 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Probing Accuracy Saturates, Fragility Resolves: A Complementary Metric for LLM Pre-Training Analysis
Jun 09, 2026Standard linear probing declares a property "encoded" when a classifier on hidden states achieves high accuracy. The protocol works well on a snapshot but breaks across pre-training: probe accuracy saturates within the first few thousand steps, leaving most of training invisible to the instrument. We introduce fragility, a complementary per-layer metric defined as the activation-noise level at which probe accuracy collapses. Fragility is sensitive to both the margin of separability and the redundancy of representation, both of which keep evolving long after accuracy plateaus. Applied to open-checkpoint language models, fragility recovers structure that accuracy alone cannot see. Moralized representations emerge along a lexical $\to$ compositional gradient: lexical moral detection first, compositional moral encoding later. Because probe accuracy on its own tracks how lexically separable a dataset is, we establish the compositional encoding directly, by showing it transfers across construction types that share no contrast tokens. A layer-depth robustness gradient develops monotonically across training while accuracy stays flat. And matched fine-tuning corpora that produce identical probing accuracy leave distinct fragility fingerprints, showing that data curation reshapes probe robustness without changing probe accuracy. In every comparison we test, where probing accuracy returns a flat answer, fragility returns a structured one.
A Tour of Visualization Techniques for Computer Vision Datasets
Apr 19, 2022
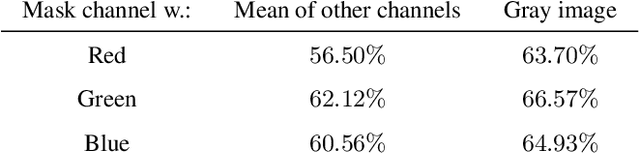

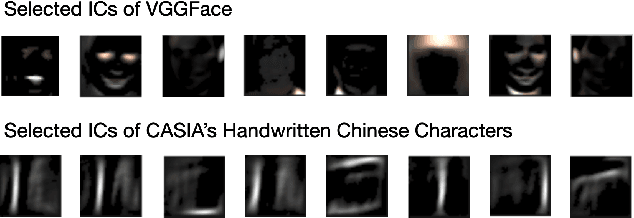
We survey a number of data visualization techniques for analyzing Computer Vision (CV) datasets. These techniques help us understand properties and latent patterns in such data, by applying dataset-level analysis. We present various examples of how such analysis helps predict the potential impact of the dataset properties on CV models and informs appropriate mitigation of their shortcomings. Finally, we explore avenues for further visualization techniques of different modalities of CV datasets as well as ones that are tailored to support specific CV tasks and analysis needs.
Investigating sanity checks for saliency maps with image and text classification
Jun 08, 2021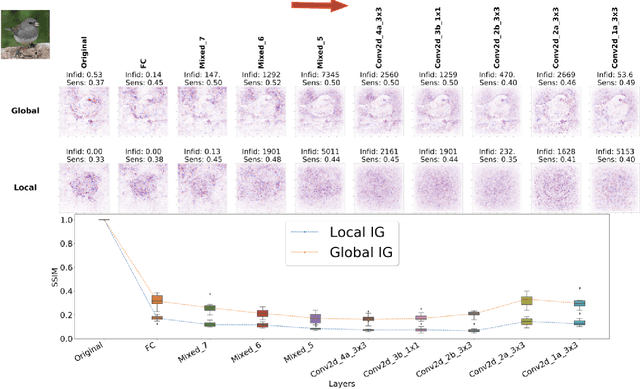
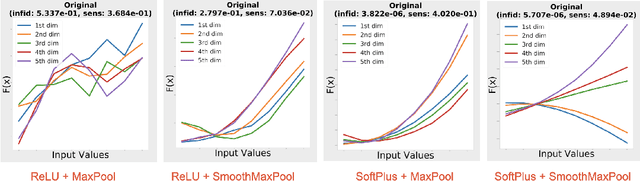
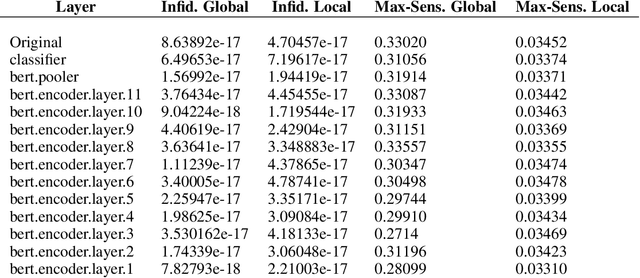
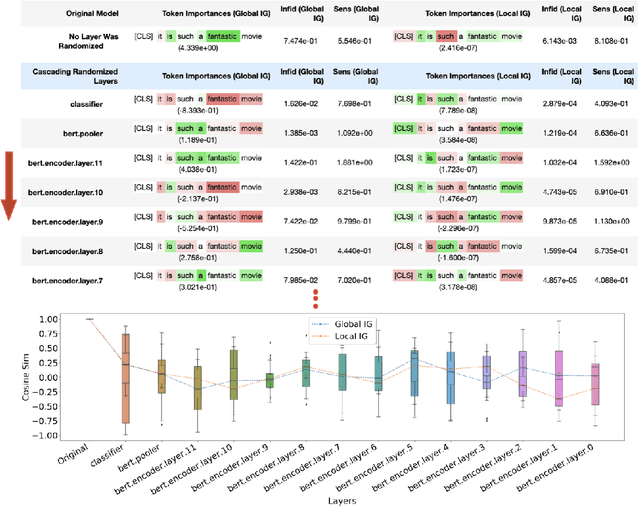
Saliency maps have shown to be both useful and misleading for explaining model predictions especially in the context of images. In this paper, we perform sanity checks for text modality and show that the conclusions made for image do not directly transfer to text. We also analyze the effects of the input multiplier in certain saliency maps using similarity scores, max-sensitivity and infidelity evaluation metrics. Our observations reveal that the input multiplier carries input's structural patterns in explanation maps, thus leading to similar results regardless of the choice of model parameters. We also show that the smoothness of a Neural Network (NN) function can affect the quality of saliency-based explanations. Our investigations reveal that replacing ReLUs with Softplus and MaxPool with smoother variants such as LogSumExp (LSE) can lead to explanations that are more reliable based on the infidelity evaluation metric.
Investigating Saturation Effects in Integrated Gradients
Oct 23, 2020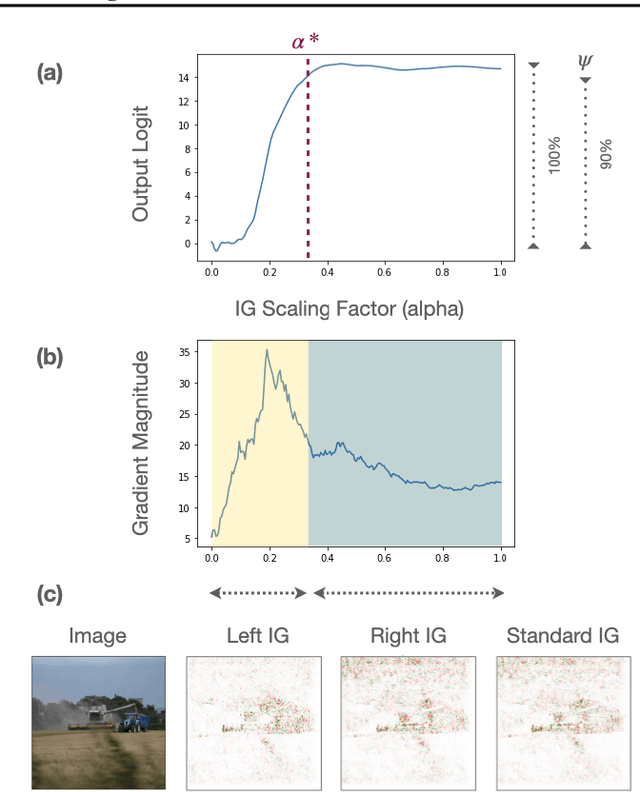
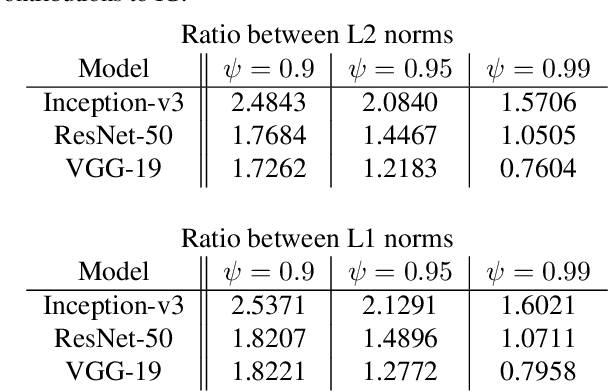

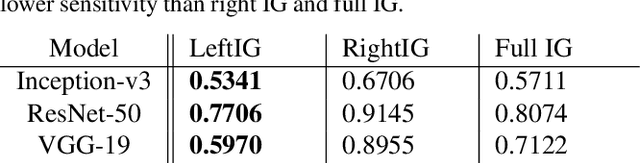
Integrated Gradients has become a popular method for post-hoc model interpretability. De-spite its popularity, the composition and relative impact of different regions of the integral path are not well understood. We explore these effects and find that gradients in saturated regions of this path, where model output changes minimally, contribute disproportionately to the computed attribution. We propose a variant of IntegratedGradients which primarily captures gradients in unsaturated regions and evaluate this method on ImageNet classification networks. We find that this attribution technique shows higher model faithfulness and lower sensitivity to noise com-pared with standard Integrated Gradients. A note-book illustrating our computations and results is available at https://github.com/vivekmig/captum-1/tree/ExpandedIG.
Mind the Pad -- CNNs can Develop Blind Spots
Oct 05, 2020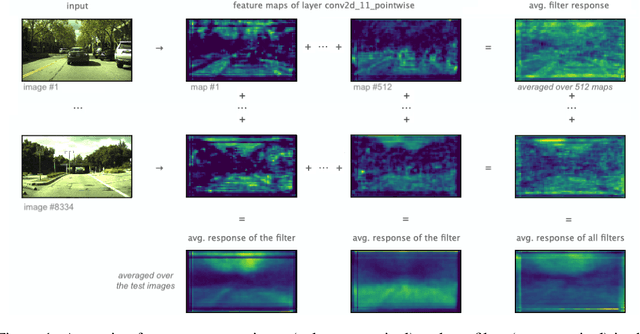

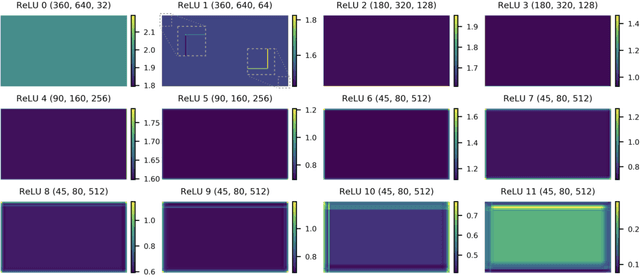

We show how feature maps in convolutional networks are susceptible to spatial bias. Due to a combination of architectural choices, the activation at certain locations is systematically elevated or weakened. The major source of this bias is the padding mechanism. Depending on several aspects of convolution arithmetic, this mechanism can apply the padding unevenly, leading to asymmetries in the learned weights. We demonstrate how such bias can be detrimental to certain tasks such as small object detection: the activation is suppressed if the stimulus lies in the impacted area, leading to blind spots and misdetection. We propose solutions to mitigate spatial bias and demonstrate how they can improve model accuracy.
Captum: A unified and generic model interpretability library for PyTorch
Sep 16, 2020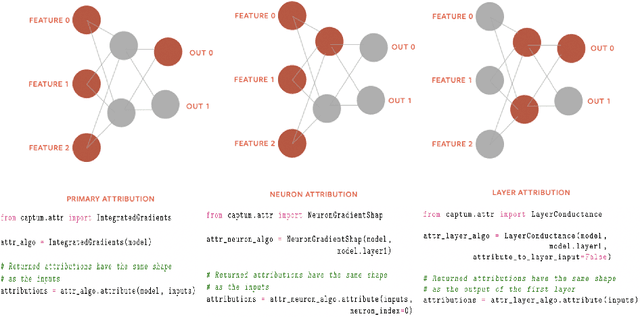

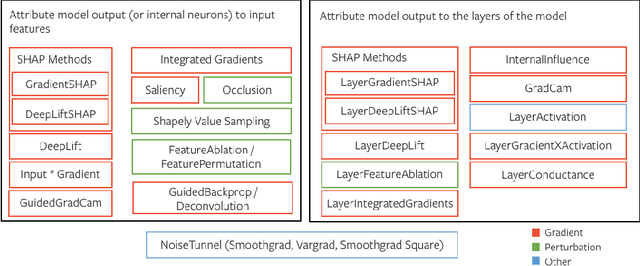
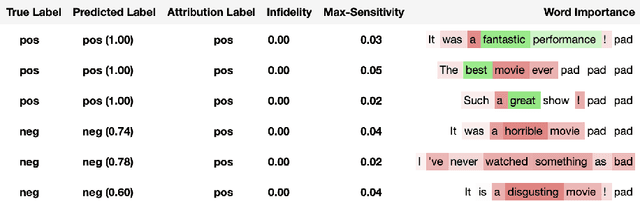
In this paper we introduce a novel, unified, open-source model interpretability library for PyTorch [12]. The library contains generic implementations of a number of gradient and perturbation-based attribution algorithms, also known as feature, neuron and layer importance algorithms, as well as a set of evaluation metrics for these algorithms. It can be used for both classification and non-classification models including graph-structured models built on Neural Networks (NN). In this paper we give a high-level overview of supported attribution algorithms and show how to perform memory-efficient and scalable computations. We emphasize that the three main characteristics of the library are multimodality, extensibility and ease of use. Multimodality supports different modality of inputs such as image, text, audio or video. Extensibility allows adding new algorithms and features. The library is also designed for easy understanding and use. Besides, we also introduce an interactive visualization tool called Captum Insights that is built on top of Captum library and allows sample-based model debugging and visualization using feature importance metrics.