 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Armed Bandits Meet Large Language Models
May 19, 2025Bandit algorithms and Large Language Models (LLMs) have emerged as powerful tools in artificial intelligence, each addressing distinct yet complementary challenges in decision-making and natural language processing. This survey explores the synergistic potential between these two fields, highlighting how bandit algorithms can enhance the performance of LLMs and how LLMs, in turn, can provide novel insights for improving bandit-based decision-making. We first examine the role of bandit algorithms in optimizing LLM fine-tuning, prompt engineering, and adaptive response generation, focusing on their ability to balance exploration and exploitation in large-scale learning tasks. Subsequently, we explore how LLMs can augment bandit algorithms through advanced contextual understanding, dynamic adaptation, and improved policy selection using natural language reasoning. By providing a comprehensive review of existing research and identifying key challenges and opportunities, this survey aims to bridge the gap between bandit algorithms and LLMs, paving the way for innovative applications and interdisciplinary research in AI.
Batched Bandits with Crowd Externalities
Sep 29, 2021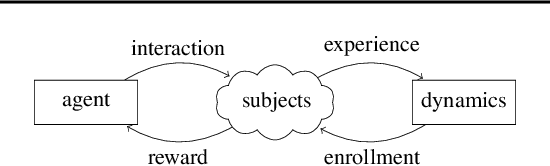
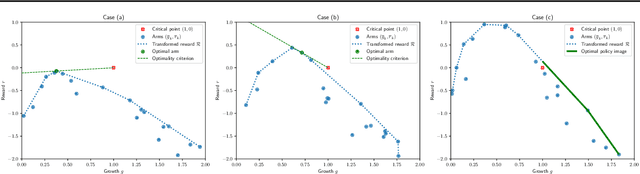
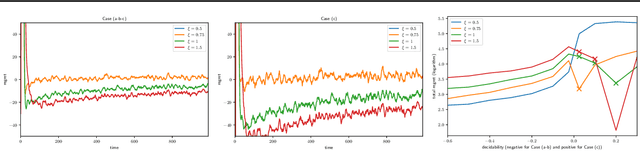
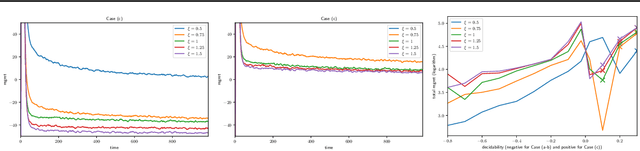
In Batched Multi-Armed Bandits (BMAB), the policy is not allowed to be updated at each time step. Usually, the setting asserts a maximum number of allowed policy updates and the algorithm schedules them so that to minimize the expected regret. In this paper, we describe a novel setting for BMAB, with the following twist: the timing of the policy update is not controlled by the BMAB algorithm, but instead the amount of data received during each batch, called \textit{crowd}, is influenced by the past selection of arms. We first design a near-optimal policy with approximate knowledge of the parameters that we prove to have a regret in $\mathcal{O}(\sqrt{\frac{\ln x}{x}}+\epsilon)$ where $x$ is the size of the crowd and $\epsilon$ is the parameter error. Next, we implement a UCB-inspired algorithm that guarantees an additional regret in $\mathcal{O}\left(\max(K\ln T,\sqrt{T\ln T})\right)$, where $K$ is the number of arms and $T$ is the horizon.
Reinforcement Learning Algorithm Selection
Nov 14, 2017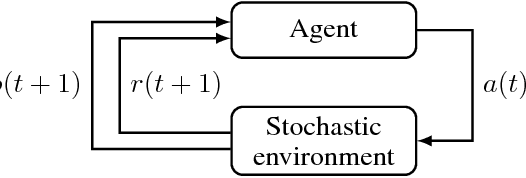

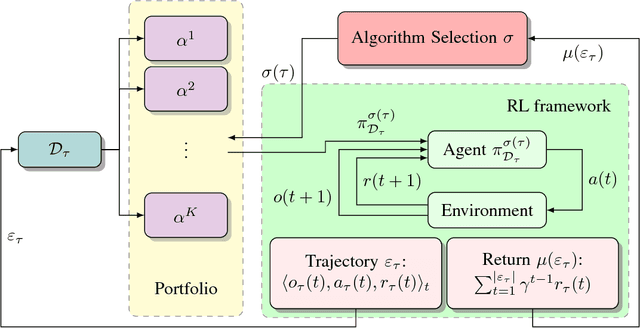
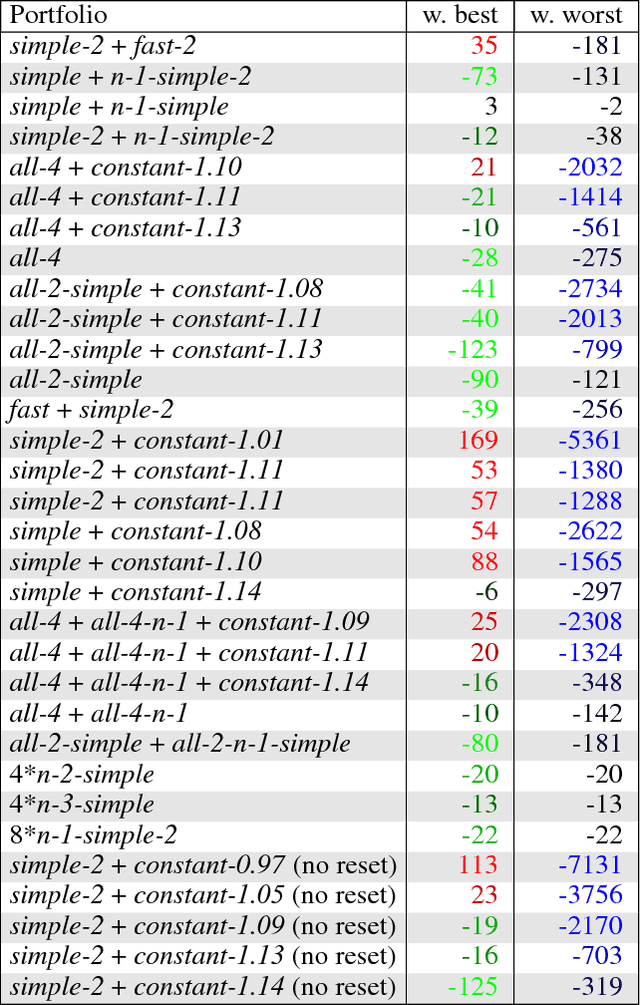
This paper formalises the problem of online algorithm selection in the context of Reinforcement Learning. The setup is as follows: given an episodic task and a finite number of off-policy RL algorithms, a meta-algorithm has to decide which RL algorithm is in control during the next episode so as to maximize the expected return. The article presents a novel meta-algorithm, called Epochal Stochastic Bandit Algorithm Selection (ESBAS). Its principle is to freeze the policy updates at each epoch, and to leave a rebooted stochastic bandit in charge of the algorithm selection. Under some assumptions, a thorough theoretical analysis demonstrates its near-optimality considering the structural sampling budget limitations. ESBAS is first empirically evaluated on a dialogue task where it is shown to outperform each individual algorithm in most configurations. ESBAS is then adapted to a true online setting where algorithms update their policies after each transition, which we call SSBAS. SSBAS is evaluated on a fruit collection task where it is shown to adapt the stepsize parameter more efficiently than the classical hyperbolic decay, and on an Atari game, where it improves the performance by a wide margin.
Context Attentive Bandits: Contextual Bandit with Restricted Context
Jun 07, 2017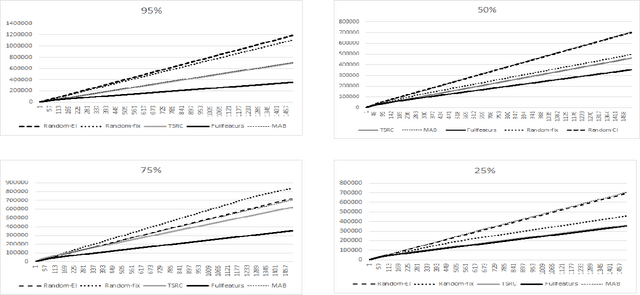
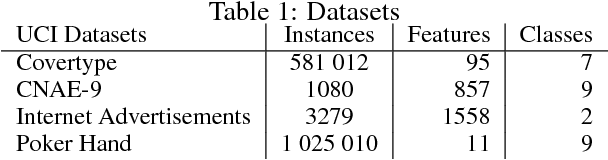

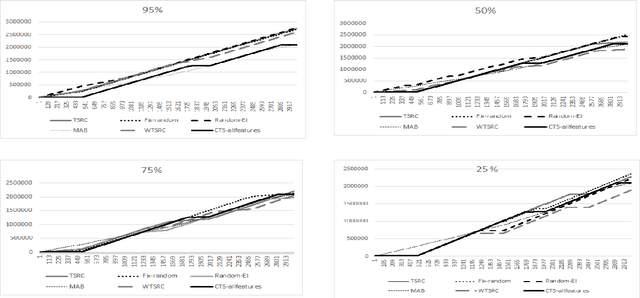
We consider a novel formulation of the multi-armed bandit model, which we call the contextual bandit with restricted context, where only a limited number of features can be accessed by the learner at every iteration. This novel formulation is motivated by different online problems arising in clinical trials, recommender systems and attention modeling. Herein, we adapt the standard multi-armed bandit algorithm known as Thompson Sampling to take advantage of our restricted context setting, and propose two novel algorithms, called the Thompson Sampling with Restricted Context(TSRC) and the Windows Thompson Sampling with Restricted Context(WTSRC), for handling stationary and nonstationary environments, respectively. Our empirical results demonstrate advantages of the proposed approaches on several real-life datasets
A Neural Networks Committee for the Contextual Bandit Problem
Sep 29, 2014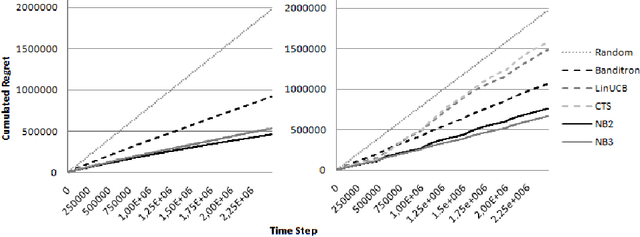
This paper presents a new contextual bandit algorithm, NeuralBandit, which does not need hypothesis on stationarity of contexts and rewards. Several neural networks are trained to modelize the value of rewards knowing the context. Two variants, based on multi-experts approach, are proposed to choose online the parameters of multi-layer perceptrons. The proposed algorithms are successfully tested on a large dataset with and without stationarity of rewards.