 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Diversity, Novelty, and Popularity Bias in ChatGPT's Recommendations
Jan 05, 2026ChatGPT has emerged as a versatile tool, demonstrating capabilities across diverse domains. Given these successes, the Recommender Systems (RSs) community has begun investigating its applications within recommendation scenarios primarily focusing on accuracy. While the integration of ChatGPT into RSs has garnered significant attention, a comprehensive analysis of its performance across various dimensions remains largely unexplored. Specifically, the capabilities of providing diverse and novel recommendations or exploring potential biases such as popularity bias have not been thoroughly examined. As the use of these models continues to expand, understanding these aspects is crucial for enhancing user satisfaction and achieving long-term personalization. This study investigates the recommendations provided by ChatGPT-3.5 and ChatGPT-4 by assessing ChatGPT's capabilities in terms of diversity, novelty, and popularity bias. We evaluate these models on three distinct datasets and assess their performance in Top-N recommendation and cold-start scenarios. The findings reveal that ChatGPT-4 matches or surpasses traditional recommenders, demonstrating the ability to balance novelty and diversity in recommendations. Furthermore, in the cold-start scenario, ChatGPT models exhibit superior performance in both accuracy and novelty, suggesting they can be particularly beneficial for new users. This research highlights the strengths and limitations of ChatGPT's recommendations, offering new perspectives on the capacity of these models to provide recommendations beyond accuracy-focused metrics.
Exploring Approaches for Detecting Memorization of Recommender System Data in Large Language Models
Jan 05, 2026Large Language Models (LLMs) are increasingly applied in recommendation scenarios due to their strong natural language understanding and generation capabilities. However, they are trained on vast corpora whose contents are not publicly disclosed, raising concerns about data leakage. Recent work has shown that the MovieLens-1M dataset is memorized by both the LLaMA and OpenAI model families, but the extraction of such memorized data has so far relied exclusively on manual prompt engineering. In this paper, we pose three main questions: Is it possible to enhance manual prompting? Can LLM memorization be detected through methods beyond manual prompting? And can the detection of data leakage be automated? To address these questions, we evaluate three approaches: (i) jailbreak prompt engineering; (ii) unsupervised latent knowledge discovery, probing internal activations via Contrast-Consistent Search (CCS) and Cluster-Norm; and (iii) Automatic Prompt Engineering (APE), which frames prompt discovery as a meta-learning process that iteratively refines candidate instructions. Experiments on MovieLens-1M using LLaMA models show that jailbreak prompting does not improve the retrieval of memorized items and remains inconsistent; CCS reliably distinguishes genuine from fabricated movie titles but fails on numerical user and rating data; and APE retrieves item-level information with moderate success yet struggles to recover numerical interactions. These findings suggest that automatically optimizing prompts is the most promising strategy for extracting memorized samples.
Do Recommender Systems Really Leverage Multimodal Content? A Comprehensive Analysis on Multimodal Representations for Recommendation
Aug 06, 2025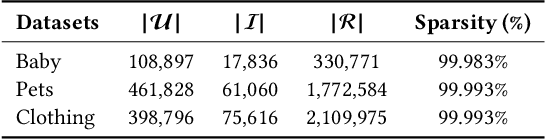

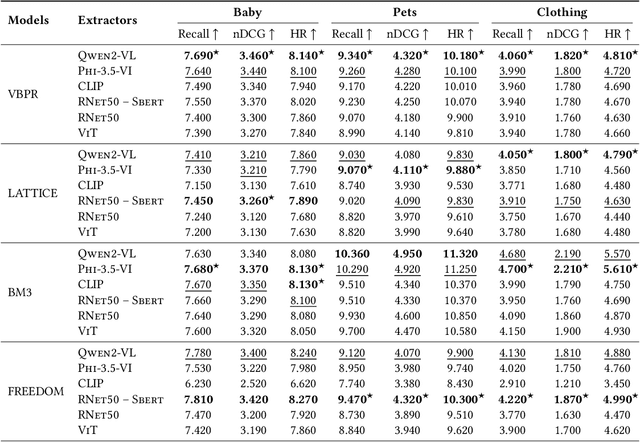
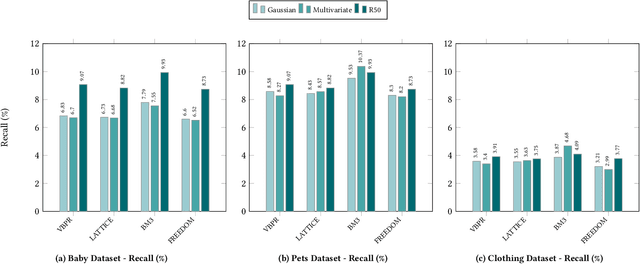
Multimodal Recommender Systems aim to improve recommendation accuracy by integrating heterogeneous content, such as images and textual metadata. While effective, it remains unclear whether their gains stem from true multimodal understanding or increased model complexity. This work investigates the role of multimodal item embeddings, emphasizing the semantic informativeness of the representations. Initial experiments reveal that embeddings from standard extractors (e.g., ResNet50, Sentence-Bert) enhance performance, but rely on modality-specific encoders and ad hoc fusion strategies that lack control over cross-modal alignment. To overcome these limitations, we leverage Large Vision-Language Models (LVLMs) to generate multimodal-by-design embeddings via structured prompts. This approach yields semantically aligned representations without requiring any fusion. Experiments across multiple settings show notable performance improvements. Furthermore, LVLMs embeddings offer a distinctive advantage: they can be decoded into structured textual descriptions, enabling direct assessment of their multimodal comprehension. When such descriptions are incorporated as side content into recommender systems, they improve recommendation performance, empirically validating the semantic depth and alignment encoded within LVLMs outputs. Our study highlights the importance of semantically rich representations and positions LVLMs as a compelling foundation for building robust and meaningful multimodal representations in recommendation tasks.
LLaMAs Have Feelings Too: Unveiling Sentiment and Emotion Representations in LLaMA Models Through Probing
May 22, 2025Large Language Models (LLMs) have rapidly become central to NLP, demonstrating their ability to adapt to various tasks through prompting techniques, including sentiment analysis. However, we still have a limited understanding of how these models capture sentiment-related information. This study probes the hidden layers of Llama models to pinpoint where sentiment features are most represented and to assess how this affects sentiment analysis. Using probe classifiers, we analyze sentiment encoding across layers and scales, identifying the layers and pooling methods that best capture sentiment signals. Our results show that sentiment information is most concentrated in mid-layers for binary polarity tasks, with detection accuracy increasing up to 14% over prompting techniques. Additionally, we find that in decoder-only models, the last token is not consistently the most informative for sentiment encoding. Finally, this approach enables sentiment tasks to be performed with memory requirements reduced by an average of 57%. These insights contribute to a broader understanding of sentiment in LLMs, suggesting layer-specific probing as an effective approach for sentiment tasks beyond prompting, with potential to enhance model utility and reduce memory requirements.
Do LLMs Memorize Recommendation Datasets? A Preliminary Study on MovieLens-1M
May 15, 2025Large Language Models (LLMs) have become increasingly central to recommendation scenarios due to their remarkable natural language understanding and generation capabilities. Although significant research has explored the use of LLMs for various recommendation tasks, little effort has been dedicated to verifying whether they have memorized public recommendation dataset as part of their training data. This is undesirable because memorization reduces the generalizability of research findings, as benchmarking on memorized datasets does not guarantee generalization to unseen datasets. Furthermore, memorization can amplify biases, for example, some popular items may be recommended more frequently than others. In this work, we investigate whether LLMs have memorized public recommendation datasets. Specifically, we examine two model families (GPT and Llama) across multiple sizes, focusing on one of the most widely used dataset in recommender systems: MovieLens-1M. First, we define dataset memorization as the extent to which item attributes, user profiles, and user-item interactions can be retrieved by prompting the LLMs. Second, we analyze the impact of memorization on recommendation performance. Lastly, we examine whether memorization varies across model families and model sizes. Our results reveal that all models exhibit some degree of memorization of MovieLens-1M, and that recommendation performance is related to the extent of memorization. We have made all the code publicly available at: https://github.com/sisinflab/LLM-MemoryInspector
A System for Automated Unit Test Generation Using Large Language Models and Assessment of Generated Test Suites
Aug 14, 2024



Unit tests represent the most basic level of testing within the software testing lifecycle and are crucial to ensuring software correctness. Designing and creating unit tests is a costly and labor-intensive process that is ripe for automation. Recently, Large Language Models (LLMs) have been applied to various aspects of software development, including unit test generation. Although several empirical studies evaluating LLMs' capabilities in test code generation exist, they primarily focus on simple scenarios, such as the straightforward generation of unit tests for individual methods. These evaluations often involve independent and small-scale test units, providing a limited view of LLMs' performance in real-world software development scenarios. Moreover, previous studies do not approach the problem at a suitable scale for real-life applications. Generated unit tests are often evaluated via manual integration into the original projects, a process that limits the number of tests executed and reduces overall efficiency. To address these gaps, we have developed an approach for generating and evaluating more real-life complexity test suites. Our approach focuses on class-level test code generation and automates the entire process from test generation to test assessment. In this work, we present \textsc{AgoneTest}: an automated system for generating test suites for Java projects and a comprehensive and principled methodology for evaluating the generated test suites. Starting from a state-of-the-art dataset (i.e., \textsc{Methods2Test}), we built a new dataset for comparing human-written tests with those generated by LLMs. Our key contributions include a scalable automated software system, a new dataset, and a detailed methodology for evaluating test quality.
Evaluating ChatGPT as a Recommender System: A Rigorous Approach
Sep 07, 2023



Recent popularity surrounds large AI language models due to their impressive natural language capabilities. They contribute significantly to language-related tasks, including prompt-based learning, making them valuable for various specific tasks. This approach unlocks their full potential, enhancing precision and generalization. Research communities are actively exploring their applications, with ChatGPT receiving recognition. Despite extensive research on large language models, their potential in recommendation scenarios still needs to be explored. This study aims to fill this gap by investigating ChatGPT's capabilities as a zero-shot recommender system. Our goals include evaluating its ability to use user preferences for recommendations, reordering existing recommendation lists, leveraging information from similar users, and handling cold-start situations. We assess ChatGPT's performance through comprehensive experiments using three datasets (MovieLens Small, Last.FM, and Facebook Book). We compare ChatGPT's performance against standard recommendation algorithms and other large language models, such as GPT-3.5 and PaLM-2. To measure recommendation effectiveness, we employ widely-used evaluation metrics like Mean Average Precision (MAP), Recall, Precision, F1, normalized Discounted Cumulative Gain (nDCG), Item Coverage, Expected Popularity Complement (EPC), Average Coverage of Long Tail (ACLT), Average Recommendation Popularity (ARP), and Popularity-based Ranking-based Equal Opportunity (PopREO). Through thoroughly exploring ChatGPT's abilities in recommender systems, our study aims to contribute to the growing body of research on the versatility and potential applications of large language models. Our experiment code is available on the GitHub repository: https://github.com/sisinflab/Recommender-ChatGPT
Counterfactual Reasoning for Bias Evaluation and Detection in a Fairness under Unawareness setting
Feb 16, 2023



Current AI regulations require discarding sensitive features (e.g., gender, race, religion) in the algorithm's decision-making process to prevent unfair outcomes. However, even without sensitive features in the training set, algorithms can persist in discrimination. Indeed, when sensitive features are omitted (fairness under unawareness), they could be inferred through non-linear relations with the so called proxy features. In this work, we propose a way to reveal the potential hidden bias of a machine learning model that can persist even when sensitive features are discarded. This study shows that it is possible to unveil whether the black-box predictor is still biased by exploiting counterfactual reasoning. In detail, when the predictor provides a negative classification outcome, our approach first builds counterfactual examples for a discriminated user category to obtain a positive outcome. Then, the same counterfactual samples feed an external classifier (that targets a sensitive feature) that reveals whether the modifications to the user characteristics needed for a positive outcome moved the individual to the non-discriminated group. When this occurs, it could be a warning sign for discriminatory behavior in the decision process. Furthermore, we leverage the deviation of counterfactuals from the original sample to determine which features are proxies of specific sensitive information. Our experiments show that, even if the model is trained without sensitive features, it often suffers discriminatory biases.
Counterfactual Fair Opportunity: Measuring Decision Model Fairness with Counterfactual Reasoning
Feb 16, 2023



The increasing application of Artificial Intelligence and Machine Learning models poses potential risks of unfair behavior and, in light of recent regulations, has attracted the attention of the research community. Several researchers focused on seeking new fairness definitions or developing approaches to identify biased predictions. However, none try to exploit the counterfactual space to this aim. In that direction, the methodology proposed in this work aims to unveil unfair model behaviors using counterfactual reasoning in the case of fairness under unawareness setting. A counterfactual version of equal opportunity named counterfactual fair opportunity is defined and two novel metrics that analyze the sensitive information of counterfactual samples are introduced. Experimental results on three different datasets show the efficacy of our methodologies and our metrics, disclosing the unfair behavior of classic machine learning and debiasing models.
MAFUS: a Framework to predict mortality risk in MAFLD subjects
Jan 17, 2023



Metabolic (dysfunction) associated fatty liver disease (MAFLD) establishes new criteria for diagnosing fatty liver disease independent of alcohol consumption and concurrent viral hepatitis infection. However, the long-term outcome of MAFLD subjects is sparse. Few articles are focused on mortality in MAFLD subjects, and none investigate how to predict a fatal outcome. In this paper, we propose an artificial intelligence-based framework named MAFUS that physicians can use for predicting mortality in MAFLD subjects. The framework uses data from various anthropometric and biochemical sources based on Machine Learning (ML) algorithms. The framework has been tested on a state-of-the-art dataset on which five ML algorithms are trained. Support Vector Machines resulted in being the best model. Furthermore, an Explainable Artificial Intelligence (XAI) analysis has been performed to understand the SVM diagnostic reasoning and the contribution of each feature to the prediction. The MAFUS framework is easy to apply, and the required parameters are readily available in the dataset.