 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment Studio: Aligning Large Language Models to Particular Contextual Regulations
Mar 08, 2024The alignment of large language models is usually done by model providers to add or control behaviors that are common or universally understood across use cases and contexts. In contrast, in this article, we present an approach and architecture that empowers application developers to tune a model to their particular values, social norms, laws and other regulations, and orchestrate between potentially conflicting requirements in context. We lay out three main components of such an Alignment Studio architecture: Framers, Instructors, and Auditors that work in concert to control the behavior of a language model. We illustrate this approach with a running example of aligning a company's internal-facing enterprise chatbot to its business conduct guidelines.
Auditing and Generating Synthetic Data with Controllable Trust Trade-offs
May 02, 2023



Data collected from the real world tends to be biased, unbalanced, and at risk of exposing sensitive and private information. This reality has given rise to the idea of creating synthetic datasets to alleviate risk, bias, harm, and privacy concerns inherent in the real data. This concept relies on Generative AI models to produce unbiased, privacy-preserving synthetic data while being true to the real data. In this new paradigm, how can we tell if this approach delivers on its promises? We present an auditing framework that offers a holistic assessment of synthetic datasets and AI models trained on them, centered around bias and discrimination prevention, fidelity to the real data, utility, robustness, and privacy preservation. We showcase our framework by auditing multiple generative models on diverse use cases, including education, healthcare, banking, human resources, and across different modalities, from tabular, to time-series, to natural language. Our use cases demonstrate the importance of a holistic assessment in order to ensure compliance with socio-technical safeguards that regulators and policymakers are increasingly enforcing. For this purpose, we introduce the trust index that ranks multiple synthetic datasets based on their prescribed safeguards and their desired trade-offs. Moreover, we devise a trust-index-driven model selection and cross-validation procedure via auditing in the training loop that we showcase on a class of transformer models that we dub TrustFormers, across different modalities. This trust-driven model selection allows for controllable trust trade-offs in the resulting synthetic data. We instrument our auditing framework with workflows that connect different stakeholders from model development to audit and certification via a synthetic data auditing report.
Accelerating Inhibitor Discovery for Multiple SARS-CoV-2 Targets with a Single, Sequence-Guided Deep Generative Framework
Apr 19, 2022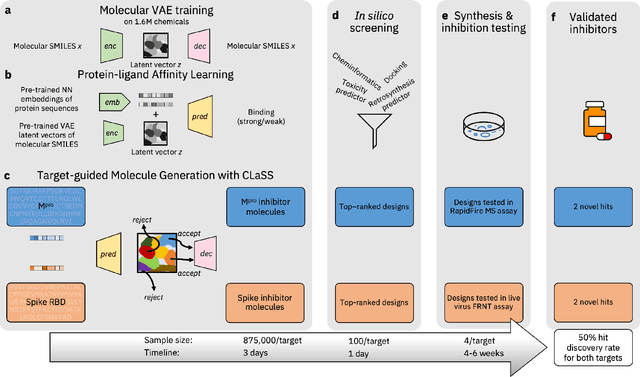
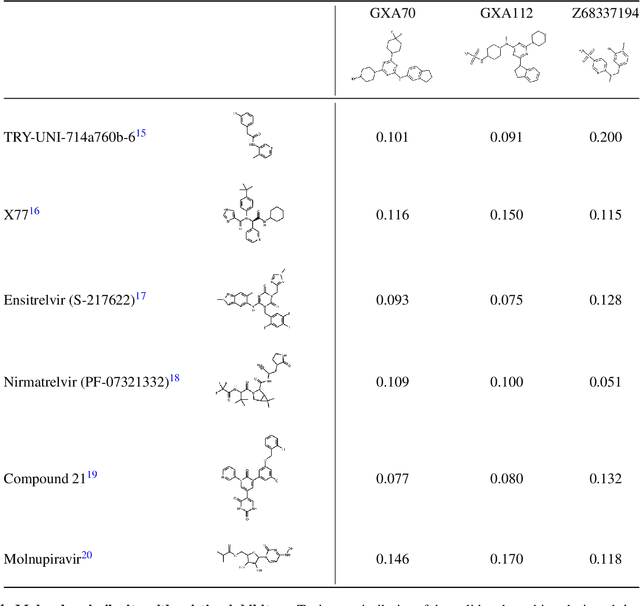
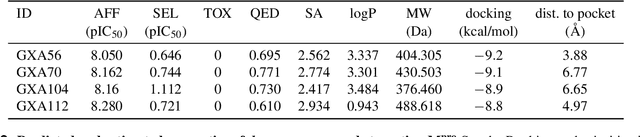
The COVID-19 pandemic has highlighted the urgency for developing more efficient molecular discovery pathways. As exhaustive exploration of the vast chemical space is infeasible, discovering novel inhibitor molecules for emerging drug-target proteins is challenging, particularly for targets with unknown structure or ligands. We demonstrate the broad utility of a single deep generative framework toward discovering novel drug-like inhibitor molecules against two distinct SARS-CoV-2 targets -- the main protease (Mpro) and the receptor binding domain (RBD) of the spike protein. To perform target-aware design, the framework employs a target sequence-conditioned sampling of novel molecules from a generative model. Micromolar-level in vitro inhibition was observed for two candidates (out of four synthesized) for each target. The most potent spike RBD inhibitor also emerged as a rare non-covalent antiviral with broad-spectrum activity against several SARS-CoV-2 variants in live virus neutralization assays. These results show a broadly deployable machine intelligence framework can accelerate hit discovery across different emerging drug-targets.
AI Explainability 360: Impact and Design
Sep 24, 2021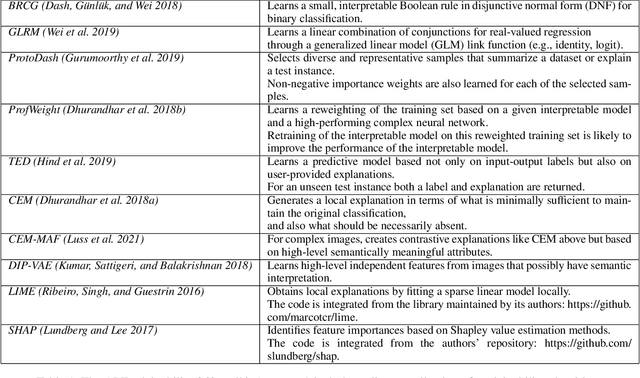
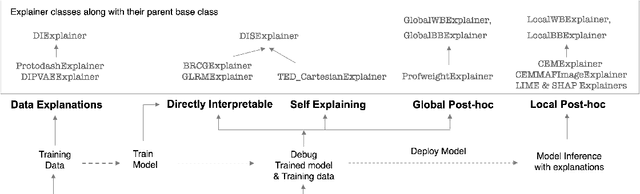

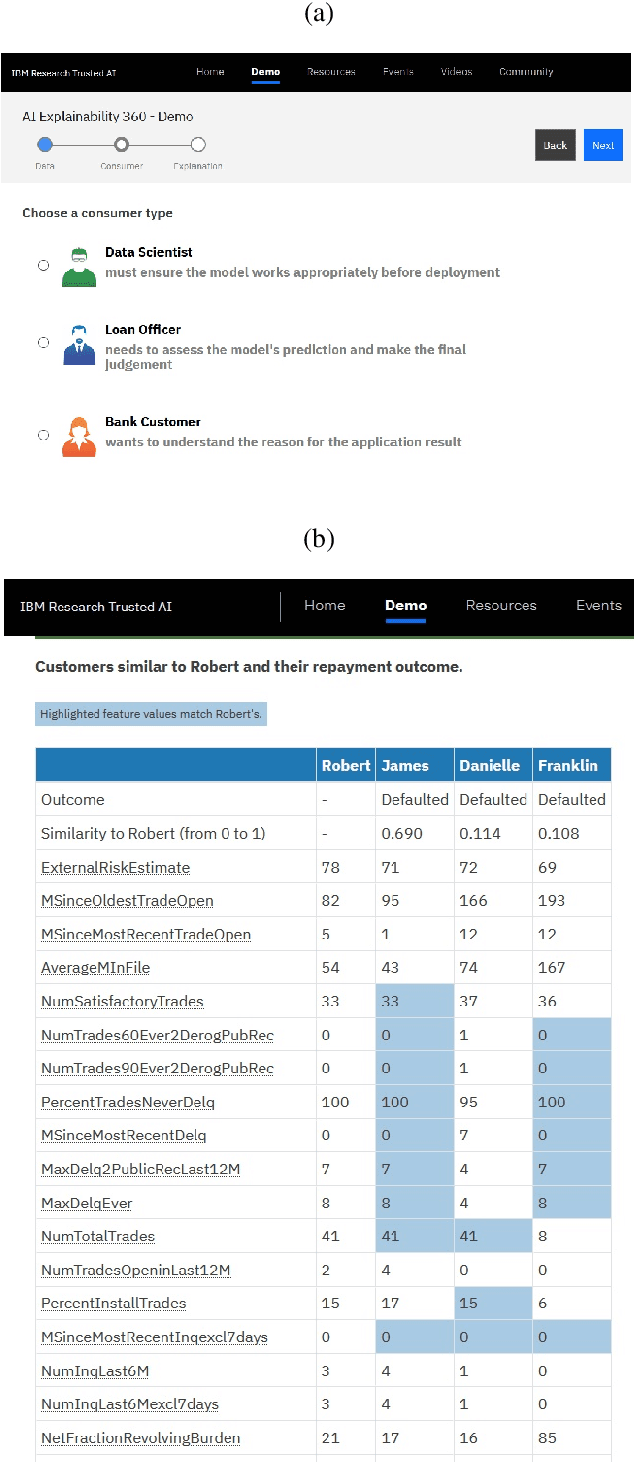
As artificial intelligence and machine learning algorithms become increasingly prevalent in society, multiple stakeholders are calling for these algorithms to provide explanations. At the same time, these stakeholders, whether they be affected citizens, government regulators, domain experts, or system developers, have different explanation needs. To address these needs, in 2019, we created AI Explainability 360 (Arya et al. 2020), an open source software toolkit featuring ten diverse and state-of-the-art explainability methods and two evaluation metrics. This paper examines the impact of the toolkit with several case studies, statistics, and community feedback. The different ways in which users have experienced AI Explainability 360 have resulted in multiple types of impact and improvements in multiple metrics, highlighted by the adoption of the toolkit by the independent LF AI & Data Foundation. The paper also describes the flexible design of the toolkit, examples of its use, and the significant educational material and documentation available to its users.
Accelerating Antimicrobial Discovery with Controllable Deep Generative Models and Molecular Dynamics
May 22, 2020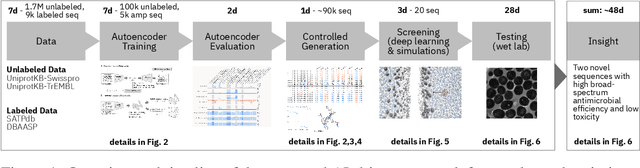
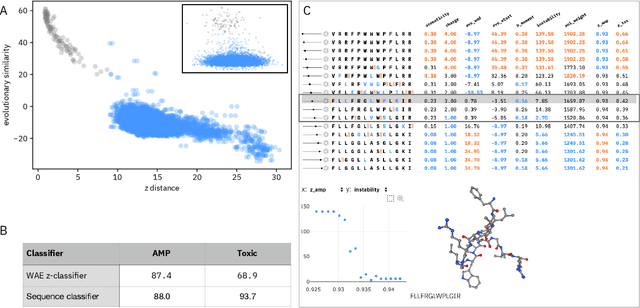
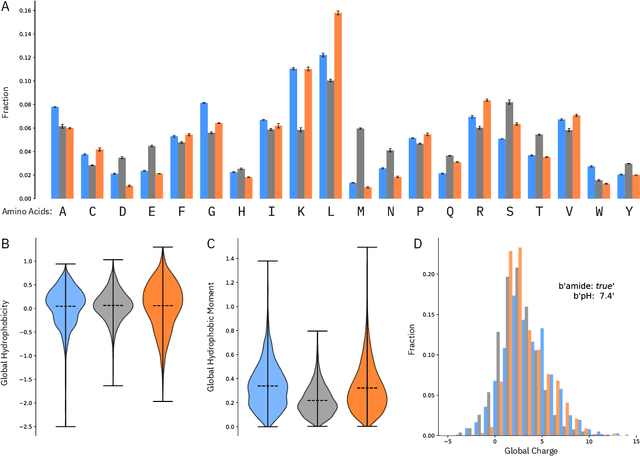
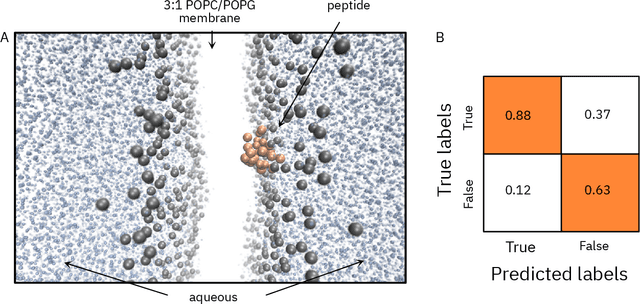
De novo therapeutic design is challenged by a vast chemical repertoire and multiple constraints such as high broad-spectrum potency and low toxicity. We propose CLaSS (Controlled Latent attribute Space Sampling) - a novel and efficient computational method for attribute-controlled generation of molecules, which leverages guidance from classifiers trained on an informative latent space of molecules modeled using a deep generative autoencoder. We further screen the generated molecules by using a set of deep learning classifiers in conjunction with novel physicochemical features derived from high-throughput molecular simulations. The proposed approach is employed for designing non-toxic antimicrobial peptides (AMPs) with strong broad-spectrum potency, which are emerging drug candidates for tackling antibiotic resistance. Synthesis and wet lab testing of only twenty designed sequences identified two novel and minimalist AMPs with high potency against diverse Gram-positive and Gram-negative pathogens, including the hard-to-treat multidrug-resistant K. pneumoniae, as well as low in vitro and in vivo toxicity. The proposed approach thus presents a viable path for faster discovery of potent and selective broad-spectrum antimicrobials with a higher success rate than state-of-the-art methods.
Target-Specific and Selective Drug Design for COVID-19 Using Deep Generative Models
Apr 02, 2020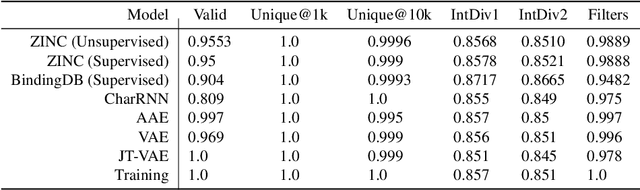

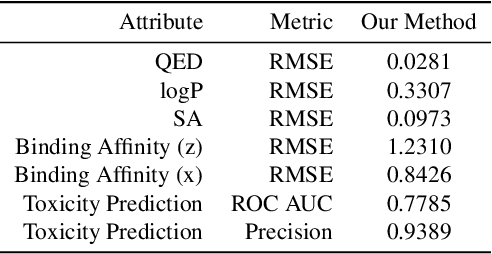
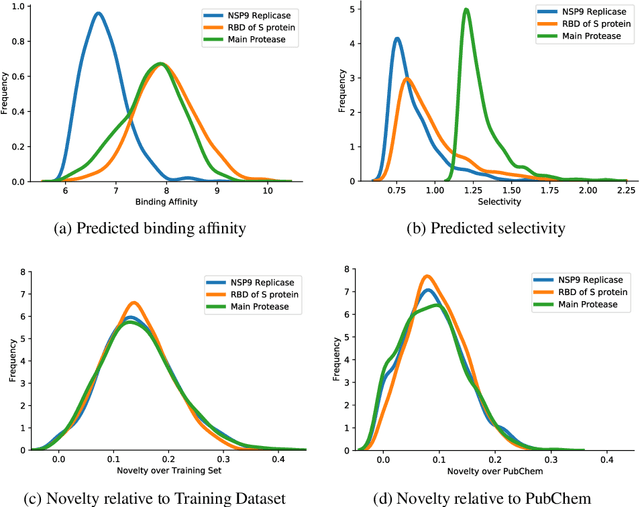
The recent COVID-19 pandemic has highlighted the need for rapid therapeutic development for infectious diseases. To accelerate this process, we present a deep learning based generative modeling framework, CogMol, to design drug candidates specific to a given target protein sequence with high off-target selectivity. We augment this generative framework with an in silico screening process that accounts for toxicity, to lower the failure rate of the generated drug candidates in later stages of the drug development pipeline. We apply this framework to three relevant proteins of the SARS-CoV-2, the virus responsible for COVID-19, namely non-structural protein 9 (NSP9) replicase, main protease, and the receptor-binding domain (RBD) of the S protein. Docking to the target proteins demonstrate the potential of these generated molecules as ligands. Structural similarity analyses further imply novelty of the generated molecules with respect to the training dataset as well as possible biological association of a number of generated molecules that might be of relevance to COVID-19 therapeutic design. While the validation of these molecules is underway, we release ~ 3000 novel COVID-19 drug candidates generated using our framework. URL : http://ibm.biz/covid19-mol
Understanding Unequal Gender Classification Accuracy from Face Images
Nov 30, 2018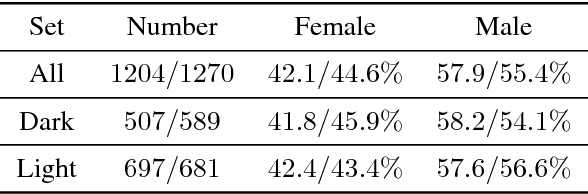
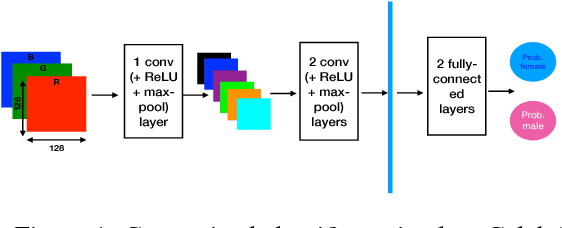
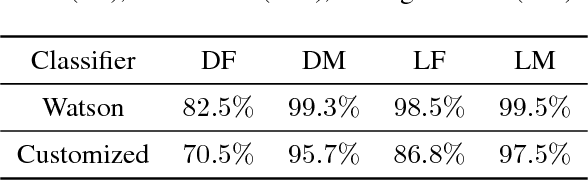
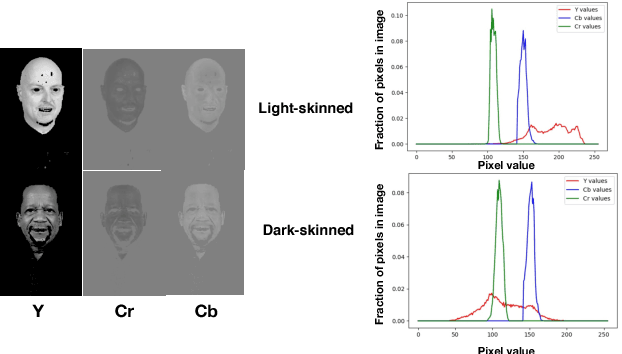
Recent work shows unequal performance of commercial face classification services in the gender classification task across intersectional groups defined by skin type and gender. Accuracy on dark-skinned females is significantly worse than on any other group. In this paper, we conduct several analyses to try to uncover the reason for this gap. The main finding, perhaps surprisingly, is that skin type is not the driver. This conclusion is reached via stability experiments that vary an image's skin type via color-theoretic methods, namely luminance mode-shift and optimal transport. A second suspect, hair length, is also shown not to be the driver via experiments on face images cropped to exclude the hair. Finally, using contrastive post-hoc explanation techniques for neural networks, we bring forth evidence suggesting that differences in lip, eye and cheek structure across ethnicity lead to the differences. Further, lip and eye makeup are seen as strong predictors for a female face, which is a troubling propagation of a gender stereotype.
TED: Teaching AI to Explain its Decisions
Nov 12, 2018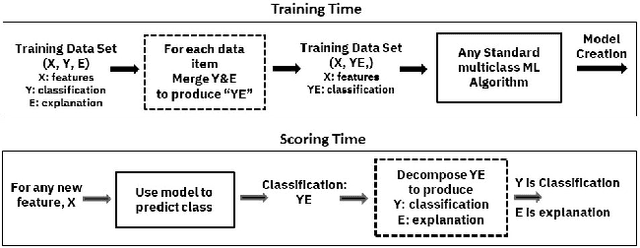
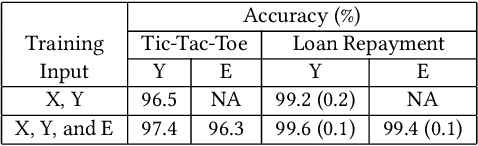

Artificial intelligence systems are being increasingly deployed due to their potential to increase the efficiency, scale, consistency, fairness, and accuracy of decisions. However, as many of these systems are opaque in their operation, there is a growing demand for such systems to provide explanations for their decisions. Conventional approaches to this problem attempt to expose or discover the inner workings of a machine learning model with the hope that the resulting explanations will be meaningful to the consumer. In contrast, this paper suggests a new approach to this problem. It introduces a simple, practical framework, called Teaching Explanations for Decisions (TED), that provides meaningful explanations that match the mental model of the consumer. We illustrate the generality and effectiveness of this approach with two different examples, resulting in highly accurate explanations with no loss of prediction accuracy for these two examples.
PepCVAE: Semi-Supervised Targeted Design of Antimicrobial Peptide Sequences
Oct 22, 2018

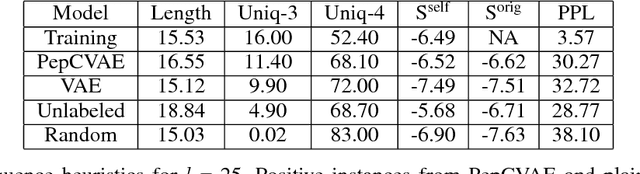
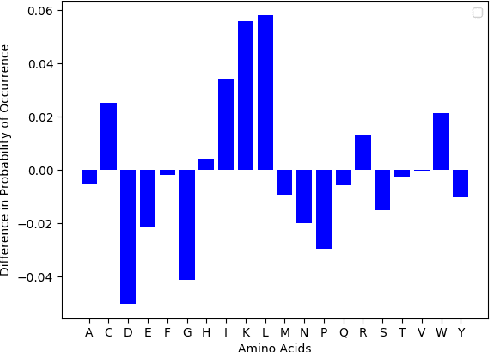
Given the emerging global threat of antimicrobial resistance, new methods for next-generation antimicrobial design are urgently needed. We report a peptide generation framework PepCVAE, based on a semi-supervised variational autoencoder (VAE) model, for designing novel antimicrobial peptide (AMP) sequences. Our model learns a rich latent space of the biological peptide context by taking advantage of abundant, unlabeled peptide sequences. The model further learns a disentangled antimicrobial attribute space by using the feedback from a jointly trained AMP classifier that uses limited labeled instances. The disentangled representation allows for controllable generation of AMPs. Extensive analysis of the PepCVAE-generated sequences reveals superior performance of our model in comparison to a plain VAE, as PepCVAE generates novel AMP sequences with higher long-range diversity, while being closer to the training distribution of biological peptides. These features are highly desired in next-generation antimicrobial design.
AI Fairness 360: An Extensible Toolkit for Detecting, Understanding, and Mitigating Unwanted Algorithmic Bias
Oct 03, 2018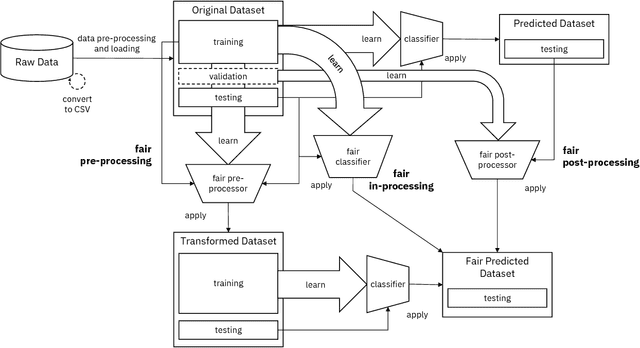
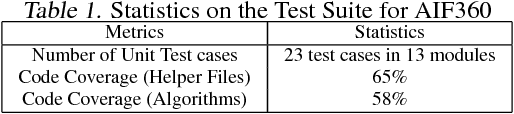
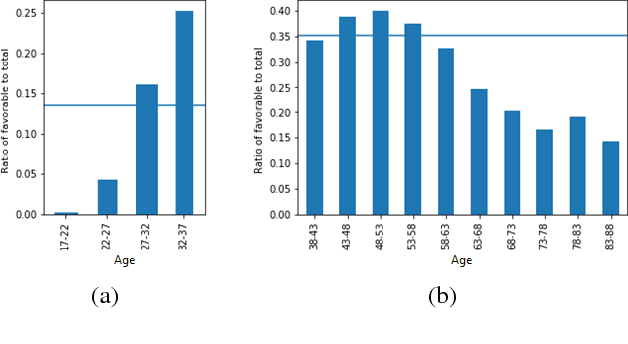
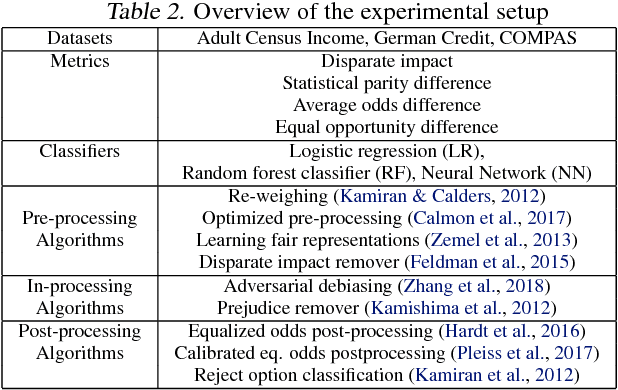
Fairness is an increasingly important concern as machine learning models are used to support decision making in high-stakes applications such as mortgage lending, hiring, and prison sentencing. This paper introduces a new open source Python toolkit for algorithmic fairness, AI Fairness 360 (AIF360), released under an Apache v2.0 license {https://github.com/ibm/aif360). The main objectives of this toolkit are to help facilitate the transition of fairness research algorithms to use in an industrial setting and to provide a common framework for fairness researchers to share and evaluate algorithms. The package includes a comprehensive set of fairness metrics for datasets and models, explanations for these metrics, and algorithms to mitigate bias in datasets and models. It also includes an interactive Web experience (https://aif360.mybluemix.net) that provides a gentle introduction to the concepts and capabilities for line-of-business users, as well as extensive documentation, usage guidance, and industry-specific tutorials to enable data scientists and practitioners to incorporate the most appropriate tool for their problem into their work products. The architecture of the package has been engineered to conform to a standard paradigm used in data science, thereby further improving usability for practitioners. Such architectural design and abstractions enable researchers and developers to extend the toolkit with their new algorithms and improvements, and to use it for performance benchmarking. A built-in testing infrastructure maintains code quality.