 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating sanity checks for saliency maps with image and text classification
Paper and Code
Jun 08, 2021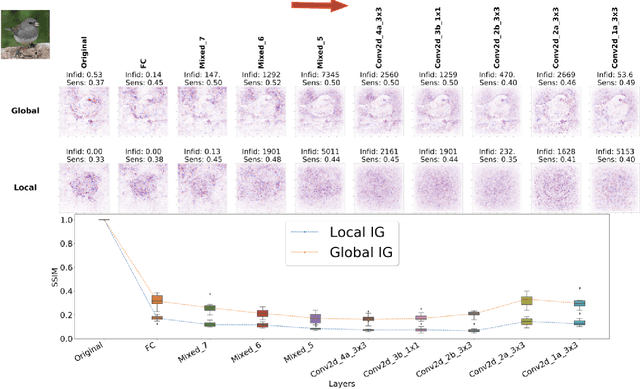
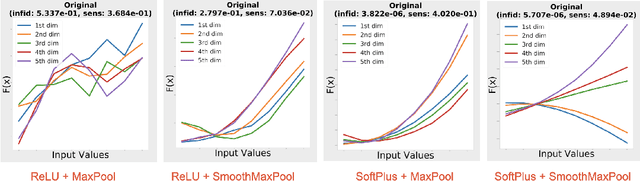
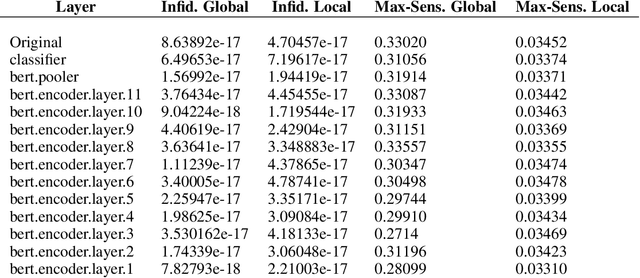
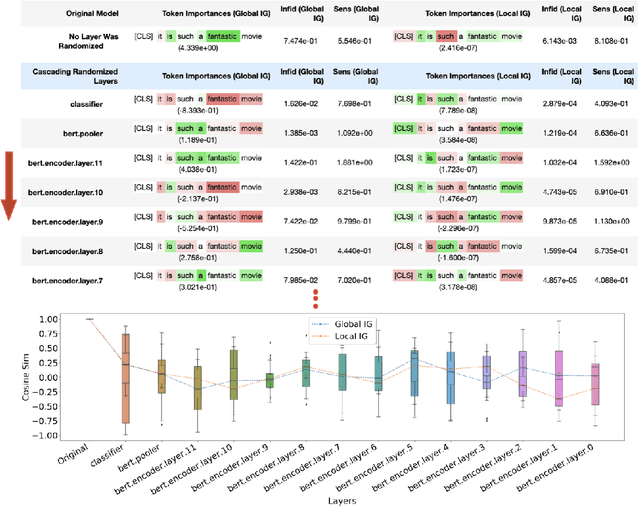
Saliency maps have shown to be both useful and misleading for explaining model predictions especially in the context of images. In this paper, we perform sanity checks for text modality and show that the conclusions made for image do not directly transfer to text. We also analyze the effects of the input multiplier in certain saliency maps using similarity scores, max-sensitivity and infidelity evaluation metrics. Our observations reveal that the input multiplier carries input's structural patterns in explanation maps, thus leading to similar results regardless of the choice of model parameters. We also show that the smoothness of a Neural Network (NN) function can affect the quality of saliency-based explanations. Our investigations reveal that replacing ReLUs with Softplus and MaxPool with smoother variants such as LogSumExp (LSE) can lead to explanations that are more reliable based on the infidelity evaluation metric.