 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Prompt Evaluation: Systematic Benchmarking of Guardrails Against Prompt Input Attacks on LLMs
Feb 21, 2025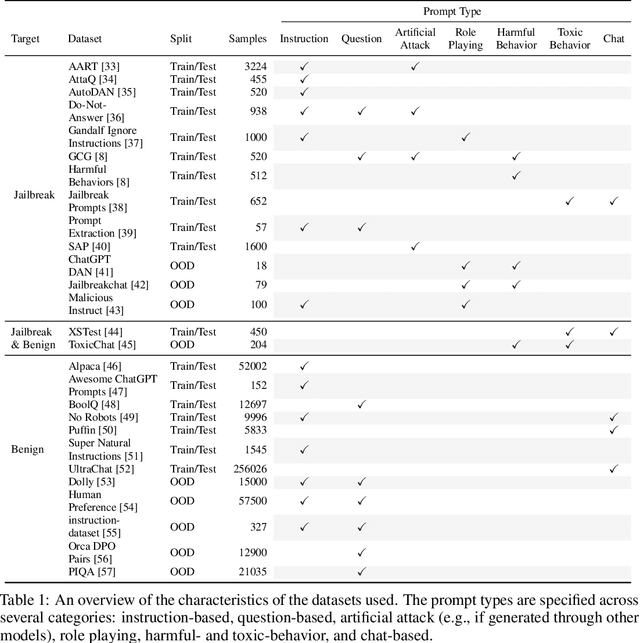
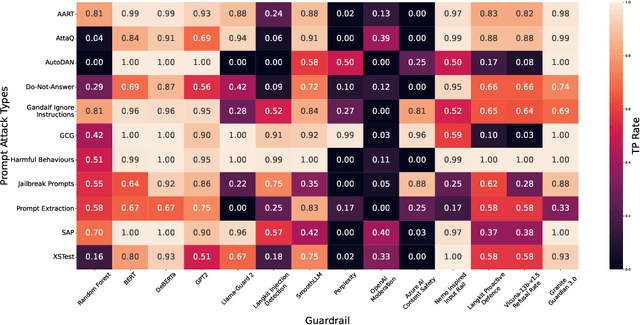
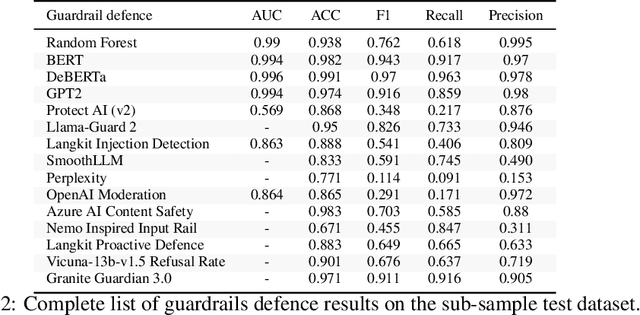
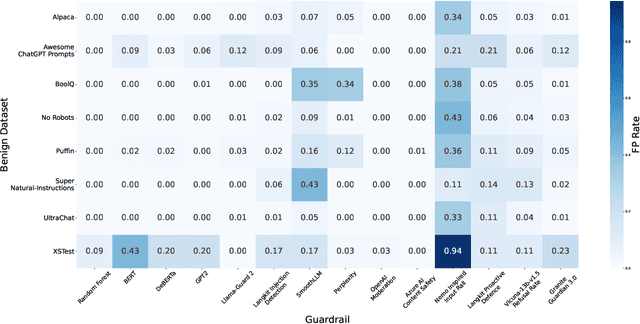
As large language models (LLMs) become integrated into everyday applications, ensuring their robustness and security is increasingly critical. In particular, LLMs can be manipulated into unsafe behaviour by prompts known as jailbreaks. The variety of jailbreak styles is growing, necessitating the use of external defences known as guardrails. While many jailbreak defences have been proposed, not all defences are able to handle new out-of-distribution attacks due to the narrow segment of jailbreaks used to align them. Moreover, the lack of systematisation around defences has created significant gaps in their practical application. In this work, we perform systematic benchmarking across 15 different defences, considering a broad swathe of malicious and benign datasets. We find that there is significant performance variation depending on the style of jailbreak a defence is subject to. Additionally, we show that based on current datasets available for evaluation, simple baselines can display competitive out-of-distribution performance compared to many state-of-the-art defences. Code is available at https://github.com/IBM/Adversarial-Prompt-Evaluation.
Towards Assurance of LLM Adversarial Robustness using Ontology-Driven Argumentation
Oct 10, 2024



Despite the impressive adaptability of large language models (LLMs), challenges remain in ensuring their security, transparency, and interpretability. Given their susceptibility to adversarial attacks, LLMs need to be defended with an evolving combination of adversarial training and guardrails. However, managing the implicit and heterogeneous knowledge for continuously assuring robustness is difficult. We introduce a novel approach for assurance of the adversarial robustness of LLMs based on formal argumentation. Using ontologies for formalization, we structure state-of-the-art attacks and defenses, facilitating the creation of a human-readable assurance case, and a machine-readable representation. We demonstrate its application with examples in English language and code translation tasks, and provide implications for theory and practice, by targeting engineers, data scientists, users, and auditors.
Towards Assuring EU AI Act Compliance and Adversarial Robustness of LLMs
Oct 04, 2024


Large language models are prone to misuse and vulnerable to security threats, raising significant safety and security concerns. The European Union's Artificial Intelligence Act seeks to enforce AI robustness in certain contexts, but faces implementation challenges due to the lack of standards, complexity of LLMs and emerging security vulnerabilities. Our research introduces a framework using ontologies, assurance cases, and factsheets to support engineers and stakeholders in understanding and documenting AI system compliance and security regarding adversarial robustness. This approach aims to ensure that LLMs adhere to regulatory standards and are equipped to counter potential threats.
Knowledge-Augmented Reasoning for EUAIA Compliance and Adversarial Robustness of LLMs
Oct 04, 2024



The EU AI Act (EUAIA) introduces requirements for AI systems which intersect with the processes required to establish adversarial robustness. However, given the ambiguous language of regulation and the dynamicity of adversarial attacks, developers of systems with highly complex models such as LLMs may find their effort to be duplicated without the assurance of having achieved either compliance or robustness. This paper presents a functional architecture that focuses on bridging the two properties, by introducing components with clear reference to their source. Taking the detection layer recommended by the literature, and the reporting layer required by the law, we aim to support developers and auditors with a reasoning layer based on knowledge augmentation (rules, assurance cases, contextual mappings). Our findings demonstrate a novel direction for ensuring LLMs deployed in the EU are both compliant and adversarially robust, which underpin trustworthiness.
Developing Assurance Cases for Adversarial Robustness and Regulatory Compliance in LLMs
Oct 04, 2024


This paper presents an approach to developing assurance cases for adversarial robustness and regulatory compliance in large language models (LLMs). Focusing on both natural and code language tasks, we explore the vulnerabilities these models face, including adversarial attacks based on jailbreaking, heuristics, and randomization. We propose a layered framework incorporating guardrails at various stages of LLM deployment, aimed at mitigating these attacks and ensuring compliance with the EU AI Act. Our approach includes a meta-layer for dynamic risk management and reasoning, crucial for addressing the evolving nature of LLM vulnerabilities. We illustrate our method with two exemplary assurance cases, highlighting how different contexts demand tailored strategies to ensure robust and compliant AI systems.
Boundary Adversarial Examples Against Adversarial Overfitting
Nov 25, 2022



Standard adversarial training approaches suffer from robust overfitting where the robust accuracy decreases when models are adversarially trained for too long. The origin of this problem is still unclear and conflicting explanations have been reported, i.e., memorization effects induced by large loss data or because of small loss data and growing differences in loss distribution of training samples as the adversarial training progresses. Consequently, several mitigation approaches including early stopping, temporal ensembling and weight perturbations on small loss data have been proposed to mitigate the effect of robust overfitting. However, a side effect of these strategies is a larger reduction in clean accuracy compared to standard adversarial training. In this paper, we investigate if these mitigation approaches are complimentary to each other in improving adversarial training performance. We further propose the use of helper adversarial examples that can be obtained with minimal cost in the adversarial example generation, and show how they increase the clean accuracy in the existing approaches without compromising the robust accuracy.
Automated Robustness with Adversarial Training as a Post-Processing Step
Sep 06, 2021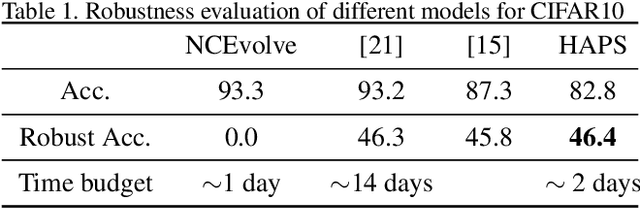
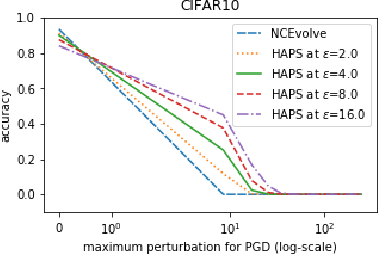
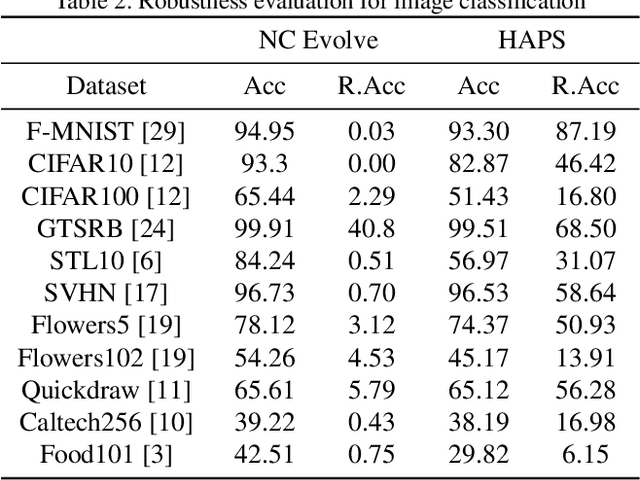
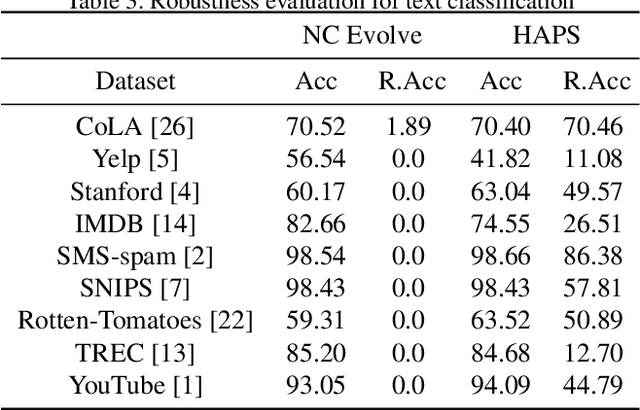
Adversarial training is a computationally expensive task and hence searching for neural network architectures with robustness as the criterion can be challenging. As a step towards practical automation, this work explores the efficacy of a simple post processing step in yielding robust deep learning model. To achieve this, we adopt adversarial training as a post-processing step for optimised network architectures obtained from a neural architecture search algorithm. Specific policies are adopted for tuning the hyperparameters of the different steps, resulting in a fully automated pipeline for generating adversarially robust deep learning models. We evidence the usefulness of the proposed pipeline with extensive experimentation across 11 image classification and 9 text classification tasks.
FAT: Federated Adversarial Training
Dec 03, 2020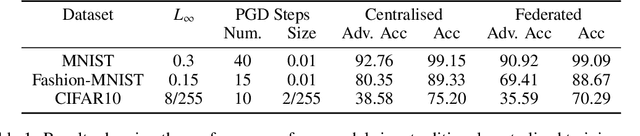
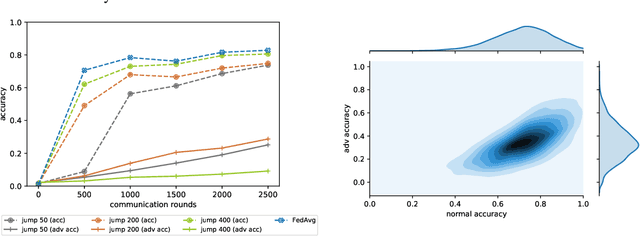
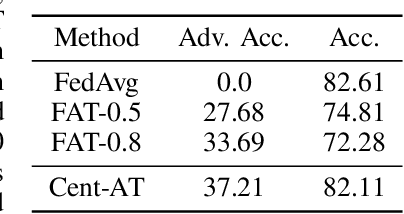
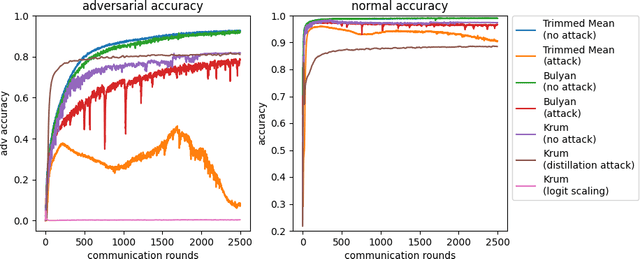
Federated learning (FL) is one of the most important paradigms addressing privacy and data governance issues in machine learning (ML). Adversarial training has emerged, so far, as the most promising approach against evasion threats on ML models. In this paper, we take the first known steps towards federated adversarial training (FAT) combining both methods to reduce the threat of evasion during inference while preserving the data privacy during training. We investigate the effectiveness of the FAT protocol for idealised federated settings using MNIST, Fashion-MNIST, and CIFAR10, and provide first insights on stabilising the training on the LEAF benchmark dataset which specifically emulates a federated learning environment. We identify challenges with this natural extension of adversarial training with regards to achieved adversarial robustness and further examine the idealised settings in the presence of clients undermining model convergence. We find that Trimmed Mean and Bulyan defences can be compromised and we were able to subvert Krum with a novel distillation based attack which presents an apparently "robust" model to the defender while in fact the model fails to provide robustness against simple attack modifications.
How can AI Automate End-to-End Data Science?
Oct 22, 2019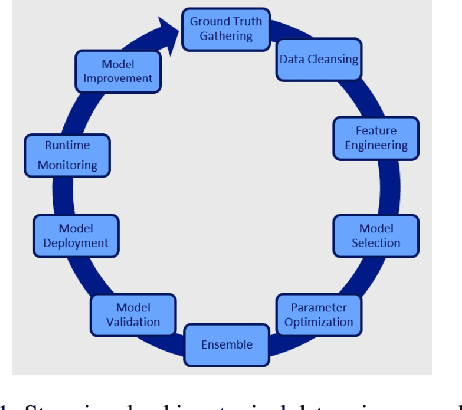
Data science is labor-intensive and human experts are scarce but heavily involved in every aspect of it. This makes data science time consuming and restricted to experts with the resulting quality heavily dependent on their experience and skills. To make data science more accessible and scalable, we need its democratization. Automated Data Science (AutoDS) is aimed towards that goal and is emerging as an important research and business topic. We introduce and define the AutoDS challenge, followed by a proposal of a general AutoDS framework that covers existing approaches but also provides guidance for the development of new methods. We categorize and review the existing literature from multiple aspects of the problem setup and employed techniques. Then we provide several views on how AI could succeed in automating end-to-end AutoDS. We hope this survey can serve as insightful guideline for the AutoDS field and provide inspiration for future research.
Neural Feature Learning From Relational Database
Jun 17, 2018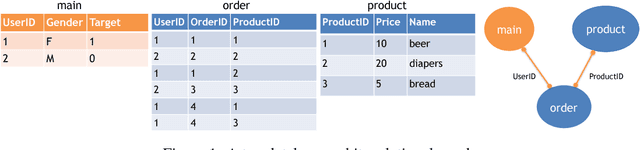

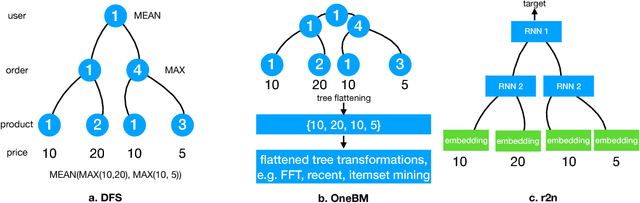

Feature engineering is one of the most important but most tedious tasks in data science. This work studies automation of feature learning from relational database. We first prove theoretically that finding the optimal features from relational data for predictive tasks is NP-hard. We propose an efficient rule-based approach based on heuristics and a deep neural network to automatically learn appropriate features from relational data. We benchmark our approaches in ensembles in past Kaggle competitions. Our new approach wins late medals and beats the state-of-the-art solutions with significant margins. To the best of our knowledge, this is the first time an automated data science system could win medals in Kaggle competitions with complex relational database.