 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Antimicrobial Discovery with Controllable Deep Generative Models and Molecular Dynamics
May 22, 2020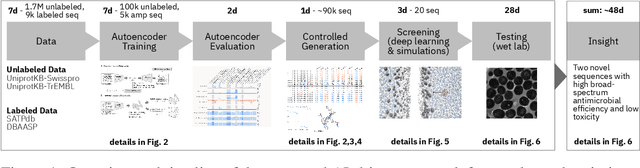
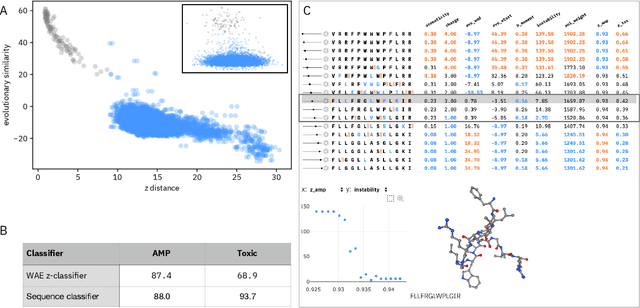
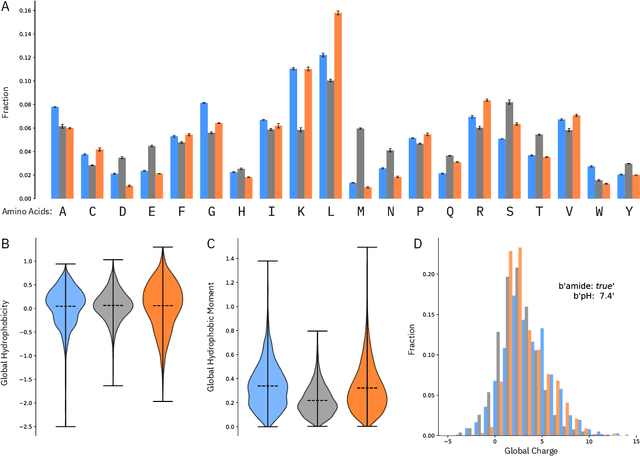
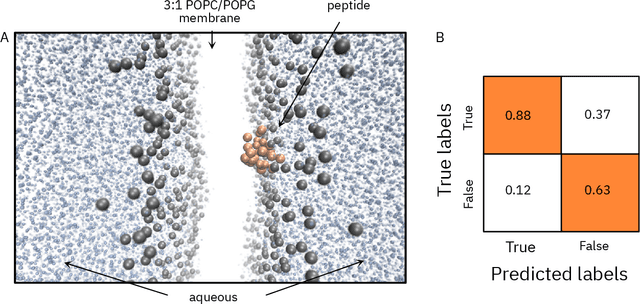
De novo therapeutic design is challenged by a vast chemical repertoire and multiple constraints such as high broad-spectrum potency and low toxicity. We propose CLaSS (Controlled Latent attribute Space Sampling) - a novel and efficient computational method for attribute-controlled generation of molecules, which leverages guidance from classifiers trained on an informative latent space of molecules modeled using a deep generative autoencoder. We further screen the generated molecules by using a set of deep learning classifiers in conjunction with novel physicochemical features derived from high-throughput molecular simulations. The proposed approach is employed for designing non-toxic antimicrobial peptides (AMPs) with strong broad-spectrum potency, which are emerging drug candidates for tackling antibiotic resistance. Synthesis and wet lab testing of only twenty designed sequences identified two novel and minimalist AMPs with high potency against diverse Gram-positive and Gram-negative pathogens, including the hard-to-treat multidrug-resistant K. pneumoniae, as well as low in vitro and in vivo toxicity. The proposed approach thus presents a viable path for faster discovery of potent and selective broad-spectrum antimicrobials with a higher success rate than state-of-the-art methods.
Sobolev Independence Criterion
Oct 31, 2019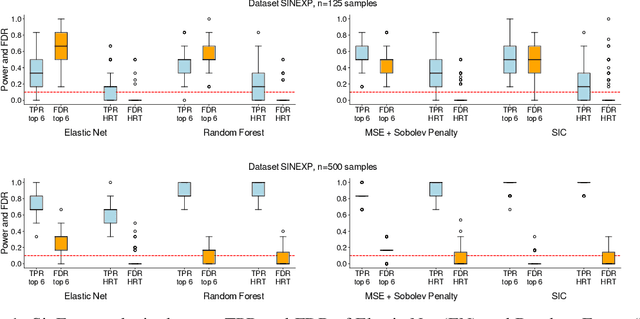
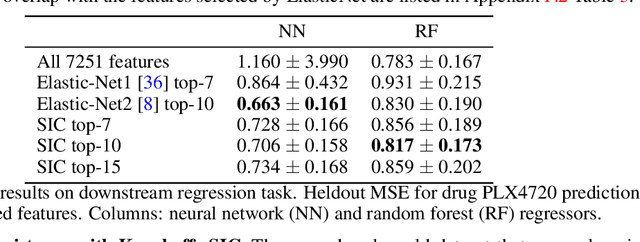
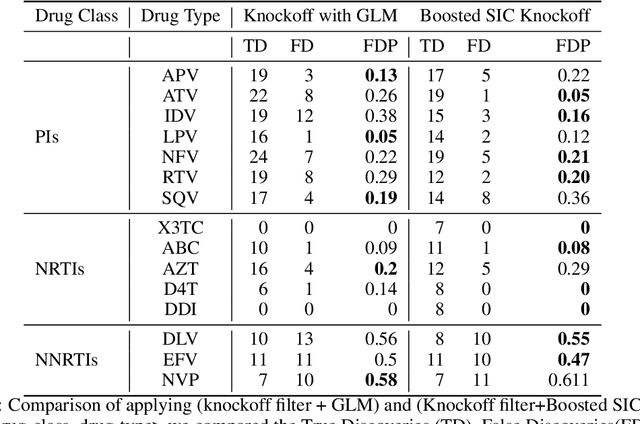
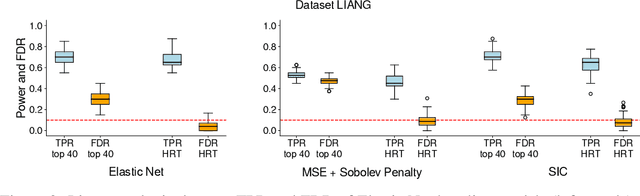
We propose the Sobolev Independence Criterion (SIC), an interpretable dependency measure between a high dimensional random variable X and a response variable Y . SIC decomposes to the sum of feature importance scores and hence can be used for nonlinear feature selection. SIC can be seen as a gradient regularized Integral Probability Metric (IPM) between the joint distribution of the two random variables and the product of their marginals. We use sparsity inducing gradient penalties to promote input sparsity of the critic of the IPM. In the kernel version we show that SIC can be cast as a convex optimization problem by introducing auxiliary variables that play an important role in feature selection as they are normalized feature importance scores. We then present a neural version of SIC where the critic is parameterized as a homogeneous neural network, improving its representation power as well as its interpretability. We conduct experiments validating SIC for feature selection in synthetic and real-world experiments. We show that SIC enables reliable and interpretable discoveries, when used in conjunction with the holdout randomization test and knockoffs to control the False Discovery Rate. Code is available at http://github.com/ibm/sic.
Multi-Frame Cross-Entropy Training for Convolutional Neural Networks in Speech Recognition
Jul 29, 2019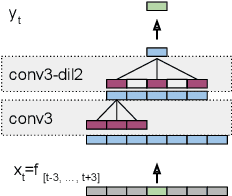
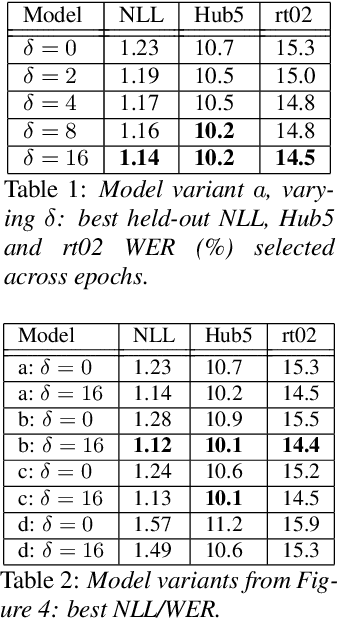
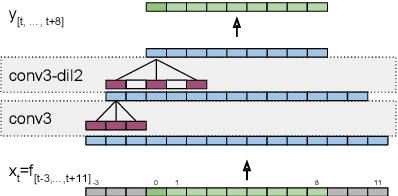
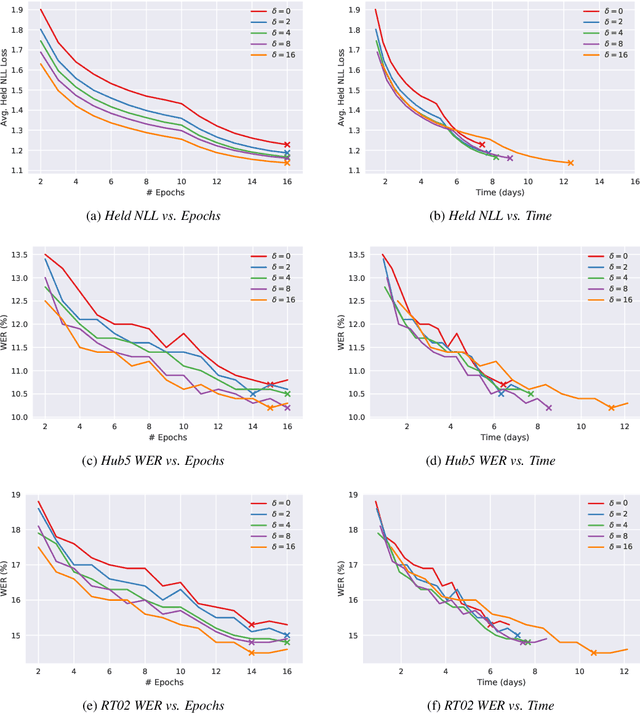
We introduce Multi-Frame Cross-Entropy training (MFCE) for convolutional neural network acoustic models. Recognizing that similar to RNNs, CNNs are in nature sequence models that take variable length inputs, we propose to take as input to the CNN a part of an utterance long enough that multiple labels are predicted at once, therefore getting cross-entropy loss signal from multiple adjacent frames. This increases the amount of label information drastically for small marginal computational cost. We show large WER improvements on hub5 and rt02 after training on the 2000-hour Switchboard benchmark.
Wasserstein Barycenter Model Ensembling
Feb 13, 2019
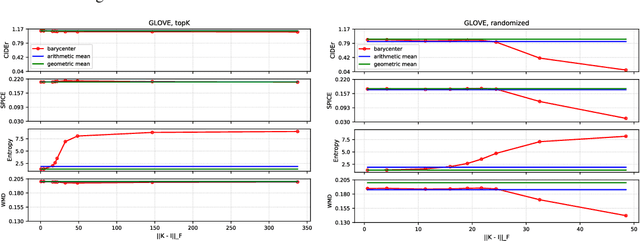


In this paper we propose to perform model ensembling in a multiclass or a multilabel learning setting using Wasserstein (W.) barycenters. Optimal transport metrics, such as the Wasserstein distance, allow incorporating semantic side information such as word embeddings. Using W. barycenters to find the consensus between models allows us to balance confidence and semantics in finding the agreement between the models. We show applications of Wasserstein ensembling in attribute-based classification, multilabel learning and image captioning generation. These results show that the W. ensembling is a viable alternative to the basic geometric or arithmetic mean ensembling.
PepCVAE: Semi-Supervised Targeted Design of Antimicrobial Peptide Sequences
Oct 22, 2018

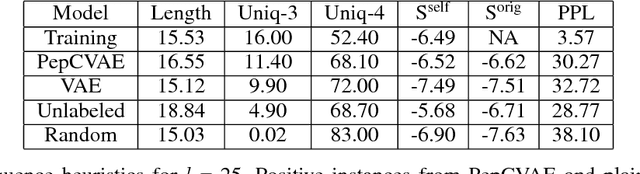
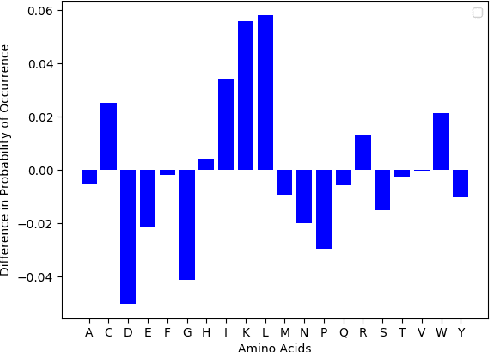
Given the emerging global threat of antimicrobial resistance, new methods for next-generation antimicrobial design are urgently needed. We report a peptide generation framework PepCVAE, based on a semi-supervised variational autoencoder (VAE) model, for designing novel antimicrobial peptide (AMP) sequences. Our model learns a rich latent space of the biological peptide context by taking advantage of abundant, unlabeled peptide sequences. The model further learns a disentangled antimicrobial attribute space by using the feedback from a jointly trained AMP classifier that uses limited labeled instances. The disentangled representation allows for controllable generation of AMPs. Extensive analysis of the PepCVAE-generated sequences reveals superior performance of our model in comparison to a plain VAE, as PepCVAE generates novel AMP sequences with higher long-range diversity, while being closer to the training distribution of biological peptides. These features are highly desired in next-generation antimicrobial design.
Big-Little Net: An Efficient Multi-Scale Feature Representation for Visual and Speech Recognition
Jul 10, 2018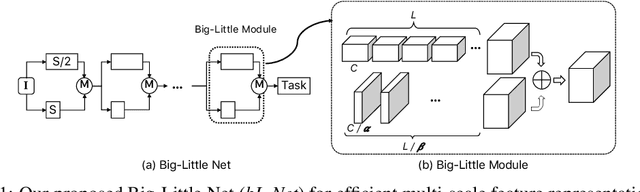
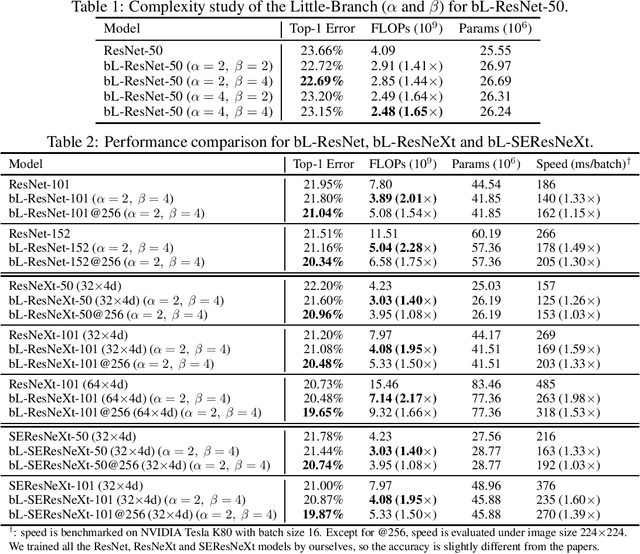
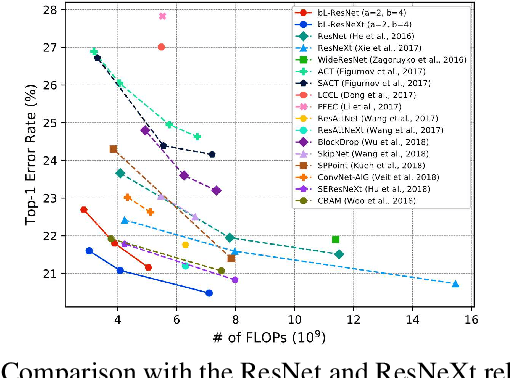
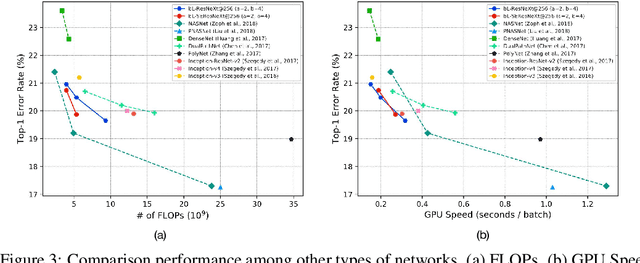
In this paper, we propose a novel Convolutional Neural Network (CNN) architecture for learning multi-scale feature representations with good tradeoffs between speed and accuracy. This is achieved by using a multi-branch network, which has different computational complexity at different branches. Through frequent merging of features from branches at distinct scales, our model obtains multi-scale features while using less computation. The proposed approach demonstrates improvement of model efficiency and performance on both object recognition and speech recognition tasks,using popular architectures including ResNet and ResNeXt. For object recognition, our approach reduces computation by 33% on object recognition while improving accuracy with 0.9%. Furthermore, our model surpasses state-of-the-art CNN acceleration approaches by a large margin in accuracy and FLOPs reduction. On the task of speech recognition, our proposed multi-scale CNNs save 30% FLOPs with slightly better word error rates, showing good generalization across domains.
Improved Image Captioning with Adversarial Semantic Alignment
Jun 01, 2018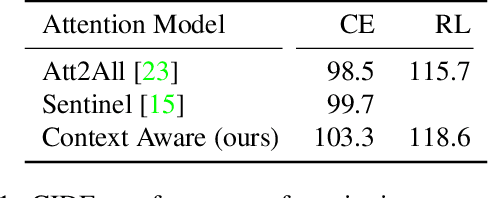
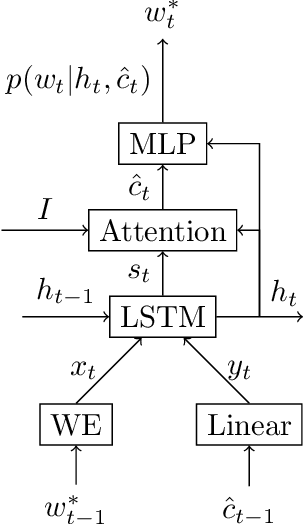
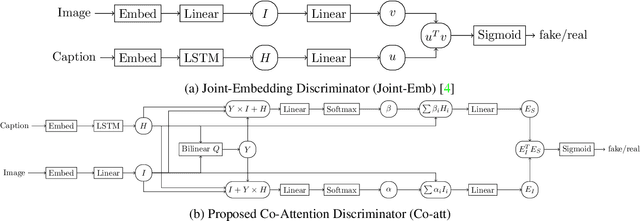
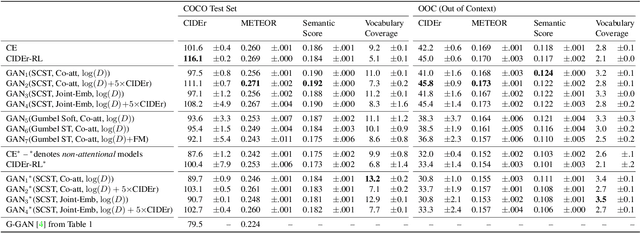
We study image captioning as a conditional GAN training, proposing both a context-aware LSTM captioner and co-attentive discriminator, which enforces semantic alignment between images and captions. We empirically study the viability of two training methods: Self-critical Sequence Training (SCST) and Gumbel Straight-Through (ST). We show that, surprisingly, SCST (a policy gradient method) shows more stable gradient behavior and improved results over Gumbel ST, even without accessing the discriminator gradients directly. We also address the open question of automatic evaluation for these models and introduce a new semantic score and demonstrate its strong correlation to human judgement. As an evaluation paradigm, we suggest that an important criterion is the ability of a captioner to generalize to compositions between objects that do not usually occur together, for which we introduce a captioned Out of Context (OOC) test set. The OOC dataset combined with our semantic score is a new benchmark for the captioning community. Under this OOC benchmark, and the traditional MSCOCO dataset, we show that SCST has a strong performance in both semantic score and human evaluation.
Regularized Kernel and Neural Sobolev Descent: Dynamic MMD Transport
May 30, 2018


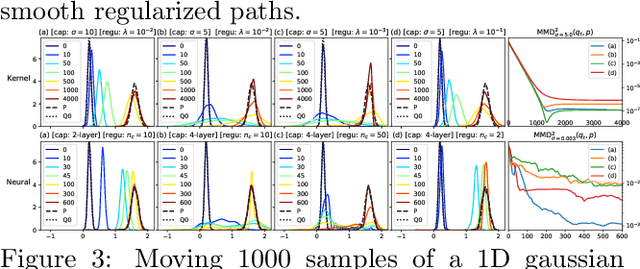
We introduce Regularized Kernel and Neural Sobolev Descent for transporting a source distribution to a target distribution along smooth paths of minimum kinetic energy (defined by the Sobolev discrepancy), related to dynamic optimal transport. In the kernel version, we give a simple algorithm to perform the descent along gradients of the Sobolev critic, and show that it converges asymptotically to the target distribution in the MMD sense. In the neural version, we parametrize the Sobolev critic with a neural network with input gradient norm constrained in expectation. We show in theory and experiments that regularization has an important role in favoring smooth transitions between distributions, avoiding large discrete jumps. Our analysis could provide a new perspective on the impact of critic updates (early stopping) on the paths to equilibrium in the GAN setting.
Semi-Supervised Learning with IPM-based GANs: an Empirical Study
Dec 07, 2017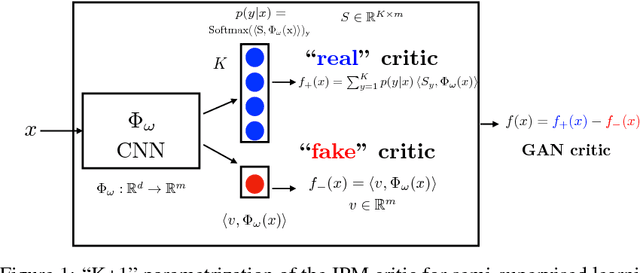
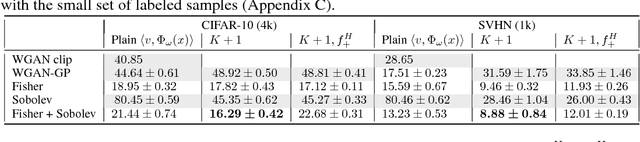

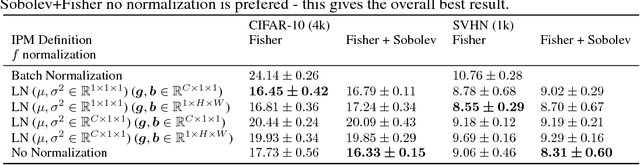
We present an empirical investigation of a recent class of Generative Adversarial Networks (GANs) using Integral Probability Metrics (IPM) and their performance for semi-supervised learning. IPM-based GANs like Wasserstein GAN, Fisher GAN and Sobolev GAN have desirable properties in terms of theoretical understanding, training stability, and a meaningful loss. In this work we investigate how the design of the critic (or discriminator) influences the performance in semi-supervised learning. We distill three key take-aways which are important for good SSL performance: (1) the K+1 formulation, (2) avoiding batch normalization in the critic and (3) avoiding gradient penalty constraints on the classification layer.
Sobolev GAN
Nov 14, 2017
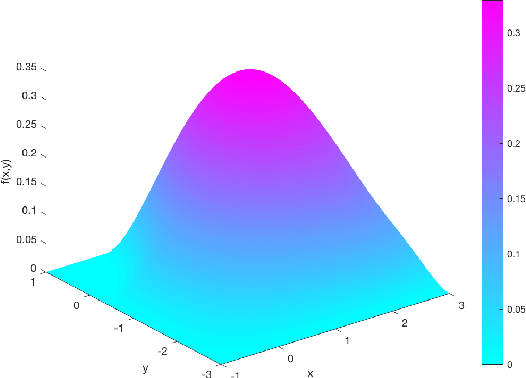


We propose a new Integral Probability Metric (IPM) between distributions: the Sobolev IPM. The Sobolev IPM compares the mean discrepancy of two distributions for functions (critic) restricted to a Sobolev ball defined with respect to a dominant measure $\mu$. We show that the Sobolev IPM compares two distributions in high dimensions based on weighted conditional Cumulative Distribution Functions (CDF) of each coordinate on a leave one out basis. The Dominant measure $\mu$ plays a crucial role as it defines the support on which conditional CDFs are compared. Sobolev IPM can be seen as an extension of the one dimensional Von-Mises Cram\'er statistics to high dimensional distributions. We show how Sobolev IPM can be used to train Generative Adversarial Networks (GANs). We then exploit the intrinsic conditioning implied by Sobolev IPM in text generation. Finally we show that a variant of Sobolev GAN achieves competitive results in semi-supervised learning on CIFAR-10, thanks to the smoothness enforced on the critic by Sobolev GAN which relates to Laplacian regularization.