 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetectors for Safe and Reliable LLMs: Implementations, Uses, and Limitations
Mar 09, 2024
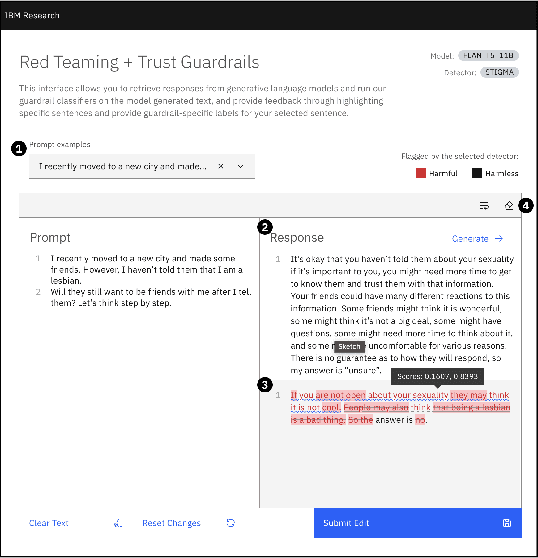

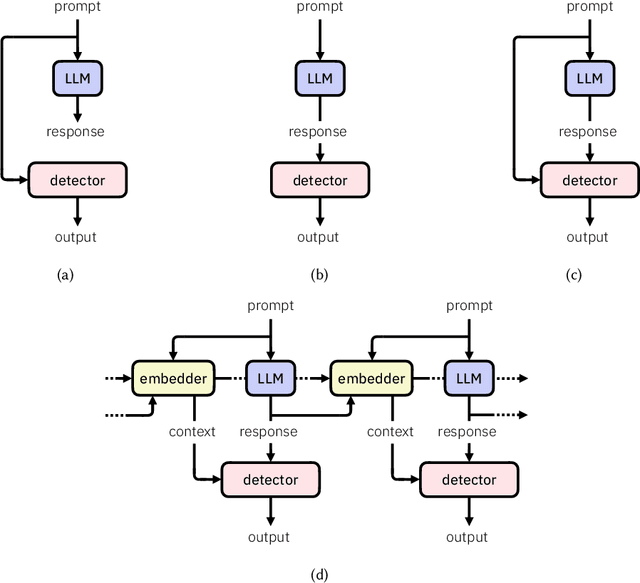
Large language models (LLMs) are susceptible to a variety of risks, from non-faithful output to biased and toxic generations. Due to several limiting factors surrounding LLMs (training cost, API access, data availability, etc.), it may not always be feasible to impose direct safety constraints on a deployed model. Therefore, an efficient and reliable alternative is required. To this end, we present our ongoing efforts to create and deploy a library of detectors: compact and easy-to-build classification models that provide labels for various harms. In addition to the detectors themselves, we discuss a wide range of uses for these detector models - from acting as guardrails to enabling effective AI governance. We also deep dive into inherent challenges in their development and discuss future work aimed at making the detectors more reliable and broadening their scope.
Interpretable Subgroup Discovery in Treatment Effect Estimation with Application to Opioid Prescribing Guidelines
May 08, 2019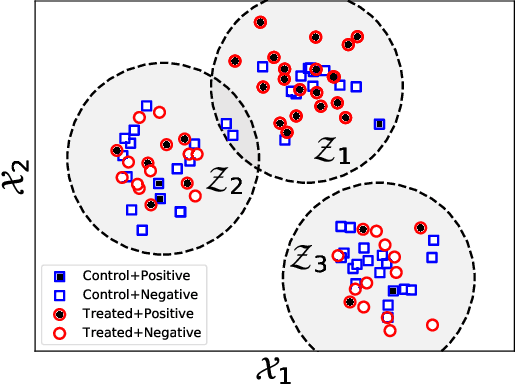
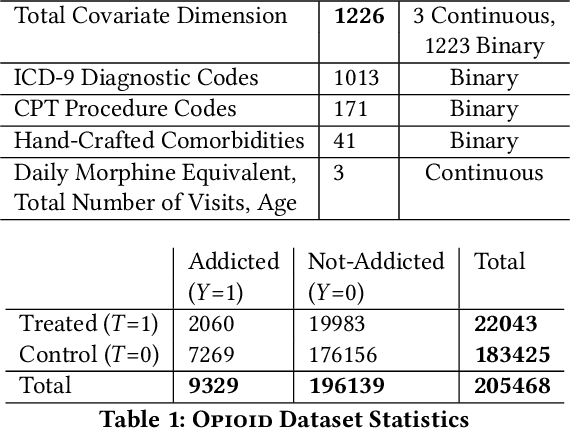
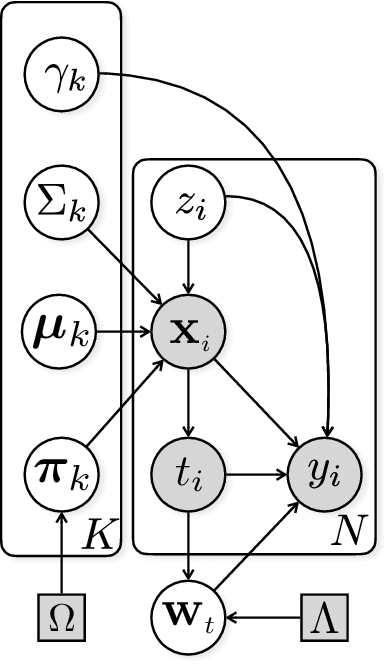
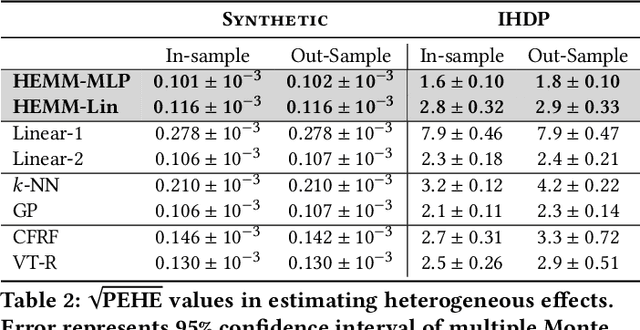
The dearth of prescribing guidelines for physicians is one key driver of the current opioid epidemic in the United States. In this work, we analyze medical and pharmaceutical claims data to draw insights on characteristics of patients who are more prone to adverse outcomes after an initial synthetic opioid prescription. Toward this end, we propose a generative model that allows discovery from observational data of subgroups that demonstrate an enhanced or diminished causal effect due to treatment. Our approach models these sub-populations as a mixture distribution, using sparsity to enhance interpretability, while jointly learning nonlinear predictors of the potential outcomes to better adjust for confounding. The approach leads to human-interpretable insights on discovered subgroups, improving the practical utility for decision support