 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniBench: Visual Reasoning Requires Rethinking Vision-Language Beyond Scaling
Aug 09, 2024



Significant research efforts have been made to scale and improve vision-language model (VLM) training approaches. Yet, with an ever-growing number of benchmarks, researchers are tasked with the heavy burden of implementing each protocol, bearing a non-trivial computational cost, and making sense of how all these benchmarks translate into meaningful axes of progress. To facilitate a systematic evaluation of VLM progress, we introduce UniBench: a unified implementation of 50+ VLM benchmarks spanning a comprehensive range of carefully categorized capabilities from object recognition to spatial awareness, counting, and much more. We showcase the utility of UniBench for measuring progress by evaluating nearly 60 publicly available vision-language models, trained on scales of up to 12.8B samples. We find that while scaling training data or model size can boost many vision-language model capabilities, scaling offers little benefit for reasoning or relations. Surprisingly, we also discover today's best VLMs struggle on simple digit recognition and counting tasks, e.g. MNIST, which much simpler networks can solve. Where scale falls short, we find that more precise interventions, such as data quality or tailored-learning objectives offer more promise. For practitioners, we also offer guidance on selecting a suitable VLM for a given application. Finally, we release an easy-to-run UniBench code-base with the full set of 50+ benchmarks and comparisons across 59 models as well as a distilled, representative set of benchmarks that runs in 5 minutes on a single GPU.
An Introduction to Vision-Language Modeling
May 27, 2024


Following the recent popularity of Large Language Models (LLMs), several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamiliar environments to generative models that produce images using only a high-level text description, the vision-language model (VLM) applications will significantly impact our relationship with technology. However, there are many challenges that need to be addressed to improve the reliability of those models. While language is discrete, vision evolves in a much higher dimensional space in which concepts cannot always be easily discretized. To better understand the mechanics behind mapping vision to language, we present this introduction to VLMs which we hope will help anyone who would like to enter the field. First, we introduce what VLMs are, how they work, and how to train them. Then, we present and discuss approaches to evaluate VLMs. Although this work primarily focuses on mapping images to language, we also discuss extending VLMs to videos.
The Impact of Spatiotemporal Augmentations on Self-Supervised Audiovisual Representation Learning
Oct 13, 2021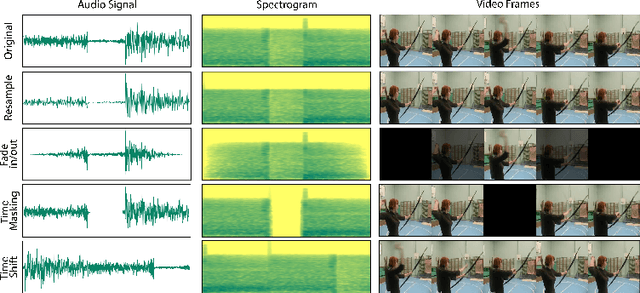
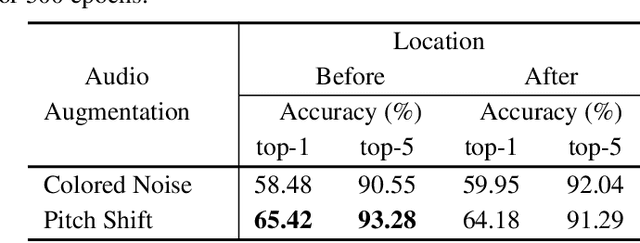
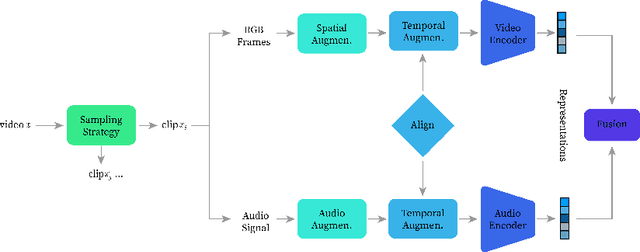
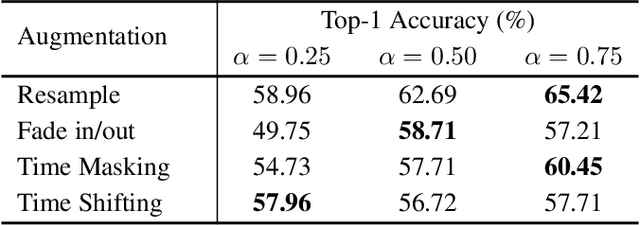
Contrastive learning of auditory and visual perception has been extremely successful when investigated individually. However, there are still major questions on how we could integrate principles learned from both domains to attain effective audiovisual representations. In this paper, we present a contrastive framework to learn audiovisual representations from unlabeled videos. The type and strength of augmentations utilized during self-supervised pre-training play a crucial role for contrastive frameworks to work sufficiently. Hence, we extensively investigate composition of temporal augmentations suitable for learning audiovisual representations; we find lossy spatio-temporal transformations that do not corrupt the temporal coherency of videos are the most effective. Furthermore, we show that the effectiveness of these transformations scales with higher temporal resolution and stronger transformation intensity. Compared to self-supervised models pre-trained on only sampling-based temporal augmentation, self-supervised models pre-trained with our temporal augmentations lead to approximately 6.5% gain on linear classifier performance on AVE dataset. Lastly, we show that despite their simplicity, our proposed transformations work well across self-supervised learning frameworks (SimSiam, MoCoV3, etc), and benchmark audiovisual dataset (AVE).
CLAR: Contrastive Learning of Auditory Representations
Oct 19, 2020



Learning rich visual representations using contrastive self-supervised learning has been extremely successful. However, it is still a major question whether we could use a similar approach to learn superior auditory representations. In this paper, we expand on prior work (SimCLR) to learn better auditory representations. We (1) introduce various data augmentations suitable for auditory data and evaluate their impact on predictive performance, (2) show that training with time-frequency audio features substantially improves the quality of the learned representations compared to raw signals, and (3) demonstrate that training with both supervised and contrastive losses simultaneously improves the learned representations compared to self-supervised pre-training followed by supervised fine-tuning. We illustrate that by combining all these methods and with substantially less labeled data, our framework (CLAR) achieves significant improvement on prediction performance compared to supervised approach. Moreover, compared to self-supervised approach, our framework converges faster with significantly better representations.