 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Antimicrobial Discovery with Controllable Deep Generative Models and Molecular Dynamics
May 22, 2020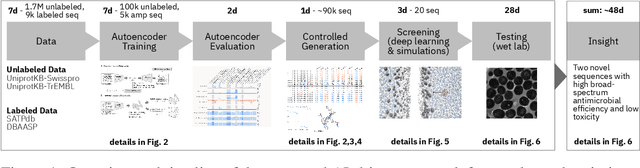
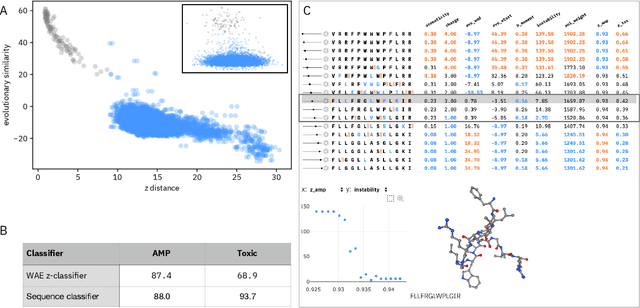
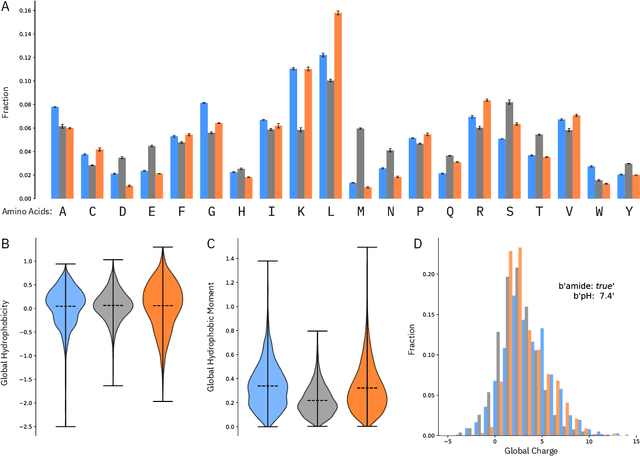
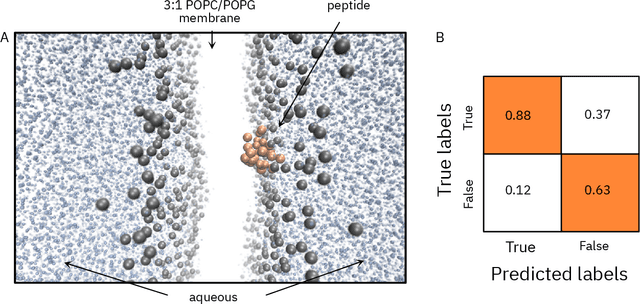
De novo therapeutic design is challenged by a vast chemical repertoire and multiple constraints such as high broad-spectrum potency and low toxicity. We propose CLaSS (Controlled Latent attribute Space Sampling) - a novel and efficient computational method for attribute-controlled generation of molecules, which leverages guidance from classifiers trained on an informative latent space of molecules modeled using a deep generative autoencoder. We further screen the generated molecules by using a set of deep learning classifiers in conjunction with novel physicochemical features derived from high-throughput molecular simulations. The proposed approach is employed for designing non-toxic antimicrobial peptides (AMPs) with strong broad-spectrum potency, which are emerging drug candidates for tackling antibiotic resistance. Synthesis and wet lab testing of only twenty designed sequences identified two novel and minimalist AMPs with high potency against diverse Gram-positive and Gram-negative pathogens, including the hard-to-treat multidrug-resistant K. pneumoniae, as well as low in vitro and in vivo toxicity. The proposed approach thus presents a viable path for faster discovery of potent and selective broad-spectrum antimicrobials with a higher success rate than state-of-the-art methods.
Improved Neural Relation Detection for Knowledge Base Question Answering
May 27, 2017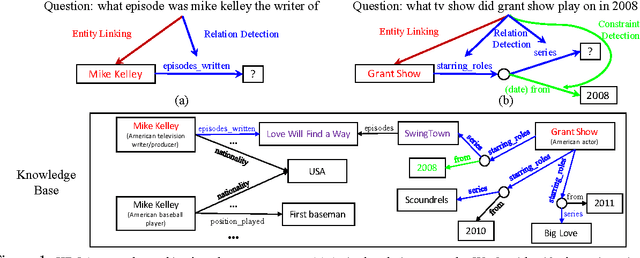

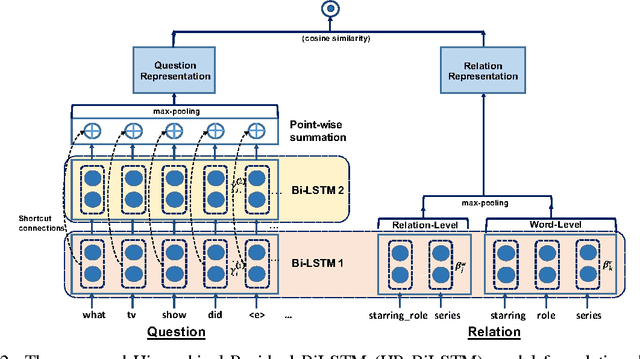
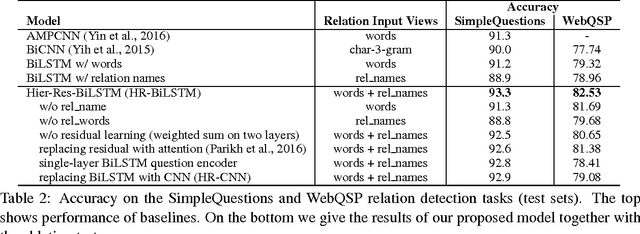
Relation detection is a core component for many NLP applications including Knowledge Base Question Answering (KBQA). In this paper, we propose a hierarchical recurrent neural network enhanced by residual learning that detects KB relations given an input question. Our method uses deep residual bidirectional LSTMs to compare questions and relation names via different hierarchies of abstraction. Additionally, we propose a simple KBQA system that integrates entity linking and our proposed relation detector to enable one enhance another. Experimental results evidence that our approach achieves not only outstanding relation detection performance, but more importantly, it helps our KBQA system to achieve state-of-the-art accuracy for both single-relation (SimpleQuestions) and multi-relation (WebQSP) QA benchmarks.
LSTM-based Deep Learning Models for Non-factoid Answer Selection
Mar 28, 2016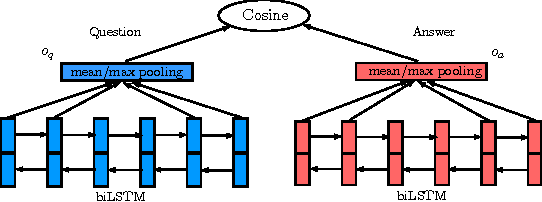
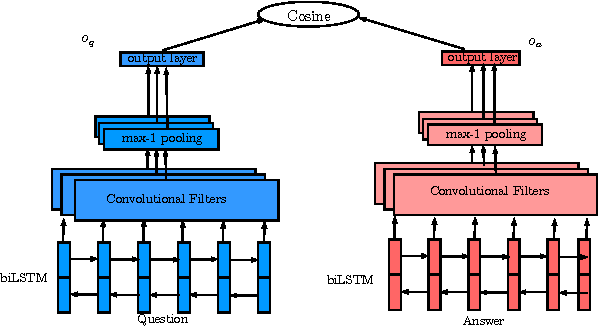

In this paper, we apply a general deep learning (DL) framework for the answer selection task, which does not depend on manually defined features or linguistic tools. The basic framework is to build the embeddings of questions and answers based on bidirectional long short-term memory (biLSTM) models, and measure their closeness by cosine similarity. We further extend this basic model in two directions. One direction is to define a more composite representation for questions and answers by combining convolutional neural network with the basic framework. The other direction is to utilize a simple but efficient attention mechanism in order to generate the answer representation according to the question context. Several variations of models are provided. The models are examined by two datasets, including TREC-QA and InsuranceQA. Experimental results demonstrate that the proposed models substantially outperform several strong baselines.
Attentive Pooling Networks
Feb 11, 2016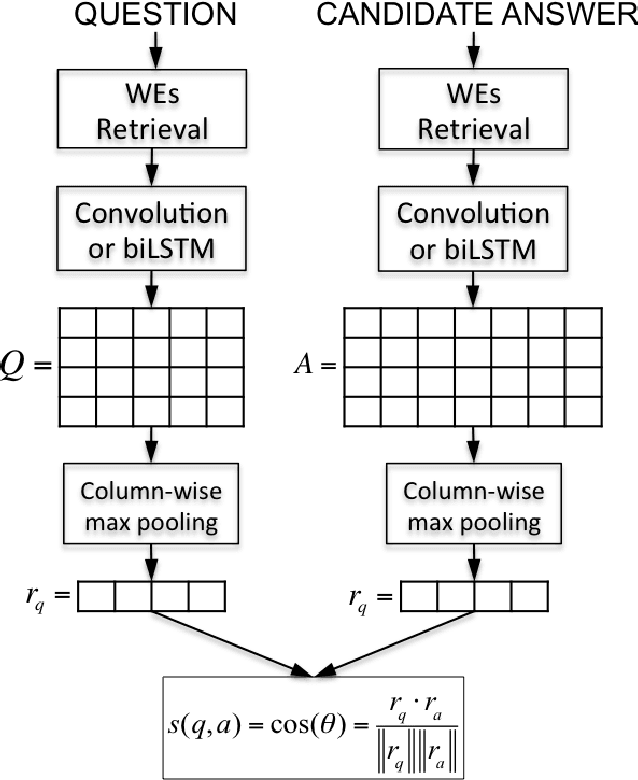

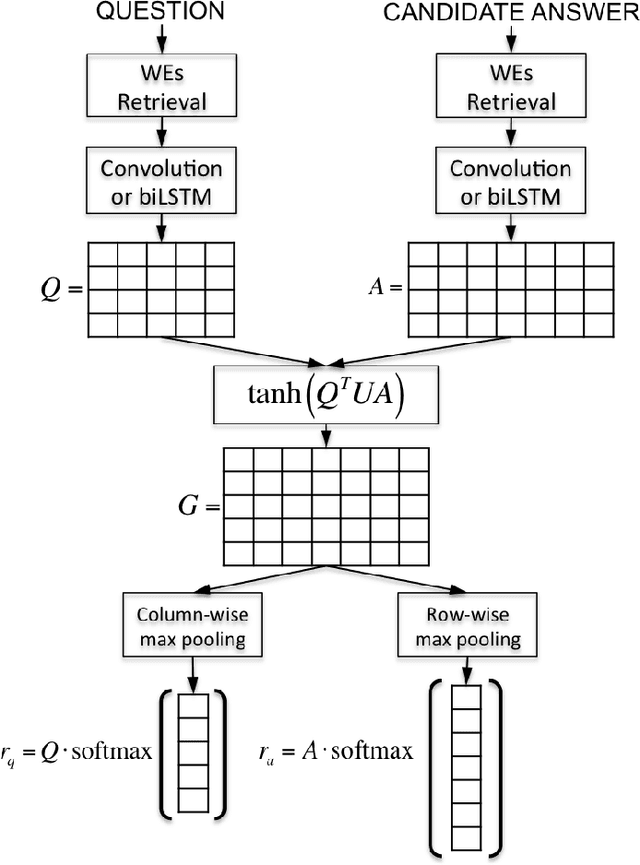
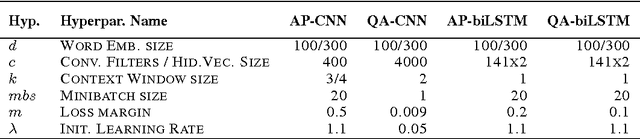
In this work, we propose Attentive Pooling (AP), a two-way attention mechanism for discriminative model training. In the context of pair-wise ranking or classification with neural networks, AP enables the pooling layer to be aware of the current input pair, in a way that information from the two input items can directly influence the computation of each other's representations. Along with such representations of the paired inputs, AP jointly learns a similarity measure over projected segments (e.g. trigrams) of the pair, and subsequently, derives the corresponding attention vector for each input to guide the pooling. Our two-way attention mechanism is a general framework independent of the underlying representation learning, and it has been applied to both convolutional neural networks (CNNs) and recurrent neural networks (RNNs) in our studies. The empirical results, from three very different benchmark tasks of question answering/answer selection, demonstrate that our proposed models outperform a variety of strong baselines and achieve state-of-the-art performance in all the benchmarks.