 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReGen: Reinforcement Learning for Text and Knowledge Base Generation using Pretrained Language Models
Aug 27, 2021
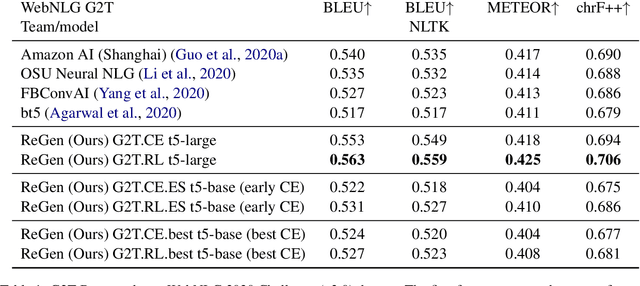
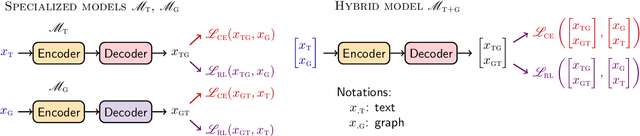
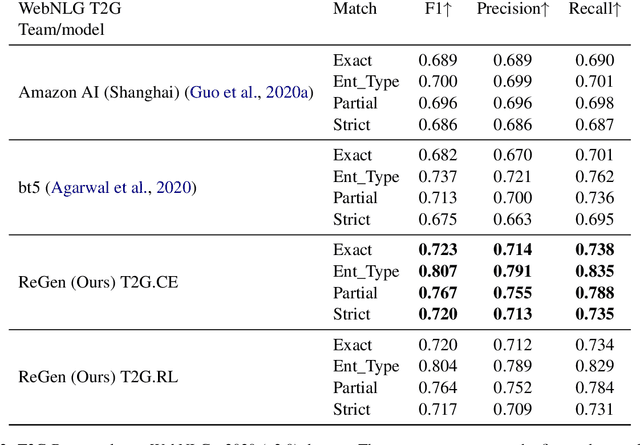
Automatic construction of relevant Knowledge Bases (KBs) from text, and generation of semantically meaningful text from KBs are both long-standing goals in Machine Learning. In this paper, we present ReGen, a bidirectional generation of text and graph leveraging Reinforcement Learning (RL) to improve performance. Graph linearization enables us to re-frame both tasks as a sequence to sequence generation problem regardless of the generative direction, which in turn allows the use of Reinforcement Learning for sequence training where the model itself is employed as its own critic leading to Self-Critical Sequence Training (SCST). We present an extensive investigation demonstrating that the use of RL via SCST benefits graph and text generation on WebNLG+ 2020 and TekGen datasets. Our system provides state-of-the-art results on WebNLG+ 2020 by significantly improving upon published results from the WebNLG 2020+ Challenge for both text-to-graph and graph-to-text generation tasks.
DualTKB: A Dual Learning Bridge between Text and Knowledge Base
Oct 27, 2020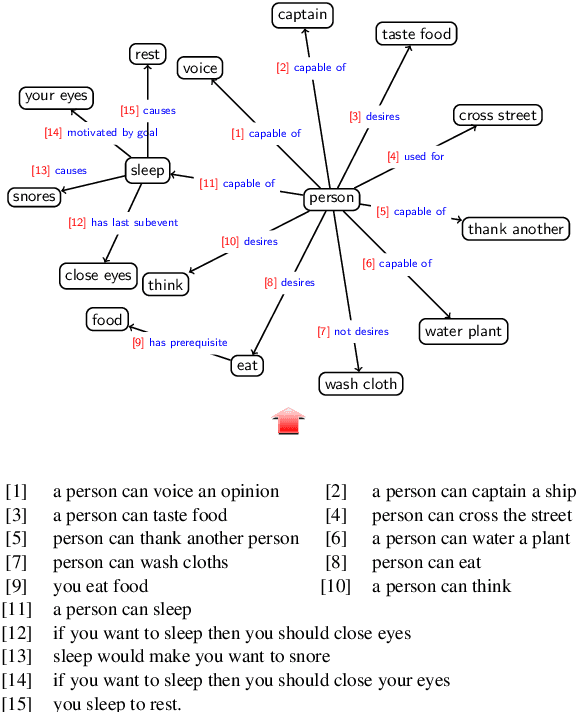

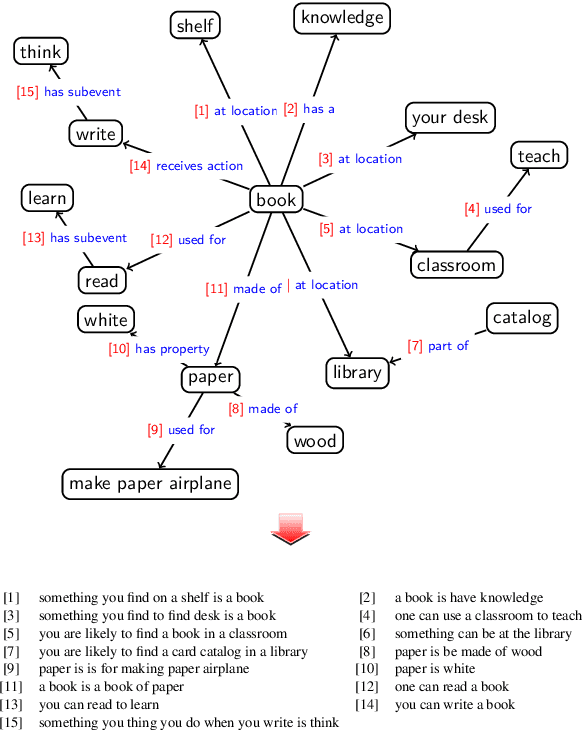
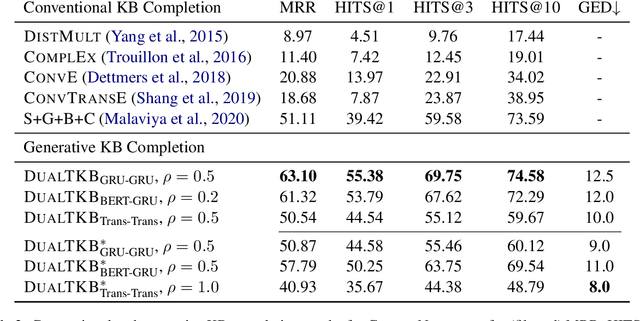
In this work, we present a dual learning approach for unsupervised text to path and path to text transfers in Commonsense Knowledge Bases (KBs). We investigate the impact of weak supervision by creating a weakly supervised dataset and show that even a slight amount of supervision can significantly improve the model performance and enable better-quality transfers. We examine different model architectures, and evaluation metrics, proposing a novel Commonsense KB completion metric tailored for generative models. Extensive experimental results show that the proposed method compares very favorably to the existing baselines. This approach is a viable step towards a more advanced system for automatic KB construction/expansion and the reverse operation of KB conversion to coherent textual descriptions.
Improved Image Captioning with Adversarial Semantic Alignment
Jun 01, 2018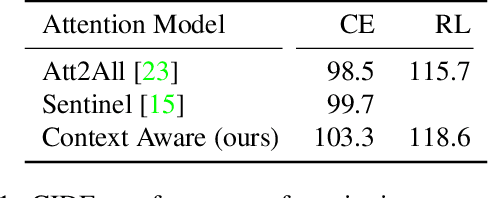
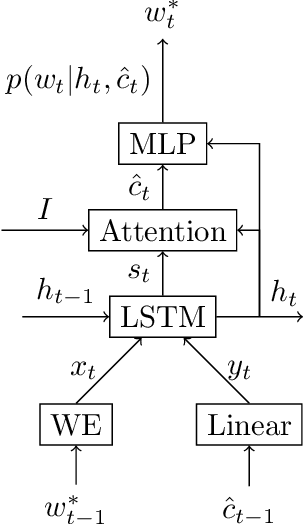
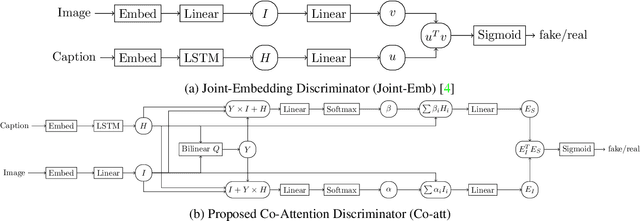
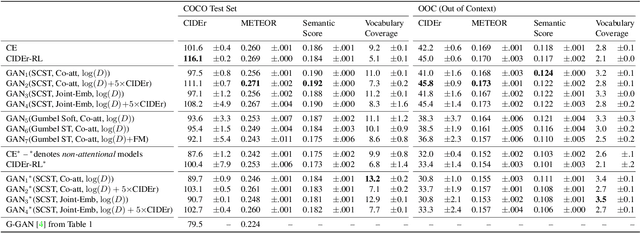
We study image captioning as a conditional GAN training, proposing both a context-aware LSTM captioner and co-attentive discriminator, which enforces semantic alignment between images and captions. We empirically study the viability of two training methods: Self-critical Sequence Training (SCST) and Gumbel Straight-Through (ST). We show that, surprisingly, SCST (a policy gradient method) shows more stable gradient behavior and improved results over Gumbel ST, even without accessing the discriminator gradients directly. We also address the open question of automatic evaluation for these models and introduce a new semantic score and demonstrate its strong correlation to human judgement. As an evaluation paradigm, we suggest that an important criterion is the ability of a captioner to generalize to compositions between objects that do not usually occur together, for which we introduce a captioned Out of Context (OOC) test set. The OOC dataset combined with our semantic score is a new benchmark for the captioning community. Under this OOC benchmark, and the traditional MSCOCO dataset, we show that SCST has a strong performance in both semantic score and human evaluation.