 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy Blur: Quantifying Privacy and Utility for Image Data Release
Dec 18, 2025
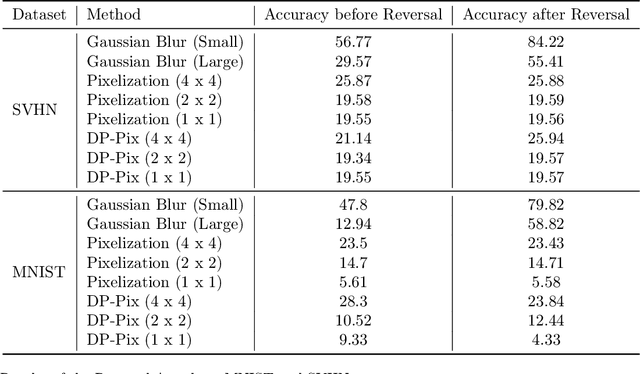

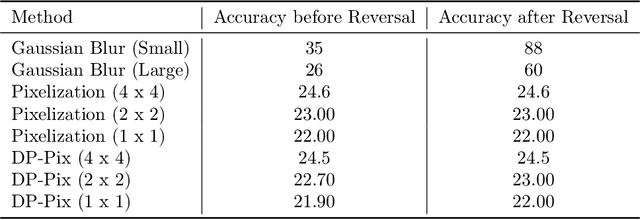
Image data collected in the wild often contains private information such as faces and license plates, and responsible data release must ensure that this information stays hidden. At the same time, released data should retain its usefulness for model-training. The standard method for private information obfuscation in images is Gaussian blurring. In this work, we show that practical implementations of Gaussian blurring are reversible enough to break privacy. We then take a closer look at the privacy-utility tradeoffs offered by three other obfuscation algorithms -- pixelization, pixelization and noise addition (DP-Pix), and cropping. Privacy is evaluated by reversal and discrimination attacks, while utility by the quality of the learnt representations when the model is trained on data with obfuscated faces. We show that the most popular industry-standard method, Gaussian blur is the least private of the four -- being susceptible to reversal attacks in its practical low-precision implementations. In contrast, pixelization and pixelization plus noise addition, when used at the right level of granularity, offer both privacy and utility for a number of computer vision tasks. We make our proposed methods together with suggested parameters available in a software package called Privacy Blur.
RL Is a Hammer and LLMs Are Nails: A Simple Reinforcement Learning Recipe for Strong Prompt Injection
Oct 06, 2025Prompt injection poses a serious threat to the reliability and safety of LLM agents. Recent defenses against prompt injection, such as Instruction Hierarchy and SecAlign, have shown notable robustness against static attacks. However, to more thoroughly evaluate the robustness of these defenses, it is arguably necessary to employ strong attacks such as automated red-teaming. To this end, we introduce RL-Hammer, a simple recipe for training attacker models that automatically learn to perform strong prompt injections and jailbreaks via reinforcement learning. RL-Hammer requires no warm-up data and can be trained entirely from scratch. To achieve high ASRs against industrial-level models with defenses, we propose a set of practical techniques that enable highly effective, universal attacks. Using this pipeline, RL-Hammer reaches a 98% ASR against GPT-4o and a $72\%$ ASR against GPT-5 with the Instruction Hierarchy defense. We further discuss the challenge of achieving high diversity in attacks, highlighting how attacker models tend to reward-hack diversity objectives. Finally, we show that RL-Hammer can evade multiple prompt injection detectors. We hope our work advances automatic red-teaming and motivates the development of stronger, more principled defenses. Code is available at https://github.com/facebookresearch/rl-injector.
How much do language models memorize?
May 30, 2025We propose a new method for estimating how much a model ``knows'' about a datapoint and use it to measure the capacity of modern language models. Prior studies of language model memorization have struggled to disentangle memorization from generalization. We formally separate memorization into two components: \textit{unintended memorization}, the information a model contains about a specific dataset, and \textit{generalization}, the information a model contains about the true data-generation process. When we completely eliminate generalization, we can compute the total memorization, which provides an estimate of model capacity: our measurements estimate that GPT-style models have a capacity of approximately 3.6 bits per parameter. We train language models on datasets of increasing size and observe that models memorize until their capacity fills, at which point ``grokking'' begins, and unintended memorization decreases as models begin to generalize. We train hundreds of transformer language models ranging from $500K$ to $1.5B$ parameters and produce a series of scaling laws relating model capacity and data size to membership inference.
Measuring Déjà vu Memorization Efficiently
Apr 08, 2025



Recent research has shown that representation learning models may accidentally memorize their training data. For example, the d\'ej\`a vu method shows that for certain representation learning models and training images, it is sometimes possible to correctly predict the foreground label given only the representation of the background - better than through dataset-level correlations. However, their measurement method requires training two models - one to estimate dataset-level correlations and the other to estimate memorization. This multiple model setup becomes infeasible for large open-source models. In this work, we propose alternative simple methods to estimate dataset-level correlations, and show that these can be used to approximate an off-the-shelf model's memorization ability without any retraining. This enables, for the first time, the measurement of memorization in pre-trained open-source image representation and vision-language representation models. Our results show that different ways of measuring memorization yield very similar aggregate results. We also find that open-source models typically have lower aggregate memorization than similar models trained on a subset of the data. The code is available both for vision and vision language models.
On Symmetries in Convolutional Weights
Mar 24, 2025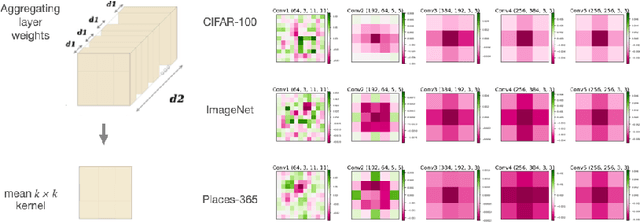

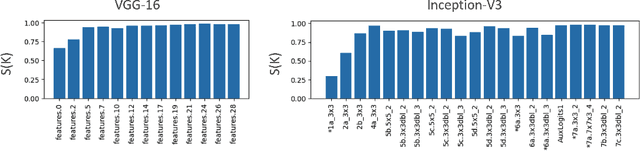
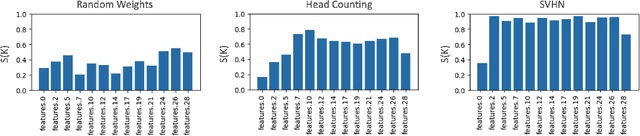
We explore the symmetry of the mean k x k weight kernel in each layer of various convolutional neural networks. Unlike individual neurons, the mean kernels in internal layers tend to be symmetric about their centers instead of favoring specific directions. We investigate why this symmetry emerges in various datasets and models, and how it is impacted by certain architectural choices. We show how symmetry correlates with desirable properties such as shift and flip consistency, and might constitute an inherent inductive bias in convolutional neural networks.
Using Captum to Explain Generative Language Models
Dec 09, 2023Captum is a comprehensive library for model explainability in PyTorch, offering a range of methods from the interpretability literature to enhance users' understanding of PyTorch models. In this paper, we introduce new features in Captum that are specifically designed to analyze the behavior of generative language models. We provide an overview of the available functionalities and example applications of their potential for understanding learned associations within generative language models.
Error Discovery by Clustering Influence Embeddings
Dec 07, 2023



We present a method for identifying groups of test examples -- slices -- on which a model under-performs, a task now known as slice discovery. We formalize coherence -- a requirement that erroneous predictions, within a slice, should be wrong for the same reason -- as a key property that any slice discovery method should satisfy. We then use influence functions to derive a new slice discovery method, InfEmbed, which satisfies coherence by returning slices whose examples are influenced similarly by the training data. InfEmbed is simple, and consists of applying K-Means clustering to a novel representation we deem influence embeddings. We show InfEmbed outperforms current state-of-the-art methods on 2 benchmarks, and is effective for model debugging across several case studies.
XAIR: A Framework of Explainable AI in Augmented Reality
Mar 28, 2023



Explainable AI (XAI) has established itself as an important component of AI-driven interactive systems. With Augmented Reality (AR) becoming more integrated in daily lives, the role of XAI also becomes essential in AR because end-users will frequently interact with intelligent services. However, it is unclear how to design effective XAI experiences for AR. We propose XAIR, a design framework that addresses "when", "what", and "how" to provide explanations of AI output in AR. The framework was based on a multi-disciplinary literature review of XAI and HCI research, a large-scale survey probing 500+ end-users' preferences for AR-based explanations, and three workshops with 12 experts collecting their insights about XAI design in AR. XAIR's utility and effectiveness was verified via a study with 10 designers and another study with 12 end-users. XAIR can provide guidelines for designers, inspiring them to identify new design opportunities and achieve effective XAI designs in AR.
Bias Mitigation Framework for Intersectional Subgroups in Neural Networks
Dec 26, 2022We propose a fairness-aware learning framework that mitigates intersectional subgroup bias associated with protected attributes. Prior research has primarily focused on mitigating one kind of bias by incorporating complex fairness-driven constraints into optimization objectives or designing additional layers that focus on specific protected attributes. We introduce a simple and generic bias mitigation approach that prevents models from learning relationships between protected attributes and output variable by reducing mutual information between them. We demonstrate that our approach is effective in reducing bias with little or no drop in accuracy. We also show that the models trained with our learning framework become causally fair and insensitive to the values of protected attributes. Finally, we validate our approach by studying feature interactions between protected and non-protected attributes. We demonstrate that these interactions are significantly reduced when applying our bias mitigation.
Prescriptive and Descriptive Approaches to Machine-Learning Transparency
Apr 27, 2022
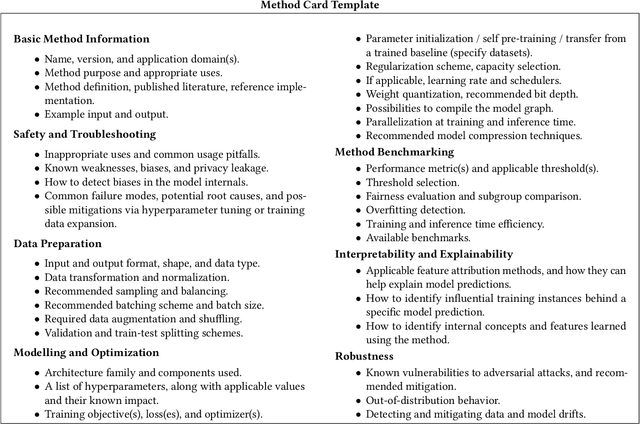
Specialized documentation techniques have been developed to communicate key facts about machine-learning (ML) systems and the datasets and models they rely on. Techniques such as Datasheets, FactSheets, and Model Cards have taken a mainly descriptive approach, providing various details about the system components. While the above information is essential for product developers and external experts to assess whether the ML system meets their requirements, other stakeholders might find it less actionable. In particular, ML engineers need guidance on how to mitigate potential shortcomings in order to fix bugs or improve the system's performance. We survey approaches that aim to provide such guidance in a prescriptive way. We further propose a preliminary approach, called Method Cards, which aims to increase the transparency and reproducibility of ML systems by providing prescriptive documentation of commonly-used ML methods and techniques. We showcase our proposal with an example in small object detection, and demonstrate how Method Cards can communicate key considerations for model developers. We further highlight avenues for improving the user experience of ML engineers based on Method Cards.