 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning and Leveraging World Models in Visual Representation Learning
Paper and Code



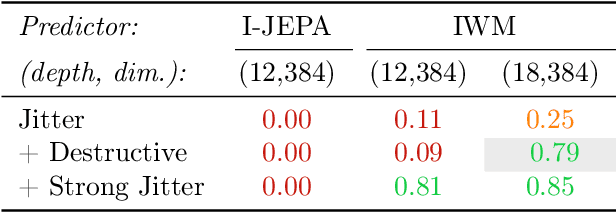
Joint-Embedding Predictive Architecture (JEPA) has emerged as a promising self-supervised approach that learns by leveraging a world model. While previously limited to predicting missing parts of an input, we explore how to generalize the JEPA prediction task to a broader set of corruptions. We introduce Image World Models, an approach that goes beyond masked image modeling and learns to predict the effect of global photometric transformations in latent space. We study the recipe of learning performant IWMs and show that it relies on three key aspects: conditioning, prediction difficulty, and capacity. Additionally, we show that the predictive world model learned by IWM can be adapted through finetuning to solve diverse tasks; a fine-tuned IWM world model matches or surpasses the performance of previous self-supervised methods. Finally, we show that learning with an IWM allows one to control the abstraction level of the learned representations, learning invariant representations such as contrastive methods, or equivariant representations such as masked image modelling.