 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Assurance of LLM Adversarial Robustness using Ontology-Driven Argumentation
Oct 10, 2024



Despite the impressive adaptability of large language models (LLMs), challenges remain in ensuring their security, transparency, and interpretability. Given their susceptibility to adversarial attacks, LLMs need to be defended with an evolving combination of adversarial training and guardrails. However, managing the implicit and heterogeneous knowledge for continuously assuring robustness is difficult. We introduce a novel approach for assurance of the adversarial robustness of LLMs based on formal argumentation. Using ontologies for formalization, we structure state-of-the-art attacks and defenses, facilitating the creation of a human-readable assurance case, and a machine-readable representation. We demonstrate its application with examples in English language and code translation tasks, and provide implications for theory and practice, by targeting engineers, data scientists, users, and auditors.
Developing Assurance Cases for Adversarial Robustness and Regulatory Compliance in LLMs
Oct 04, 2024


This paper presents an approach to developing assurance cases for adversarial robustness and regulatory compliance in large language models (LLMs). Focusing on both natural and code language tasks, we explore the vulnerabilities these models face, including adversarial attacks based on jailbreaking, heuristics, and randomization. We propose a layered framework incorporating guardrails at various stages of LLM deployment, aimed at mitigating these attacks and ensuring compliance with the EU AI Act. Our approach includes a meta-layer for dynamic risk management and reasoning, crucial for addressing the evolving nature of LLM vulnerabilities. We illustrate our method with two exemplary assurance cases, highlighting how different contexts demand tailored strategies to ensure robust and compliant AI systems.
Towards Assuring EU AI Act Compliance and Adversarial Robustness of LLMs
Oct 04, 2024


Large language models are prone to misuse and vulnerable to security threats, raising significant safety and security concerns. The European Union's Artificial Intelligence Act seeks to enforce AI robustness in certain contexts, but faces implementation challenges due to the lack of standards, complexity of LLMs and emerging security vulnerabilities. Our research introduces a framework using ontologies, assurance cases, and factsheets to support engineers and stakeholders in understanding and documenting AI system compliance and security regarding adversarial robustness. This approach aims to ensure that LLMs adhere to regulatory standards and are equipped to counter potential threats.
Knowledge-Augmented Reasoning for EUAIA Compliance and Adversarial Robustness of LLMs
Oct 04, 2024



The EU AI Act (EUAIA) introduces requirements for AI systems which intersect with the processes required to establish adversarial robustness. However, given the ambiguous language of regulation and the dynamicity of adversarial attacks, developers of systems with highly complex models such as LLMs may find their effort to be duplicated without the assurance of having achieved either compliance or robustness. This paper presents a functional architecture that focuses on bridging the two properties, by introducing components with clear reference to their source. Taking the detection layer recommended by the literature, and the reporting layer required by the law, we aim to support developers and auditors with a reasoning layer based on knowledge augmentation (rules, assurance cases, contextual mappings). Our findings demonstrate a novel direction for ensuring LLMs deployed in the EU are both compliant and adversarially robust, which underpin trustworthiness.
Towards an Accountable and Reproducible Federated Learning: A FactSheets Approach
Feb 25, 2022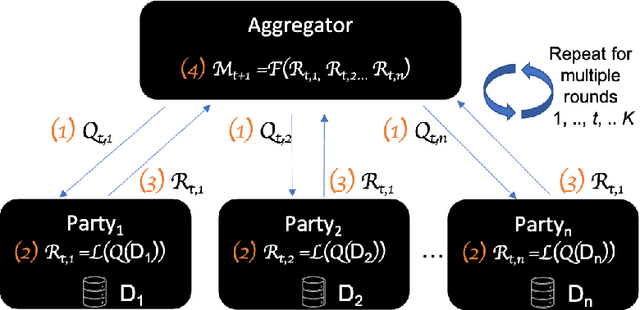
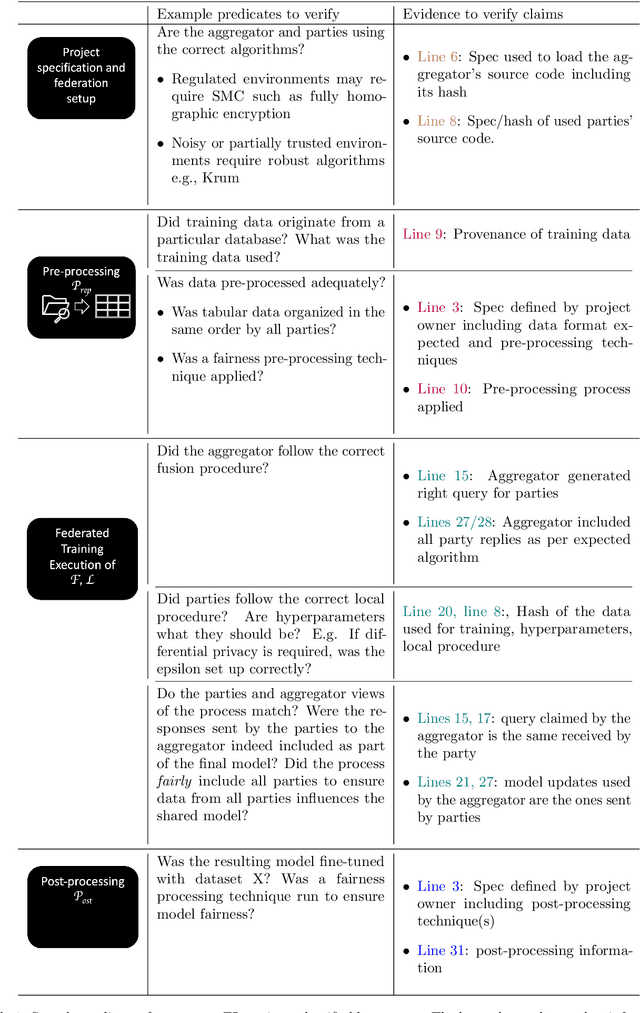
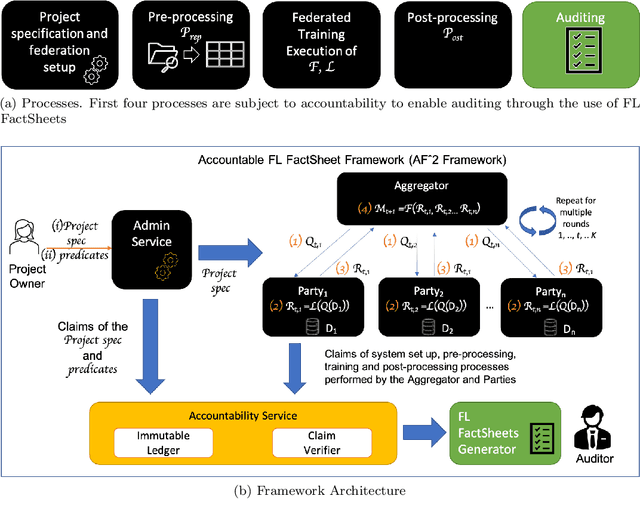
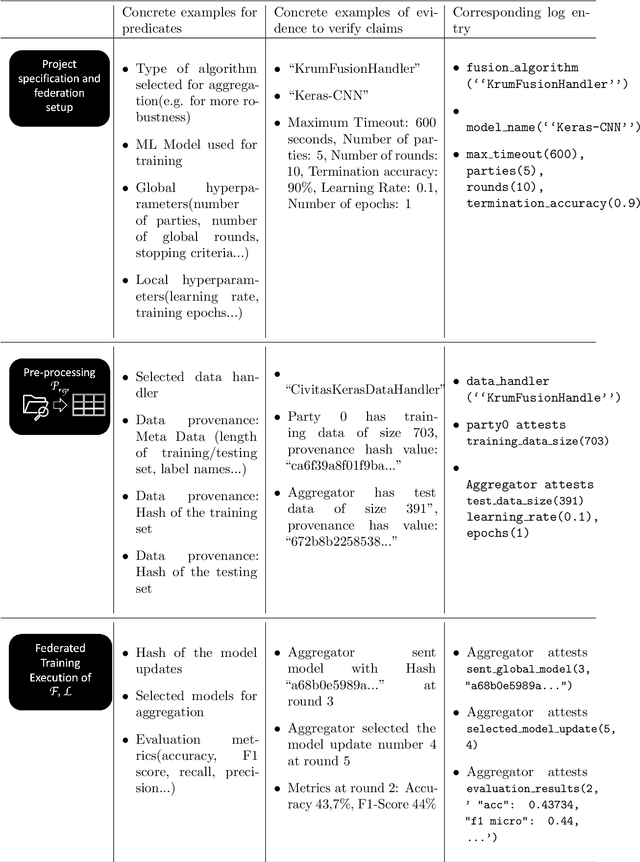
Federated Learning (FL) is a novel paradigm for the shared training of models based on decentralized and private data. With respect to ethical guidelines, FL is promising regarding privacy, but needs to excel vis-\`a-vis transparency and trustworthiness. In particular, FL has to address the accountability of the parties involved and their adherence to rules, law and principles. We introduce AF^2 Framework, where we instrument FL with accountability by fusing verifiable claims with tamper-evident facts, into reproducible arguments. We build on AI FactSheets for instilling transparency and trustworthiness into the AI lifecycle and expand it to incorporate dynamic and nested facts, as well as complex model compositions in FL. Based on our approach, an auditor can validate, reproduce and certify a FL process. This can be directly applied in practice to address the challenges of AI engineering and ethics.