 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymmetrically Weighted CCA And Hierarchical Kernel Sentence Embedding For Image & Text Retrieval
Paper and Code

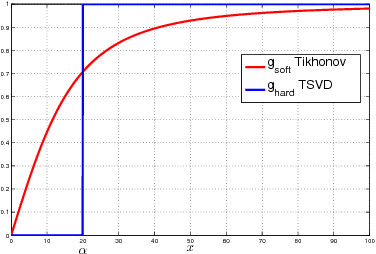
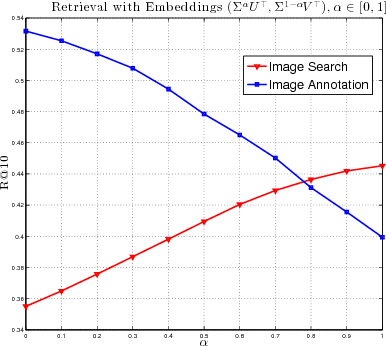
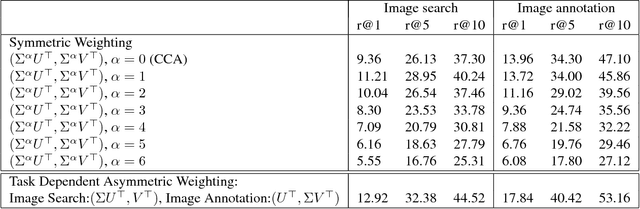
Joint modeling of language and vision has been drawing increasing interest. A multimodal data representation allowing for bidirectional retrieval of images by sentences and vice versa is a key aspect. In this paper we present three contributions in canonical correlation analysis (CCA) based multimodal retrieval. Firstly, we show that an asymmetric weighting of the canonical weights, while achieving a cross view mapping from the search to the query space, improves the retrieval performance. Secondly, we devise a computationally efficient model selection, crucial to generalization and stability, in the framework of the Bj\"ork Golub algorithm for regularized CCA via spectral filtering. Finally, we introduce a Hierarchical Kernel Sentence Embedding (HKSE) that approximates Kernel CCA for a special similarity kernel between distribution of words embedded in a vector space. State of the art results are obtained on MSCOCO and Flickr benchmarks when these three techniques are used in conjunction.