 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Feature Learning From Relational Database
Jun 17, 2018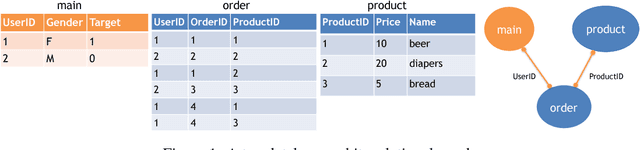

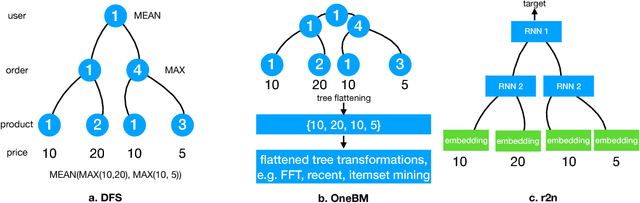

Feature engineering is one of the most important but most tedious tasks in data science. This work studies automation of feature learning from relational database. We first prove theoretically that finding the optimal features from relational data for predictive tasks is NP-hard. We propose an efficient rule-based approach based on heuristics and a deep neural network to automatically learn appropriate features from relational data. We benchmark our approaches in ensembles in past Kaggle competitions. Our new approach wins late medals and beats the state-of-the-art solutions with significant margins. To the best of our knowledge, this is the first time an automated data science system could win medals in Kaggle competitions with complex relational database.
Automated Image Data Preprocessing with Deep Reinforcement Learning
Jun 15, 2018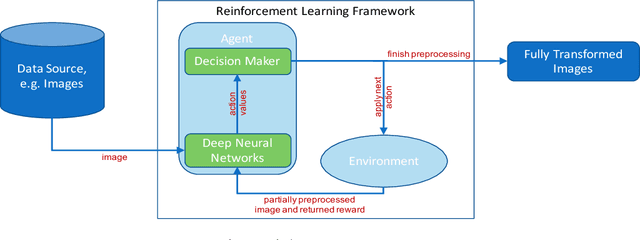
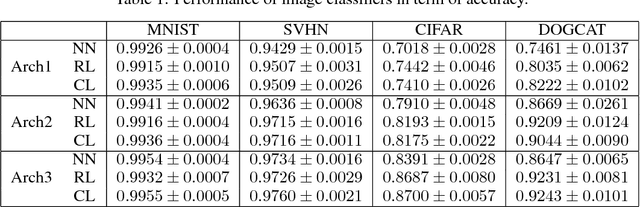
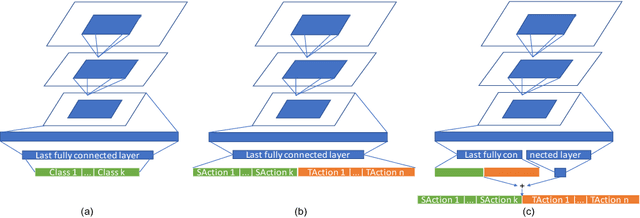
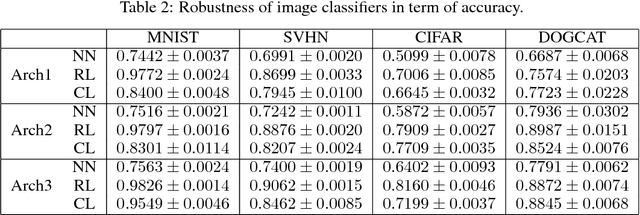
Data preparation, i.e. the process of transforming raw data into a format that can be used for training effective machine learning models, is a tedious and time-consuming task. For image data, preprocessing typically involves a sequence of basic transformations such as cropping, filtering, rotating or flipping images. Currently, data scientists decide manually based on their experience which transformations to apply in which particular order to a given image data set. Besides constituting a bottleneck in real-world data science projects, manual image data preprocessing may yield suboptimal results as data scientists need to rely on intuition or trial-and-error approaches when exploring the space of possible image transformations and thus might not be able to discover the most effective ones. To mitigate the inefficiency and potential ineffectiveness of manual data preprocessing, this paper proposes a deep reinforcement learning framework to automatically discover the optimal data preprocessing steps for training an image classifier. The framework takes as input sets of labeled images and predefined preprocessing transformations. It jointly learns the classifier and the optimal preprocessing transformations for individual images. Experimental results show that the proposed approach not only improves the accuracy of image classifiers, but also makes them substantially more robust to noisy inputs at test time.