 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-critical Sequence Training for Image Captioning
Nov 16, 2017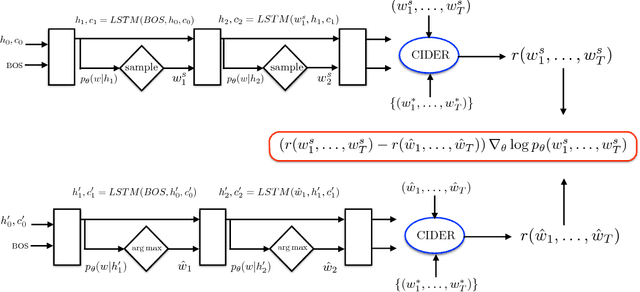
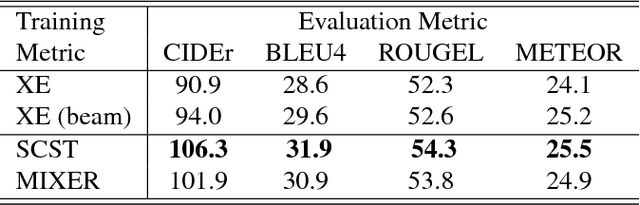
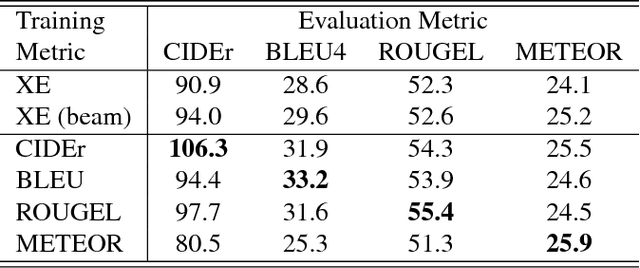

Recently it has been shown that policy-gradient methods for reinforcement learning can be utilized to train deep end-to-end systems directly on non-differentiable metrics for the task at hand. In this paper we consider the problem of optimizing image captioning systems using reinforcement learning, and show that by carefully optimizing our systems using the test metrics of the MSCOCO task, significant gains in performance can be realized. Our systems are built using a new optimization approach that we call self-critical sequence training (SCST). SCST is a form of the popular REINFORCE algorithm that, rather than estimating a "baseline" to normalize the rewards and reduce variance, utilizes the output of its own test-time inference algorithm to normalize the rewards it experiences. Using this approach, estimating the reward signal (as actor-critic methods must do) and estimating normalization (as REINFORCE algorithms typically do) is avoided, while at the same time harmonizing the model with respect to its test-time inference procedure. Empirically we find that directly optimizing the CIDEr metric with SCST and greedy decoding at test-time is highly effective. Our results on the MSCOCO evaluation sever establish a new state-of-the-art on the task, improving the best result in terms of CIDEr from 104.9 to 114.7.
Asymmetrically Weighted CCA And Hierarchical Kernel Sentence Embedding For Image & Text Retrieval
Dec 05, 2016
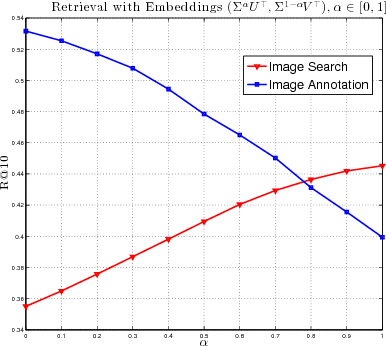
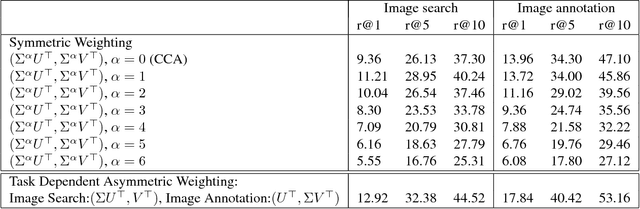
Joint modeling of language and vision has been drawing increasing interest. A multimodal data representation allowing for bidirectional retrieval of images by sentences and vice versa is a key aspect. In this paper we present three contributions in canonical correlation analysis (CCA) based multimodal retrieval. Firstly, we show that an asymmetric weighting of the canonical weights, while achieving a cross view mapping from the search to the query space, improves the retrieval performance. Secondly, we devise a computationally efficient model selection, crucial to generalization and stability, in the framework of the Bj\"ork Golub algorithm for regularized CCA via spectral filtering. Finally, we introduce a Hierarchical Kernel Sentence Embedding (HKSE) that approximates Kernel CCA for a special similarity kernel between distribution of words embedded in a vector space. State of the art results are obtained on MSCOCO and Flickr benchmarks when these three techniques are used in conjunction.
Co-Occuring Directions Sketching for Approximate Matrix Multiply
Oct 25, 2016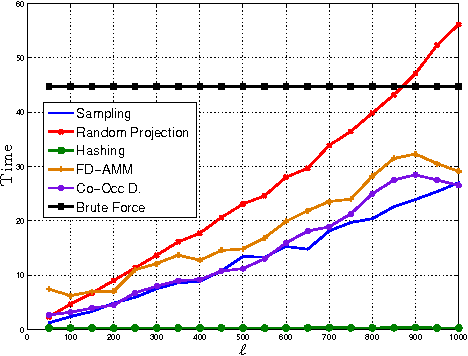
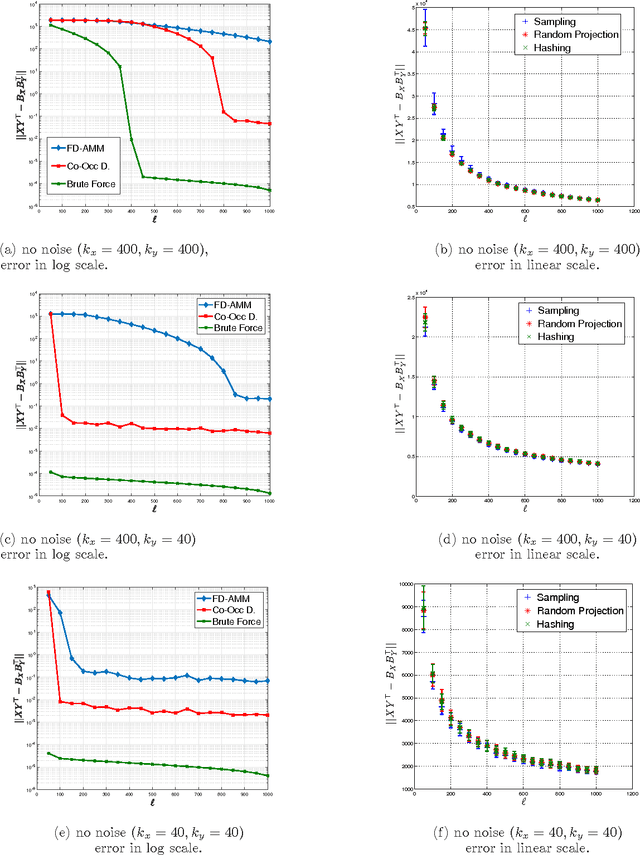
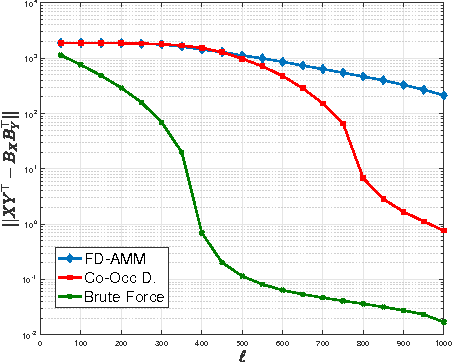
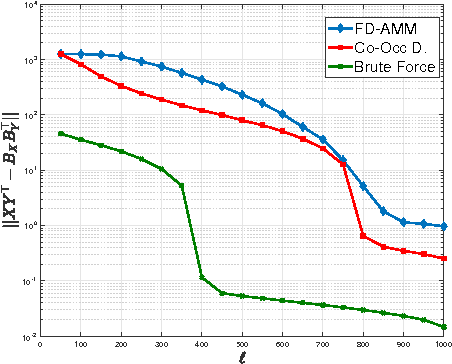
We introduce co-occurring directions sketching, a deterministic algorithm for approximate matrix product (AMM), in the streaming model. We show that co-occuring directions achieves a better error bound for AMM than other randomized and deterministic approaches for AMM. Co-occurring directions gives a $1 + \epsilon$ -approximation of the optimal low rank approximation of a matrix product. Empirically our algorithm outperforms competing methods for AMM, for a small sketch size. We validate empirically our theoretical findings and algorithms
Deep Multimodal Learning for Audio-Visual Speech Recognition
Jan 22, 2015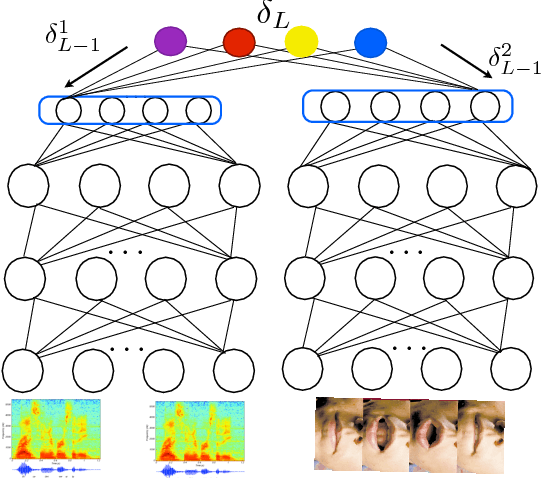


In this paper, we present methods in deep multimodal learning for fusing speech and visual modalities for Audio-Visual Automatic Speech Recognition (AV-ASR). First, we study an approach where uni-modal deep networks are trained separately and their final hidden layers fused to obtain a joint feature space in which another deep network is built. While the audio network alone achieves a phone error rate (PER) of $41\%$ under clean condition on the IBM large vocabulary audio-visual studio dataset, this fusion model achieves a PER of $35.83\%$ demonstrating the tremendous value of the visual channel in phone classification even in audio with high signal to noise ratio. Second, we present a new deep network architecture that uses a bilinear softmax layer to account for class specific correlations between modalities. We show that combining the posteriors from the bilinear networks with those from the fused model mentioned above results in a further significant phone error rate reduction, yielding a final PER of $34.03\%$.