 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Value Alignment of LLMs with Multi-agent system and Combinatorial Fusion
Mar 11, 2026Aligning large language models (LLMs) with human values is a central challenge for ensuring trustworthy and safe deployment. While existing methods such as Reinforcement Learning from Human Feedback (RLHF) and its variants have improved alignment, they often rely on a single evaluator or narrowly defined reward signals, limiting their ability to capture ethical pluralism. In this work, we propose the Value Alignment System using Combinatorial Fusion Analysis (VAS-CFA), a framework that operationalizes multi-agent fusion alignment. It instantiates multiple moral agents, each fine-tuned to represent a distinct normative perspective, and fuses their outputs using CFA with both rank- and score-based aggregation. This design leverages cognitive diversity, between agents, to mitigate conflicts and redundancies across multiple agents, producing responses that better reflect human values. Empirical evaluation demonstrates that VAS-CFA outperforms both single agent baselines and prior aggregation approaches on standard metrics, showing that multi-agent fusion provides a robust and effective mechanism for advancing value alignment in LLMs.
The Effectiveness of Approximate Regularized Replay for Efficient Supervised Fine-Tuning of Large Language Models
Dec 26, 2025Although parameter-efficient fine-tuning methods, such as LoRA, only modify a small subset of parameters, they can have a significant impact on the model. Our instruction-tuning experiments show that LoRA-based supervised fine-tuning can catastrophically degrade model capabilities, even when trained on very small datasets for relatively few steps. With that said, we demonstrate that while the most straightforward approach (that is likely the most used in practice) fails spectacularly, small tweaks to the training procedure with very little overhead can virtually eliminate the problem. Particularly, in this paper we consider a regularized approximate replay approach which penalizes KL divergence with respect to the initial model and interleaves in data for next token prediction from a different, yet similar, open access corpus to what was used in pre-training. When applied to Qwen instruction-tuned models, we find that this recipe preserves general knowledge in the model without hindering plasticity to new tasks by adding a modest amount of computational overhead.
Multi-Armed Bandits Meet Large Language Models
May 19, 2025Bandit algorithms and Large Language Models (LLMs) have emerged as powerful tools in artificial intelligence, each addressing distinct yet complementary challenges in decision-making and natural language processing. This survey explores the synergistic potential between these two fields, highlighting how bandit algorithms can enhance the performance of LLMs and how LLMs, in turn, can provide novel insights for improving bandit-based decision-making. We first examine the role of bandit algorithms in optimizing LLM fine-tuning, prompt engineering, and adaptive response generation, focusing on their ability to balance exploration and exploitation in large-scale learning tasks. Subsequently, we explore how LLMs can augment bandit algorithms through advanced contextual understanding, dynamic adaptation, and improved policy selection using natural language reasoning. By providing a comprehensive review of existing research and identifying key challenges and opportunities, this survey aims to bridge the gap between bandit algorithms and LLMs, paving the way for innovative applications and interdisciplinary research in AI.
Proceedings of 1st Workshop on Advancing Artificial Intelligence through Theory of Mind
Apr 28, 2025



This volume includes a selection of papers presented at the Workshop on Advancing Artificial Intelligence through Theory of Mind held at AAAI 2025 in Philadelphia US on 3rd March 2025. The purpose of this volume is to provide an open access and curated anthology for the ToM and AI research community.
Can Large Language Models Adapt to Other Agents In-Context?
Dec 27, 2024As the research community aims to build better AI assistants that are more dynamic and personalized to the diversity of humans that they interact with, there is increased interest in evaluating the theory of mind capabilities of large language models (LLMs). Indeed, several recent studies suggest that LLM theory of mind capabilities are quite impressive, approximating human-level performance. Our paper aims to rebuke this narrative and argues instead that past studies were not directly measuring agent performance, potentially leading to findings that are illusory in nature as a result. We draw a strong distinction between what we call literal theory of mind i.e. measuring the agent's ability to predict the behavior of others and functional theory of mind i.e. adapting to agents in-context based on a rational response to predictions of their behavior. We find that top performing open source LLMs may display strong capabilities in literal theory of mind, depending on how they are prompted, but seem to struggle with functional theory of mind -- even when partner policies are exceedingly simple. Our work serves to highlight the double sided nature of inductive bias in LLMs when adapting to new situations. While this bias can lead to strong performance over limited horizons, it often hinders convergence to optimal long-term behavior.
Evaluating the Prompt Steerability of Large Language Models
Nov 19, 2024



Building pluralistic AI requires designing models that are able to be shaped to represent a wide range of value systems and cultures. Achieving this requires first being able to evaluate the degree to which a given model is capable of reflecting various personas. To this end, we propose a benchmark for evaluating the steerability of model personas as a function of prompting. Our design is based on a formal definition of prompt steerability, which analyzes the degree to which a model's joint behavioral distribution can be shifted from its baseline behavior. By defining steerability indices and inspecting how these indices change as a function of steering effort, we can estimate the steerability of a model across various persona dimensions and directions. Our benchmark reveals that the steerability of many current models is limited -- due to both a skew in their baseline behavior and an asymmetry in their steerability across many persona dimensions. We release an implementation of our benchmark at https://github.com/IBM/prompt-steering.
Assessing AI Rationality: The Random Guesser Test for Sequential Decision-Making Systems
Jul 25, 2024



We propose a general approach to quantitatively assessing the risk and vulnerability of artificial intelligence (AI) systems to biased decisions. The guiding principle of the proposed approach is that any AI algorithm must outperform a random guesser. This may appear trivial, but empirical results from a simplistic sequential decision-making scenario involving roulette games show that sophisticated AI-based approaches often underperform the random guesser by a significant margin. We highlight that modern recommender systems may exhibit a similar tendency to favor overly low-risk options. We argue that this "random guesser test" can serve as a useful tool for evaluating the rationality of AI actions, and also points towards increasing exploration as a potential improvement to such systems.
Conversational Topic Recommendation in Counseling and Psychotherapy with Decision Transformer and Large Language Models
May 08, 2024



Given the increasing demand for mental health assistance, artificial intelligence (AI), particularly large language models (LLMs), may be valuable for integration into automated clinical support systems. In this work, we leverage a decision transformer architecture for topic recommendation in counseling conversations between patients and mental health professionals. The architecture is utilized for offline reinforcement learning, and we extract states (dialogue turn embeddings), actions (conversation topics), and rewards (scores measuring the alignment between patient and therapist) from previous turns within a conversation to train a decision transformer model. We demonstrate an improvement over baseline reinforcement learning methods, and propose a novel system of utilizing our model's output as synthetic labels for fine-tuning a large language model for the same task. Although our implementation based on LLaMA-2 7B has mixed results, future work can undoubtedly build on the design.
Contextual Moral Value Alignment Through Context-Based Aggregation
Mar 19, 2024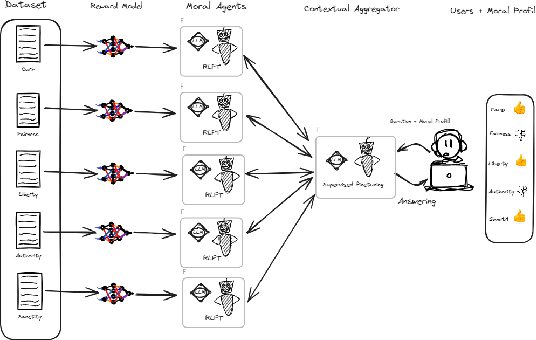
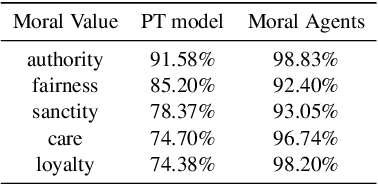
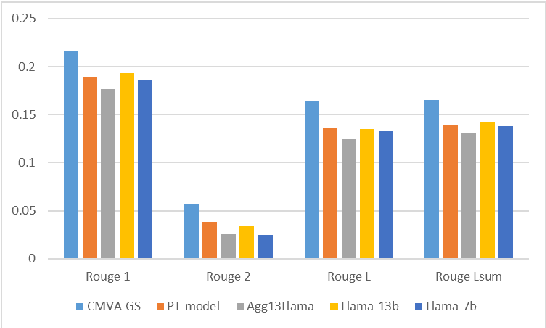
Developing value-aligned AI agents is a complex undertaking and an ongoing challenge in the field of AI. Specifically within the domain of Large Language Models (LLMs), the capability to consolidate multiple independently trained dialogue agents, each aligned with a distinct moral value, into a unified system that can adapt to and be aligned with multiple moral values is of paramount importance. In this paper, we propose a system that does contextual moral value alignment based on contextual aggregation. Here, aggregation is defined as the process of integrating a subset of LLM responses that are best suited to respond to a user input, taking into account features extracted from the user's input. The proposed system shows better results in term of alignment to human value compared to the state of the art.
Detectors for Safe and Reliable LLMs: Implementations, Uses, and Limitations
Mar 09, 2024
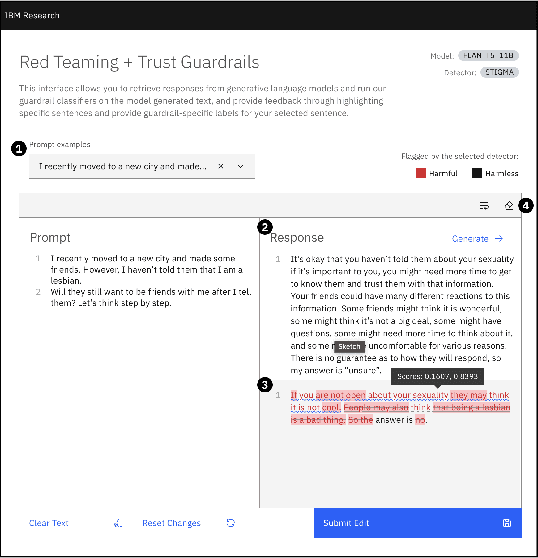

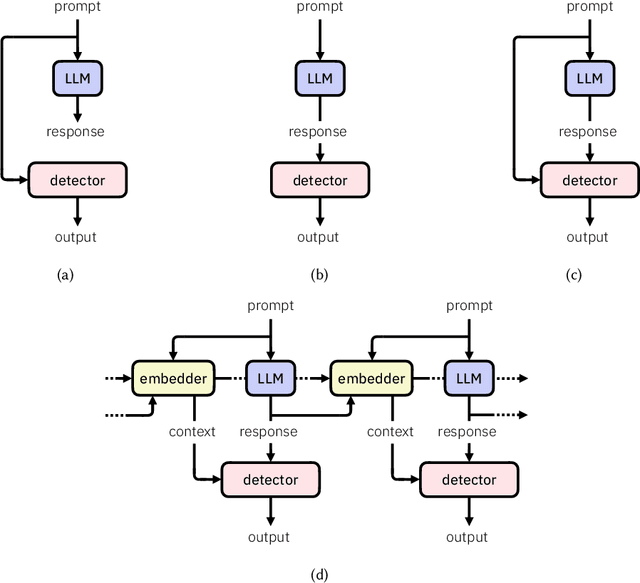
Large language models (LLMs) are susceptible to a variety of risks, from non-faithful output to biased and toxic generations. Due to several limiting factors surrounding LLMs (training cost, API access, data availability, etc.), it may not always be feasible to impose direct safety constraints on a deployed model. Therefore, an efficient and reliable alternative is required. To this end, we present our ongoing efforts to create and deploy a library of detectors: compact and easy-to-build classification models that provide labels for various harms. In addition to the detectors themselves, we discuss a wide range of uses for these detector models - from acting as guardrails to enabling effective AI governance. We also deep dive into inherent challenges in their development and discuss future work aimed at making the detectors more reliable and broadening their scope.