 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Attentive Bandits: Contextual Bandit with Restricted Context
Jun 07, 2017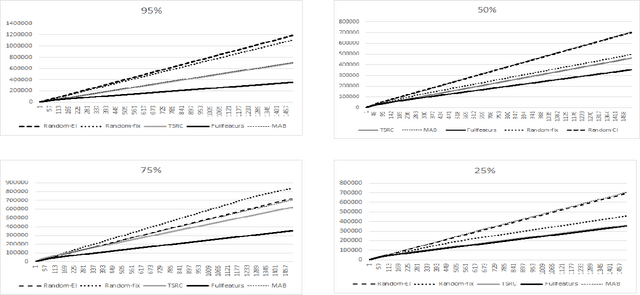

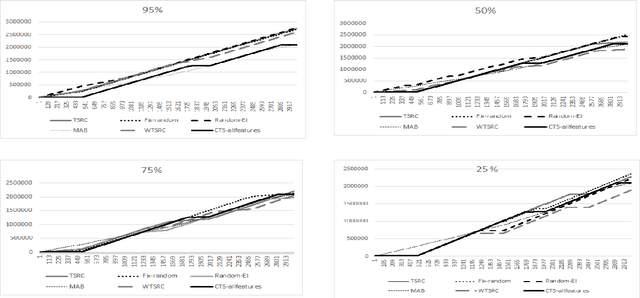
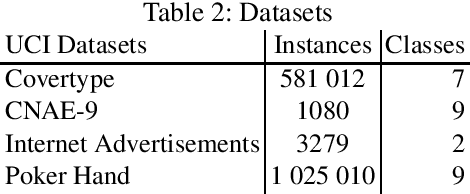
We consider a novel formulation of the multi-armed bandit model, which we call the contextual bandit with restricted context, where only a limited number of features can be accessed by the learner at every iteration. This novel formulation is motivated by different online problems arising in clinical trials, recommender systems and attention modeling. Herein, we adapt the standard multi-armed bandit algorithm known as Thompson Sampling to take advantage of our restricted context setting, and propose two novel algorithms, called the Thompson Sampling with Restricted Context(TSRC) and the Windows Thompson Sampling with Restricted Context(WTSRC), for handling stationary and nonstationary environments, respectively. Our empirical results demonstrate advantages of the proposed approaches on several real-life datasets
Bandit Models of Human Behavior: Reward Processing in Mental Disorders
Jun 07, 2017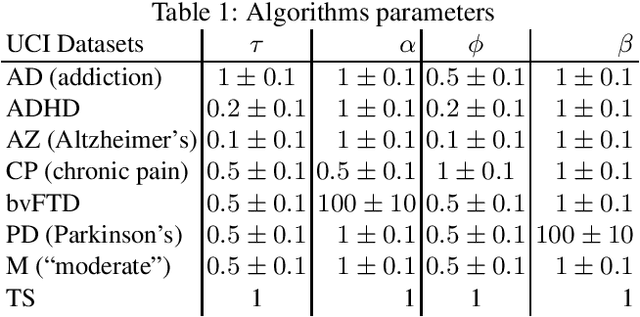
Drawing an inspiration from behavioral studies of human decision making, we propose here a general parametric framework for multi-armed bandit problem, which extends the standard Thompson Sampling approach to incorporate reward processing biases associated with several neurological and psychiatric conditions, including Parkinson's and Alzheimer's diseases, attention-deficit/hyperactivity disorder (ADHD), addiction, and chronic pain. We demonstrate empirically that the proposed parametric approach can often outperform the baseline Thompson Sampling on a variety of datasets. Moreover, from the behavioral modeling perspective, our parametric framework can be viewed as a first step towards a unifying computational model capturing reward processing abnormalities across multiple mental conditions.