntPhys 2 offers a comprehensive suite of tests, based on the violation of expectation framework, that challenge models to differentiate between possible and impossible events within controlled and diverse virtual environments. Alongside the benchmark, we provide performance evaluations of several state-of-the-art models. Our findings indicate that while these models demonstrate basic visual understanding, they face significant challenges in grasping intuitive physics across the four principles in complex scenes, with most models performing at chance levels (50%), in stark contrast to human performance, which achieves near-perfect accuracy. This underscores the gap between current models and human-like intuitive physics understanding, highlighting the need for advancements in model architectures and training methodologies.
Intuitive physics understanding emerges from self-supervised pretraining on natural videos
Feb 17, 2025We investigate the emergence of intuitive physics understanding in general-purpose deep neural network models trained to predict masked regions in natural videos. Leveraging the violation-of-expectation framework, we find that video prediction models trained to predict outcomes in a learned representation space demonstrate an understanding of various intuitive physics properties, such as object permanence and shape consistency. In contrast, video prediction in pixel space and multimodal large language models, which reason through text, achieve performance closer to chance. Our comparisons of these architectures reveal that jointly learning an abstract representation space while predicting missing parts of sensory input, akin to predictive coding, is sufficient to acquire an understanding of intuitive physics, and that even models trained on one week of unique video achieve above chance performance. This challenges the idea that core knowledge -- a set of innate systems to help understand the world -- needs to be hardwired to develop an understanding of intuitive physics.
UniBench: Visual Reasoning Requires Rethinking Vision-Language Beyond Scaling
Aug 09, 2024



Significant research efforts have been made to scale and improve vision-language model (VLM) training approaches. Yet, with an ever-growing number of benchmarks, researchers are tasked with the heavy burden of implementing each protocol, bearing a non-trivial computational cost, and making sense of how all these benchmarks translate into meaningful axes of progress. To facilitate a systematic evaluation of VLM progress, we introduce UniBench: a unified implementation of 50+ VLM benchmarks spanning a comprehensive range of carefully categorized capabilities from object recognition to spatial awareness, counting, and much more. We showcase the utility of UniBench for measuring progress by evaluating nearly 60 publicly available vision-language models, trained on scales of up to 12.8B samples. We find that while scaling training data or model size can boost many vision-language model capabilities, scaling offers little benefit for reasoning or relations. Surprisingly, we also discover today's best VLMs struggle on simple digit recognition and counting tasks, e.g. MNIST, which much simpler networks can solve. Where scale falls short, we find that more precise interventions, such as data quality or tailored-learning objectives offer more promise. For practitioners, we also offer guidance on selecting a suitable VLM for a given application. Finally, we release an easy-to-run UniBench code-base with the full set of 50+ benchmarks and comparisons across 59 models as well as a distilled, representative set of benchmarks that runs in 5 minutes on a single GPU.
An Introduction to Vision-Language Modeling
May 27, 2024


Following the recent popularity of Large Language Models (LLMs), several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamiliar environments to generative models that produce images using only a high-level text description, the vision-language model (VLM) applications will significantly impact our relationship with technology. However, there are many challenges that need to be addressed to improve the reliability of those models. While language is discrete, vision evolves in a much higher dimensional space in which concepts cannot always be easily discretized. To better understand the mechanics behind mapping vision to language, we present this introduction to VLMs which we hope will help anyone who would like to enter the field. First, we introduce what VLMs are, how they work, and how to train them. Then, we present and discuss approaches to evaluate VLMs. Although this work primarily focuses on mapping images to language, we also discuss extending VLMs to videos.
Learning and Leveraging World Models in Visual Representation Learning
Mar 01, 2024


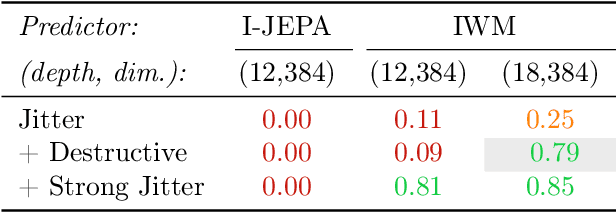
Joint-Embedding Predictive Architecture (JEPA) has emerged as a promising self-supervised approach that learns by leveraging a world model. While previously limited to predicting missing parts of an input, we explore how to generalize the JEPA prediction task to a broader set of corruptions. We introduce Image World Models, an approach that goes beyond masked image modeling and learns to predict the effect of global photometric transformations in latent space. We study the recipe of learning performant IWMs and show that it relies on three key aspects: conditioning, prediction difficulty, and capacity. Additionally, we show that the predictive world model learned by IWM can be adapted through finetuning to solve diverse tasks; a fine-tuned IWM world model matches or surpasses the performance of previous self-supervised methods. Finally, we show that learning with an IWM allows one to control the abstraction level of the learned representations, learning invariant representations such as contrastive methods, or equivariant representations such as masked image modelling.