 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGP-MoLFormer-Sim: Test Time Molecular Optimization through Contextual Similarity Guidance
Jun 05, 2025The ability to design molecules while preserving similarity to a target molecule and/or property is crucial for various applications in drug discovery, chemical design, and biology. We introduce in this paper an efficient training-free method for navigating and sampling from the molecular space with a generative Chemical Language Model (CLM), while using the molecular similarity to the target as a guide. Our method leverages the contextual representations learned from the CLM itself to estimate the molecular similarity, which is then used to adjust the autoregressive sampling strategy of the CLM. At each step of the decoding process, the method tracks the distance of the current generations from the target and updates the logits to encourage the preservation of similarity in generations. We implement the method using a recently proposed $\sim$47M parameter SMILES-based CLM, GP-MoLFormer, and therefore refer to the method as GP-MoLFormer-Sim, which enables a test-time update of the deep generative policy to reflect the contextual similarity to a set of guide molecules. The method is further integrated into a genetic algorithm (GA) and tested on a set of standard molecular optimization benchmarks involving property optimization, molecular rediscovery, and structure-based drug design. Results show that, GP-MoLFormer-Sim, combined with GA (GP-MoLFormer-Sim+GA) outperforms existing training-free baseline methods, when the oracle remains black-box. The findings in this work are a step forward in understanding and guiding the generative mechanisms of CLMs.
Cloud-Based Real-Time Molecular Screening Platform with MolFormer
Aug 13, 2022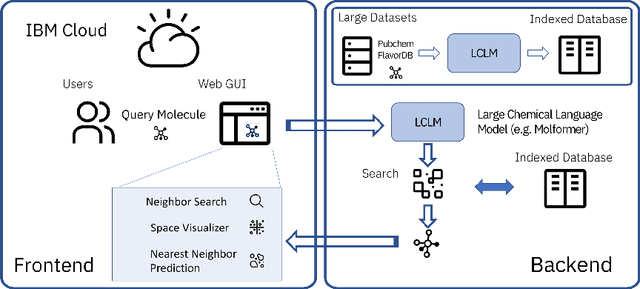
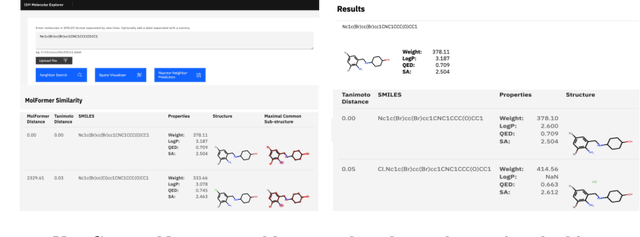

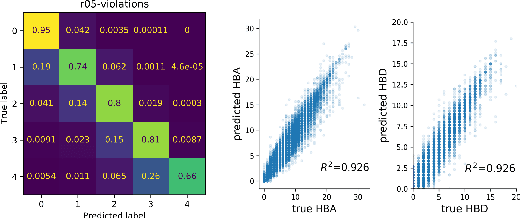
With the prospect of automating a number of chemical tasks with high fidelity, chemical language processing models are emerging at a rapid speed. Here, we present a cloud-based real-time platform that allows users to virtually screen molecules of interest. For this purpose, molecular embeddings inferred from a recently proposed large chemical language model, named MolFormer, are leveraged. The platform currently supports three tasks: nearest neighbor retrieval, chemical space visualization, and property prediction. Based on the functionalities of this platform and results obtained, we believe that such a platform can play a pivotal role in automating chemistry and chemical engineering research, as well as assist in drug discovery and material design tasks. A demo of our platform is provided at \url{www.ibm.biz/molecular_demo}.
Image Captioning as an Assistive Technology: Lessons Learned from VizWiz 2020 Challenge
Dec 21, 2020
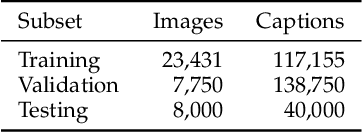
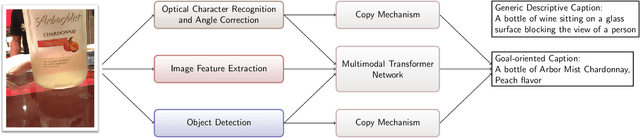
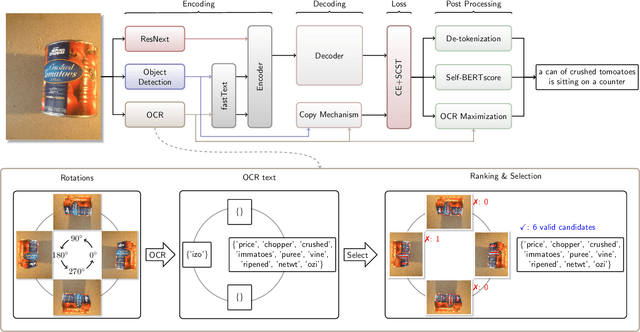
Image captioning has recently demonstrated impressive progress largely owing to the introduction of neural network algorithms trained on curated dataset like MS-COCO. Often work in this field is motivated by the promise of deployment of captioning systems in practical applications. However, the scarcity of data and contexts in many competition datasets renders the utility of systems trained on these datasets limited as an assistive technology in real-world settings, such as helping visually impaired people navigate and accomplish everyday tasks. This gap motivated the introduction of the novel VizWiz dataset, which consists of images taken by the visually impaired and captions that have useful, task-oriented information. In an attempt to help the machine learning computer vision field realize its promise of producing technologies that have positive social impact, the curators of the VizWiz dataset host several competitions, including one for image captioning. This work details the theory and engineering from our winning submission to the 2020 captioning competition. Our work provides a step towards improved assistive image captioning systems.
Alleviating Noisy Data in Image Captioning with Cooperative Distillation
Dec 21, 2020


Image captioning systems have made substantial progress, largely due to the availability of curated datasets like Microsoft COCO or Vizwiz that have accurate descriptions of their corresponding images. Unfortunately, scarce availability of such cleanly labeled data results in trained algorithms producing captions that can be terse and idiosyncratically specific to details in the image. We propose a new technique, cooperative distillation that combines clean curated datasets with the web-scale automatically extracted captions of the Google Conceptual Captions dataset (GCC), which can have poor descriptions of images, but is abundant in size and therefore provides a rich vocabulary resulting in more expressive captions.
Improved Image Captioning with Adversarial Semantic Alignment
Jun 01, 2018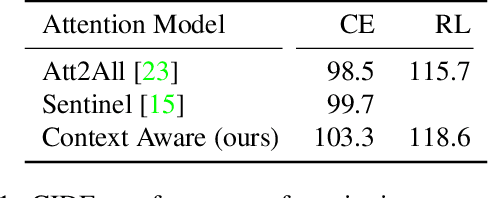
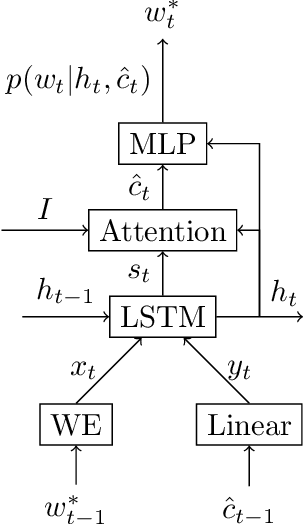
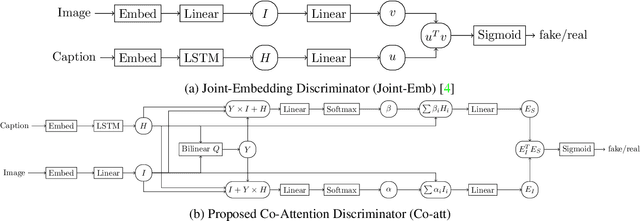
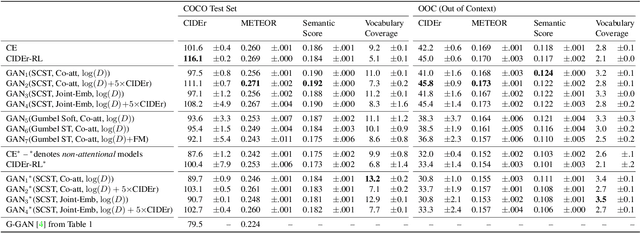
We study image captioning as a conditional GAN training, proposing both a context-aware LSTM captioner and co-attentive discriminator, which enforces semantic alignment between images and captions. We empirically study the viability of two training methods: Self-critical Sequence Training (SCST) and Gumbel Straight-Through (ST). We show that, surprisingly, SCST (a policy gradient method) shows more stable gradient behavior and improved results over Gumbel ST, even without accessing the discriminator gradients directly. We also address the open question of automatic evaluation for these models and introduce a new semantic score and demonstrate its strong correlation to human judgement. As an evaluation paradigm, we suggest that an important criterion is the ability of a captioner to generalize to compositions between objects that do not usually occur together, for which we introduce a captioned Out of Context (OOC) test set. The OOC dataset combined with our semantic score is a new benchmark for the captioning community. Under this OOC benchmark, and the traditional MSCOCO dataset, we show that SCST has a strong performance in both semantic score and human evaluation.
Self-critical Sequence Training for Image Captioning
Nov 16, 2017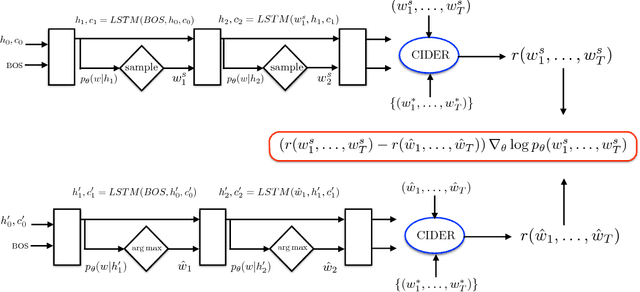
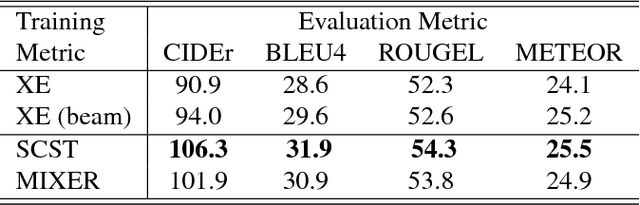
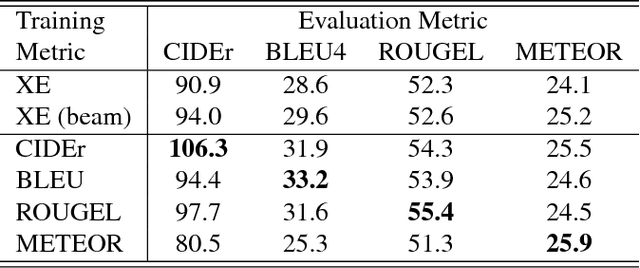

Recently it has been shown that policy-gradient methods for reinforcement learning can be utilized to train deep end-to-end systems directly on non-differentiable metrics for the task at hand. In this paper we consider the problem of optimizing image captioning systems using reinforcement learning, and show that by carefully optimizing our systems using the test metrics of the MSCOCO task, significant gains in performance can be realized. Our systems are built using a new optimization approach that we call self-critical sequence training (SCST). SCST is a form of the popular REINFORCE algorithm that, rather than estimating a "baseline" to normalize the rewards and reduce variance, utilizes the output of its own test-time inference algorithm to normalize the rewards it experiences. Using this approach, estimating the reward signal (as actor-critic methods must do) and estimating normalization (as REINFORCE algorithms typically do) is avoided, while at the same time harmonizing the model with respect to its test-time inference procedure. Empirically we find that directly optimizing the CIDEr metric with SCST and greedy decoding at test-time is highly effective. Our results on the MSCOCO evaluation sever establish a new state-of-the-art on the task, improving the best result in terms of CIDEr from 104.9 to 114.7.