 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnitary convolutions for learning on graphs and groups
Oct 07, 2024



Data with geometric structure is ubiquitous in machine learning often arising from fundamental symmetries in a domain, such as permutation-invariance in graphs and translation-invariance in images. Group-convolutional architectures, which encode symmetries as inductive bias, have shown great success in applications, but can suffer from instabilities as their depth increases and often struggle to learn long range dependencies in data. For instance, graph neural networks experience instability due to the convergence of node representations (over-smoothing), which can occur after only a few iterations of message-passing, reducing their effectiveness in downstream tasks. Here, we propose and study unitary group convolutions, which allow for deeper networks that are more stable during training. The main focus of the paper are graph neural networks, where we show that unitary graph convolutions provably avoid over-smoothing. Our experimental results confirm that unitary graph convolutional networks achieve competitive performance on benchmark datasets compared to state-of-the-art graph neural networks. We complement our analysis of the graph domain with the study of general unitary convolutions and analyze their role in enhancing stability in general group convolutional architectures.
Hardness of Learning Neural Networks under the Manifold Hypothesis
Jun 03, 2024



The manifold hypothesis presumes that high-dimensional data lies on or near a low-dimensional manifold. While the utility of encoding geometric structure has been demonstrated empirically, rigorous analysis of its impact on the learnability of neural networks is largely missing. Several recent results have established hardness results for learning feedforward and equivariant neural networks under i.i.d. Gaussian or uniform Boolean data distributions. In this paper, we investigate the hardness of learning under the manifold hypothesis. We ask which minimal assumptions on the curvature and regularity of the manifold, if any, render the learning problem efficiently learnable. We prove that learning is hard under input manifolds of bounded curvature by extending proofs of hardness in the SQ and cryptographic settings for Boolean data inputs to the geometric setting. On the other hand, we show that additional assumptions on the volume of the data manifold alleviate these fundamental limitations and guarantee learnability via a simple interpolation argument. Notable instances of this regime are manifolds which can be reliably reconstructed via manifold learning. Looking forward, we comment on and empirically explore intermediate regimes of manifolds, which have heterogeneous features commonly found in real world data.
On the hardness of learning under symmetries
Jan 03, 2024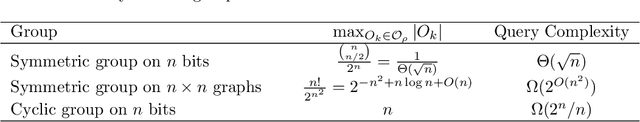
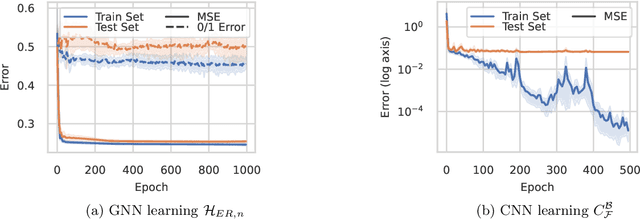
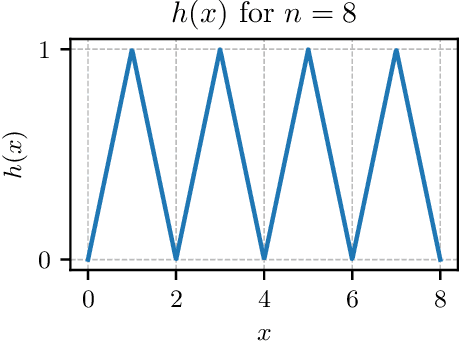
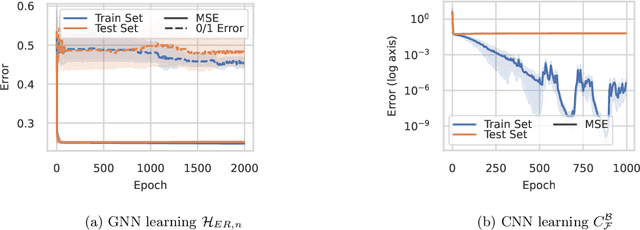
We study the problem of learning equivariant neural networks via gradient descent. The incorporation of known symmetries ("equivariance") into neural nets has empirically improved the performance of learning pipelines, in domains ranging from biology to computer vision. However, a rich yet separate line of learning theoretic research has demonstrated that actually learning shallow, fully-connected (i.e. non-symmetric) networks has exponential complexity in the correlational statistical query (CSQ) model, a framework encompassing gradient descent. In this work, we ask: are known problem symmetries sufficient to alleviate the fundamental hardness of learning neural nets with gradient descent? We answer this question in the negative. In particular, we give lower bounds for shallow graph neural networks, convolutional networks, invariant polynomials, and frame-averaged networks for permutation subgroups, which all scale either superpolynomially or exponentially in the relevant input dimension. Therefore, in spite of the significant inductive bias imparted via symmetry, actually learning the complete classes of functions represented by equivariant neural networks via gradient descent remains hard.
Self-Supervised Learning with Lie Symmetries for Partial Differential Equations
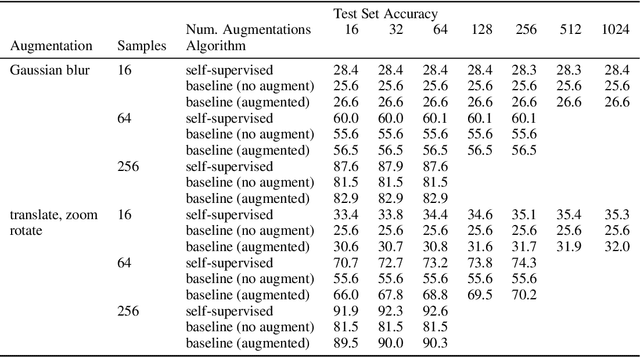
Jul 11, 2023Machine learning for differential equations paves the way for computationally efficient alternatives to numerical solvers, with potentially broad impacts in science and engineering. Though current algorithms typically require simulated training data tailored to a given setting, one may instead wish to learn useful information from heterogeneous sources, or from real dynamical systems observations that are messy or incomplete. In this work, we learn general-purpose representations of PDEs from heterogeneous data by implementing joint embedding methods for self-supervised learning (SSL), a framework for unsupervised representation learning that has had notable success in computer vision. Our representation outperforms baseline approaches to invariant tasks, such as regressing the coefficients of a PDE, while also improving the time-stepping performance of neural solvers. We hope that our proposed methodology will prove useful in the eventual development of general-purpose foundation models for PDEs.
Equivariant Polynomials for Graph Neural Networks
Feb 22, 2023Graph Neural Networks (GNN) are inherently limited in their expressive power. Recent seminal works (Xu et al., 2019; Morris et al., 2019b) introduced the Weisfeiler-Lehman (WL) hierarchy as a measure of expressive power. Although this hierarchy has propelled significant advances in GNN analysis and architecture developments, it suffers from several significant limitations. These include a complex definition that lacks direct guidance for model improvement and a WL hierarchy that is too coarse to study current GNNs. This paper introduces an alternative expressive power hierarchy based on the ability of GNNs to calculate equivariant polynomials of a certain degree. As a first step, we provide a full characterization of all equivariant graph polynomials by introducing a concrete basis, significantly generalizing previous results. Each basis element corresponds to a specific multi-graph, and its computation over some graph data input corresponds to a tensor contraction problem. Second, we propose algorithmic tools for evaluating the expressiveness of GNNs using tensor contraction sequences, and calculate the expressive power of popular GNNs. Finally, we enhance the expressivity of common GNN architectures by adding polynomial features or additional operations / aggregations inspired by our theory. These enhanced GNNs demonstrate state-of-the-art results in experiments across multiple graph learning benchmarks.
The SSL Interplay: Augmentations, Inductive Bias, and Generalization
Feb 06, 2023

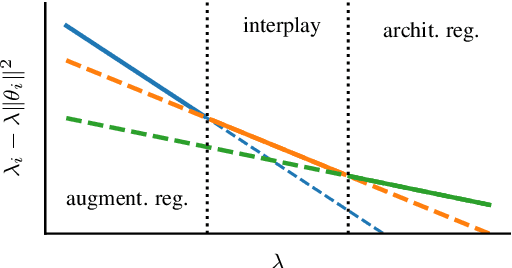
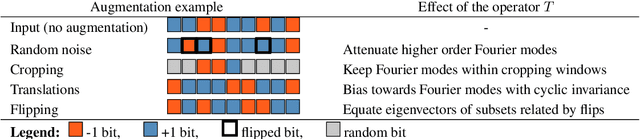
Self-supervised learning (SSL) has emerged as a powerful framework to learn representations from raw data without supervision. Yet in practice, engineers face issues such as instability in tuning optimizers and collapse of representations during training. Such challenges motivate the need for a theory to shed light on the complex interplay between the choice of data augmentation, network architecture, and training algorithm. We study such an interplay with a precise analysis of generalization performance on both pretraining and downstream tasks in a theory friendly setup, and highlight several insights for SSL practitioners that arise from our theory.
Joint Embedding Self-Supervised Learning in the Kernel Regime
Sep 29, 2022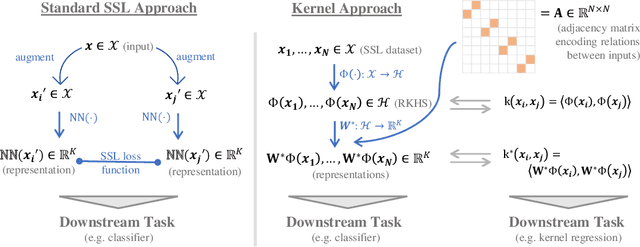
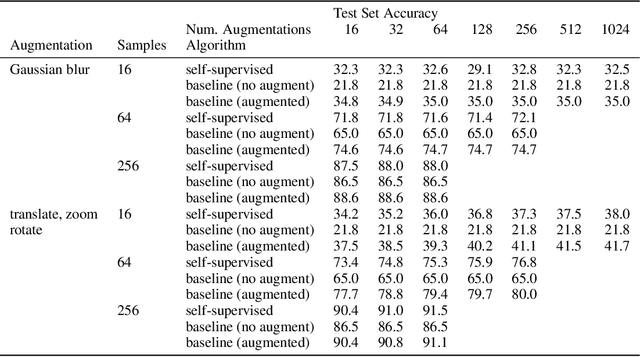
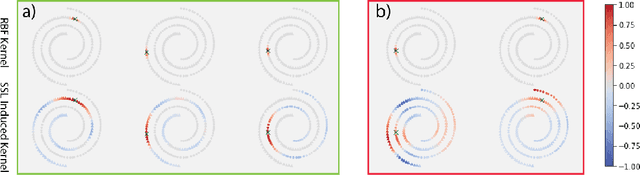
The fundamental goal of self-supervised learning (SSL) is to produce useful representations of data without access to any labels for classifying the data. Modern methods in SSL, which form representations based on known or constructed relationships between samples, have been particularly effective at this task. Here, we aim to extend this framework to incorporate algorithms based on kernel methods where embeddings are constructed by linear maps acting on the feature space of a kernel. In this kernel regime, we derive methods to find the optimal form of the output representations for contrastive and non-contrastive loss functions. This procedure produces a new representation space with an inner product denoted as the induced kernel which generally correlates points which are related by an augmentation in kernel space and de-correlates points otherwise. We analyze our kernel model on small datasets to identify common features of self-supervised learning algorithms and gain theoretical insights into their performance on downstream tasks.
Implicit Bias of Linear Equivariant Networks
Oct 12, 2021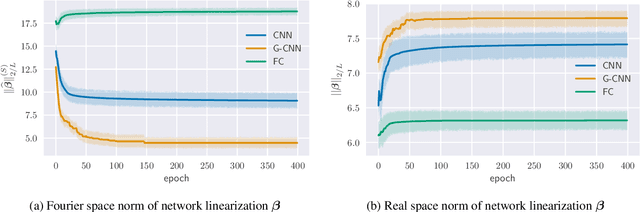
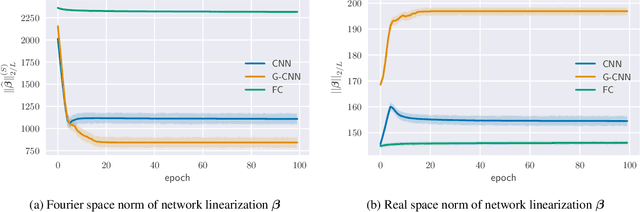
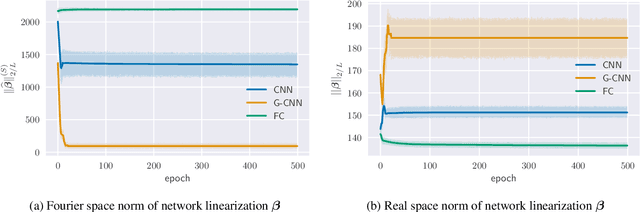
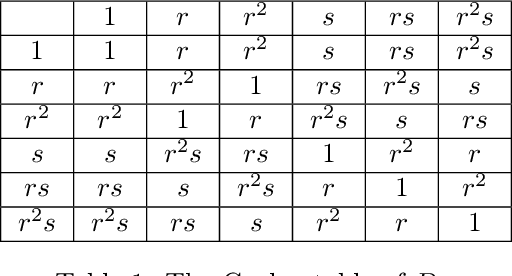
Group equivariant convolutional neural networks (G-CNNs) are generalizations of convolutional neural networks (CNNs) which excel in a wide range of scientific and technical applications by explicitly encoding group symmetries, such as rotations and permutations, in their architectures. Although the success of G-CNNs is driven by the explicit symmetry bias of their convolutional architecture, a recent line of work has proposed that the implicit bias of training algorithms on a particular parameterization (or architecture) is key to understanding generalization for overparameterized neural nets. In this context, we show that $L$-layer full-width linear G-CNNs trained via gradient descent in a binary classification task converge to solutions with low-rank Fourier matrix coefficients, regularized by the $2/L$-Schatten matrix norm. Our work strictly generalizes previous analysis on the implicit bias of linear CNNs to linear G-CNNs over all finite groups, including the challenging setting of non-commutative symmetry groups (such as permutations). We validate our theorems via experiments on a variety of groups and empirically explore more realistic nonlinear networks, which locally capture similar regularization patterns. Finally, we provide intuitive interpretations of our Fourier space implicit regularization results in real space via uncertainty principles.
Quantum algorithms for group convolution, cross-correlation, and equivariant transformations
Sep 23, 2021
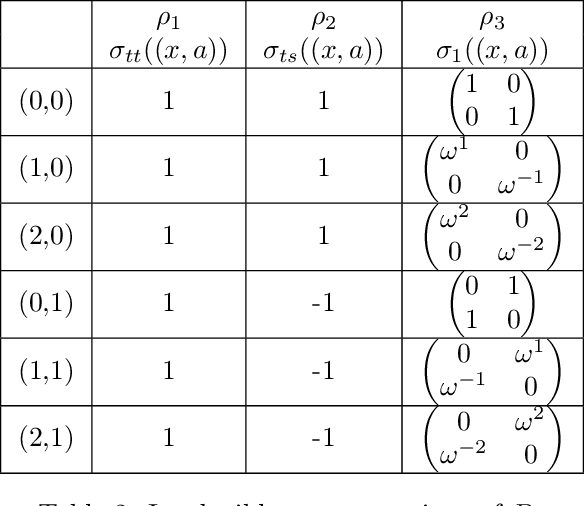
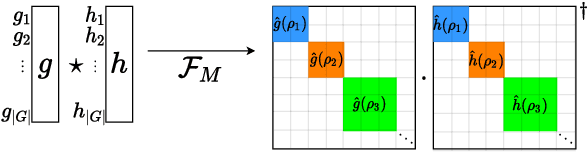
Group convolutions and cross-correlations, which are equivariant to the actions of group elements, are commonly used in mathematics to analyze or take advantage of symmetries inherent in a given problem setting. Here, we provide efficient quantum algorithms for performing linear group convolutions and cross-correlations on data stored as quantum states. Runtimes for our algorithms are logarithmic in the dimension of the group thus offering an exponential speedup compared to classical algorithms when input data is provided as a quantum state and linear operations are well conditioned. Motivated by the rich literature on quantum algorithms for solving algebraic problems, our theoretical framework opens a path for quantizing many algorithms in machine learning and numerical methods that employ group operations.
Adversarial robustness guarantees for random deep neural networks
Apr 13, 2020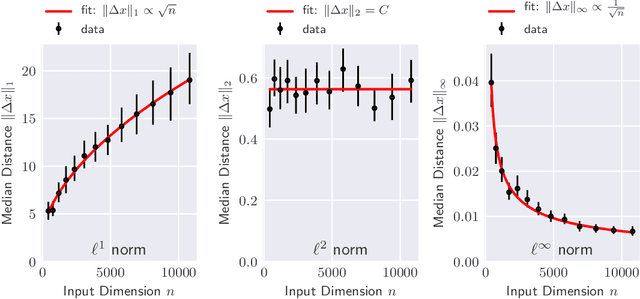
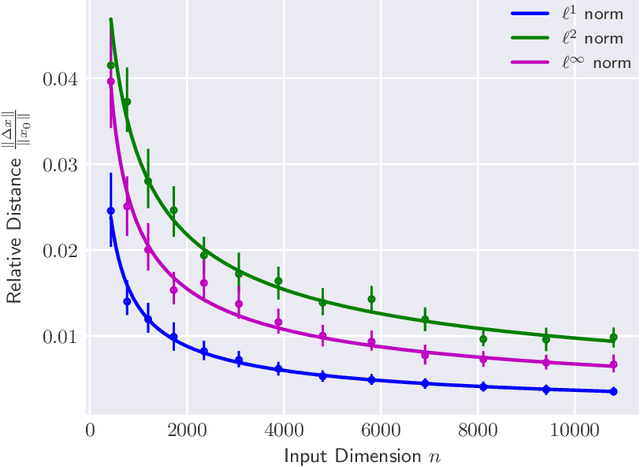
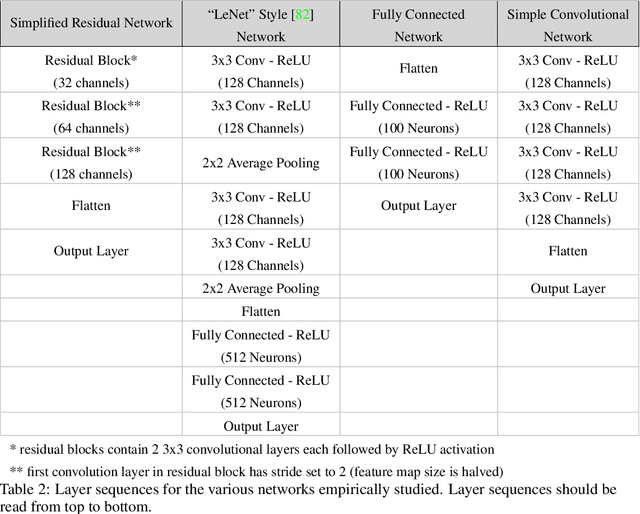
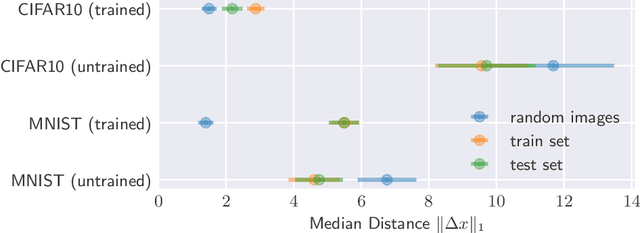
The reliability of most deep learning algorithms is fundamentally challenged by the existence of adversarial examples, which are incorrectly classified inputs that are extremely close to a correctly classified input. We study adversarial examples for deep neural networks with random weights and biases and prove that the $\ell^1$ distance of any given input from the classification boundary scales at least as $\sqrt{n}$, where $n$ is the dimension of the input. We also extend our proof to cover all the $\ell^p$ norms. Our results constitute a fundamental advance in the study of adversarial examples, and encompass a wide variety of architectures, which include any combination of convolutional or fully connected layers with skipped connections and pooling. We validate our results with experiments on both random deep neural networks and deep neural networks trained on the MNIST and CIFAR10 datasets. Given the results of our experiments on MNIST and CIFAR10, we conjecture that the proof of our adversarial robustness guarantee can be extended to trained deep neural networks. This extension will open the way to a thorough theoretical study of neural network robustness by classifying the relation between network architecture and adversarial distance.