 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxelCodeBench: Benchmarking 3D World Modeling Through Code Generation
Apr 02, 2026Evaluating code generation models for 3D spatial reasoning requires executing generated code in realistic environments and assessing outputs beyond surface-level correctness. We introduce a platform VoxelCode, for analyzing code generation capabilities for 3D understanding and environment creation. Our platform integrates natural language task specification, API-driven code execution in Unreal Engine, and a unified evaluation pipeline supporting both automated metrics and human assessment. To demonstrate its utility, we construct VoxelCodeBench, a benchmark of voxel manipulation tasks spanning three reasoning dimensions: symbolic interpretation, geometric construction, and artistic composition. Evaluating leading code generation models, we find that producing executable code is far easier than producing spatially correct outputs, with geometric construction and multi-object composition proving particularly challenging. By open-sourcing our platform and benchmark, we provide the community with extensible infrastructure for developing new 3D code generation benchmarks and probing spatial reasoning in future models.
VideoAuto-R1: Video Auto Reasoning via Thinking Once, Answering Twice
Jan 08, 2026Chain-of-thought (CoT) reasoning has emerged as a powerful tool for multimodal large language models on video understanding tasks. However, its necessity and advantages over direct answering remain underexplored. In this paper, we first demonstrate that for RL-trained video models, direct answering often matches or even surpasses CoT performance, despite CoT producing step-by-step analyses at a higher computational cost. Motivated by this, we propose VideoAuto-R1, a video understanding framework that adopts a reason-when-necessary strategy. During training, our approach follows a Thinking Once, Answering Twice paradigm: the model first generates an initial answer, then performs reasoning, and finally outputs a reviewed answer. Both answers are supervised via verifiable rewards. During inference, the model uses the confidence score of the initial answer to determine whether to proceed with reasoning. Across video QA and grounding benchmarks, VideoAuto-R1 achieves state-of-the-art accuracy with significantly improved efficiency, reducing the average response length by ~3.3x, e.g., from 149 to just 44 tokens. Moreover, we observe a low rate of thinking-mode activation on perception-oriented tasks, but a higher rate on reasoning-intensive tasks. This suggests that explicit language-based reasoning is generally beneficial but not always necessary.
What's in Common? Multimodal Models Hallucinate When Reasoning Across Scenes
Nov 05, 2025Multimodal language models possess a remarkable ability to handle an open-vocabulary's worth of objects. Yet the best models still suffer from hallucinations when reasoning about scenes in the real world, revealing a gap between their seemingly strong performance on existing perception benchmarks that are saturating and their reasoning in the real world. To address this gap, we build a novel benchmark of in-the-wild scenes that we call Common-O. With more than 10.5k examples using exclusively new images not found in web training data to avoid contamination, Common-O goes beyond just perception, inspired by cognitive tests for humans, to probe reasoning across scenes by asking "what's in common?". We evaluate leading multimodal language models, including models specifically trained to perform chain-of-thought reasoning. We find that perceiving objects in single images is tractable for most models, yet reasoning across scenes is very challenging even for the best models, including reasoning models. Despite saturating many leaderboards focusing on perception, the best performing model only achieves 35% on Common-O -- and on Common-O Complex, consisting of more complex scenes, the best model achieves only 1%. Curiously, we find models are more prone to hallucinate when similar objects are present in the scene, suggesting models may be relying on object co-occurrence seen during training. Among the models we evaluated, we found scale can provide modest improvements while models explicitly trained with multi-image inputs show bigger improvements, suggesting scaled multi-image training may offer promise. We make our benchmark publicly available to spur research into the challenge of hallucination when reasoning across scenes.
IntPhys 2: Benchmarking Intuitive Physics Understanding In Complex Synthetic Environments
Jun 11, 2025



We present IntPhys 2, a video benchmark designed to evaluate the intuitive physics understanding of deep learning models. Building on the original IntPhys benchmark, IntPhys 2 focuses on four core principles related to macroscopic objects: Permanence, Immutability, Spatio-Temporal Continuity, and Solidity. These conditions are inspired by research into intuitive physical understanding emerging during early childhood. IntPhys 2 offers a comprehensive suite of tests, based on the violation of expectation framework, that challenge models to differentiate between possible and impossible events within controlled and diverse virtual environments. Alongside the benchmark, we provide performance evaluations of several state-of-the-art models. Our findings indicate that while these models demonstrate basic visual understanding, they face significant challenges in grasping intuitive physics across the four principles in complex scenes, with most models performing at chance levels (50%), in stark contrast to human performance, which achieves near-perfect accuracy. This underscores the gap between current models and human-like intuitive physics understanding, highlighting the need for advancements in model architectures and training methodologies.
Measuring Déjà vu Memorization Efficiently
Apr 08, 2025



Recent research has shown that representation learning models may accidentally memorize their training data. For example, the d\'ej\`a vu method shows that for certain representation learning models and training images, it is sometimes possible to correctly predict the foreground label given only the representation of the background - better than through dataset-level correlations. However, their measurement method requires training two models - one to estimate dataset-level correlations and the other to estimate memorization. This multiple model setup becomes infeasible for large open-source models. In this work, we propose alternative simple methods to estimate dataset-level correlations, and show that these can be used to approximate an off-the-shelf model's memorization ability without any retraining. This enables, for the first time, the measurement of memorization in pre-trained open-source image representation and vision-language representation models. Our results show that different ways of measuring memorization yield very similar aggregate results. We also find that open-source models typically have lower aggregate memorization than similar models trained on a subset of the data. The code is available both for vision and vision language models.
Improving the Scaling Laws of Synthetic Data with Deliberate Practice
Feb 21, 2025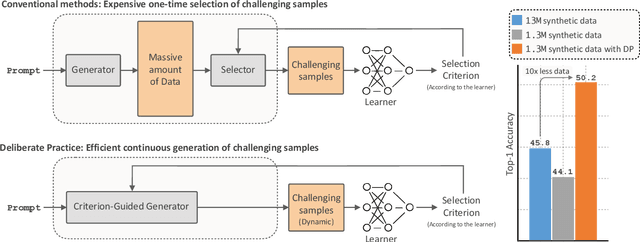
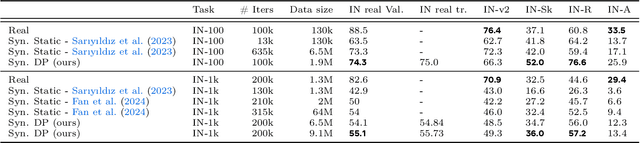
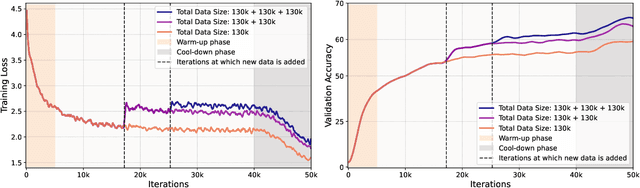

Inspired by the principle of deliberate practice in human learning, we propose Deliberate Practice for Synthetic Data Generation (DP), a novel framework that improves sample efficiency through dynamic synthetic data generation. Prior work has shown that scaling synthetic data is inherently challenging, as naively adding new data leads to diminishing returns. To address this, pruning has been identified as a key mechanism for improving scaling, enabling models to focus on the most informative synthetic samples. Rather than generating a large dataset and pruning it afterward, DP efficiently approximates the direct generation of informative samples. We theoretically show how training on challenging, informative examples improves scaling laws and empirically validate that DP achieves better scaling performance with significantly fewer training samples and iterations. On ImageNet-100, DP generates 3.4x fewer samples and requires six times fewer iterations, while on ImageNet-1k, it generates 8x fewer samples with a 30 percent reduction in iterations, all while achieving superior performance compared to prior work.
Object-centric Binding in Contrastive Language-Image Pretraining
Feb 19, 2025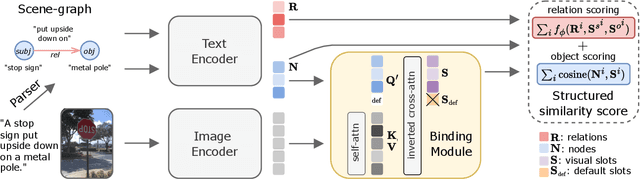
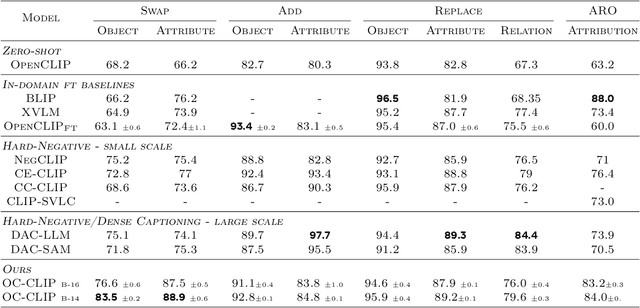
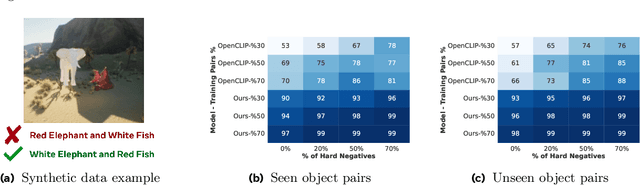
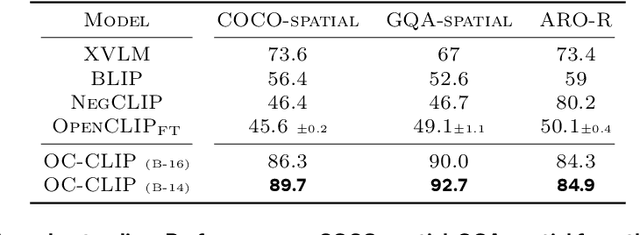
Recent advances in vision language models (VLM) have been driven by contrastive models such as CLIP, which learn to associate visual information with their corresponding text descriptions. However, these models have limitations in understanding complex compositional scenes involving multiple objects and their spatial relationships. To address these challenges, we propose a novel approach that diverges from commonly used strategies, which rely on the design of hard-negative augmentations. Instead, our work focuses on integrating inductive biases into pre-trained CLIP-like models to improve their compositional understanding without using any additional hard-negatives. To that end, we introduce a binding module that connects a scene graph, derived from a text description, with a slot-structured image representation, facilitating a structured similarity assessment between the two modalities. We also leverage relationships as text-conditioned visual constraints, thereby capturing the intricate interactions between objects and their contextual relationships more effectively. Our resulting model not only enhances the performance of CLIP-based models in multi-object compositional understanding but also paves the way towards more accurate and sample-efficient image-text matching of complex scenes.
LongVU: Spatiotemporal Adaptive Compression for Long Video-Language Understanding
Oct 22, 2024



Multimodal Large Language Models (MLLMs) have shown promising progress in understanding and analyzing video content. However, processing long videos remains a significant challenge constrained by LLM's context size. To address this limitation, we propose LongVU, a spatiotemporal adaptive compression mechanism thats reduces the number of video tokens while preserving visual details of long videos. Our idea is based on leveraging cross-modal query and inter-frame dependencies to adaptively reduce temporal and spatial redundancy in videos. Specifically, we leverage DINOv2 features to remove redundant frames that exhibit high similarity. Then we utilize text-guided cross-modal query for selective frame feature reduction. Further, we perform spatial token reduction across frames based on their temporal dependencies. Our adaptive compression strategy effectively processes a large number of frames with little visual information loss within given context length. Our LongVU consistently surpass existing methods across a variety of video understanding benchmarks, especially on hour-long video understanding tasks such as VideoMME and MLVU. Given a light-weight LLM, our LongVU also scales effectively into a smaller size with state-of-the-art video understanding performance.
An Introduction to Vision-Language Modeling
May 27, 2024


Following the recent popularity of Large Language Models (LLMs), several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamiliar environments to generative models that produce images using only a high-level text description, the vision-language model (VLM) applications will significantly impact our relationship with technology. However, there are many challenges that need to be addressed to improve the reliability of those models. While language is discrete, vision evolves in a much higher dimensional space in which concepts cannot always be easily discretized. To better understand the mechanics behind mapping vision to language, we present this introduction to VLMs which we hope will help anyone who would like to enter the field. First, we introduce what VLMs are, how they work, and how to train them. Then, we present and discuss approaches to evaluate VLMs. Although this work primarily focuses on mapping images to language, we also discuss extending VLMs to videos.
A Picture is Worth More Than 77 Text Tokens: Evaluating CLIP-Style Models on Dense Captions
Dec 14, 2023

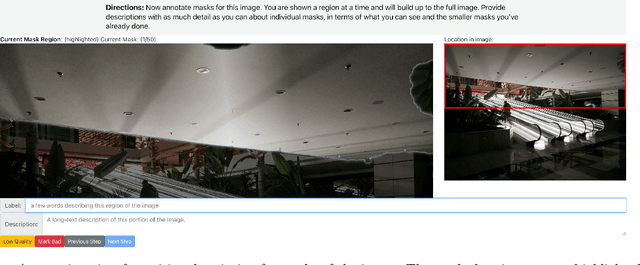

Curation methods for massive vision-language datasets trade off between dataset size and quality. However, even the highest quality of available curated captions are far too short to capture the rich visual detail in an image. To show the value of dense and highly-aligned image-text pairs, we collect the Densely Captioned Images (DCI) dataset, containing 8012 natural images human-annotated with mask-aligned descriptions averaging above 1000 words each. With precise and reliable captions associated with specific parts of an image, we can evaluate vision-language models' (VLMs) understanding of image content with a novel task that matches each caption with its corresponding subcrop. As current models are often limited to 77 text tokens, we also introduce a summarized version (sDCI) in which each caption length is limited. We show that modern techniques that make progress on standard benchmarks do not correspond with significant improvement on our sDCI based benchmark. Lastly, we finetune CLIP using sDCI and show significant improvements over the baseline despite a small training set. By releasing the first human annotated dense image captioning dataset, we hope to enable the development of new benchmarks or fine-tuning recipes for the next generation of VLMs to come.