 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-critical Sequence Training for Image Captioning
Nov 16, 2017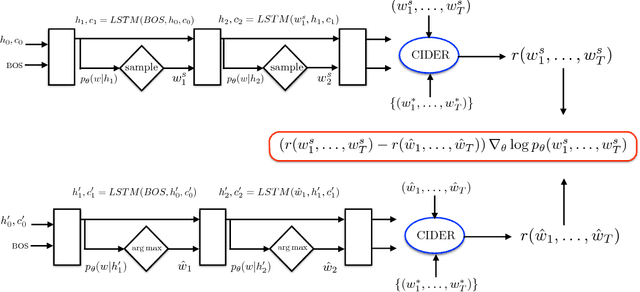
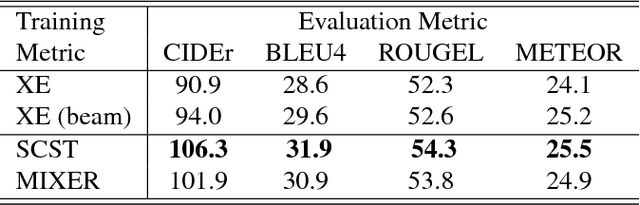
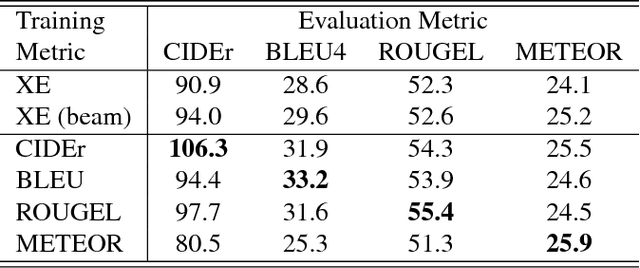

Recently it has been shown that policy-gradient methods for reinforcement learning can be utilized to train deep end-to-end systems directly on non-differentiable metrics for the task at hand. In this paper we consider the problem of optimizing image captioning systems using reinforcement learning, and show that by carefully optimizing our systems using the test metrics of the MSCOCO task, significant gains in performance can be realized. Our systems are built using a new optimization approach that we call self-critical sequence training (SCST). SCST is a form of the popular REINFORCE algorithm that, rather than estimating a "baseline" to normalize the rewards and reduce variance, utilizes the output of its own test-time inference algorithm to normalize the rewards it experiences. Using this approach, estimating the reward signal (as actor-critic methods must do) and estimating normalization (as REINFORCE algorithms typically do) is avoided, while at the same time harmonizing the model with respect to its test-time inference procedure. Empirically we find that directly optimizing the CIDEr metric with SCST and greedy decoding at test-time is highly effective. Our results on the MSCOCO evaluation sever establish a new state-of-the-art on the task, improving the best result in terms of CIDEr from 104.9 to 114.7.
Embedding-Based Speaker Adaptive Training of Deep Neural Networks
Oct 17, 2017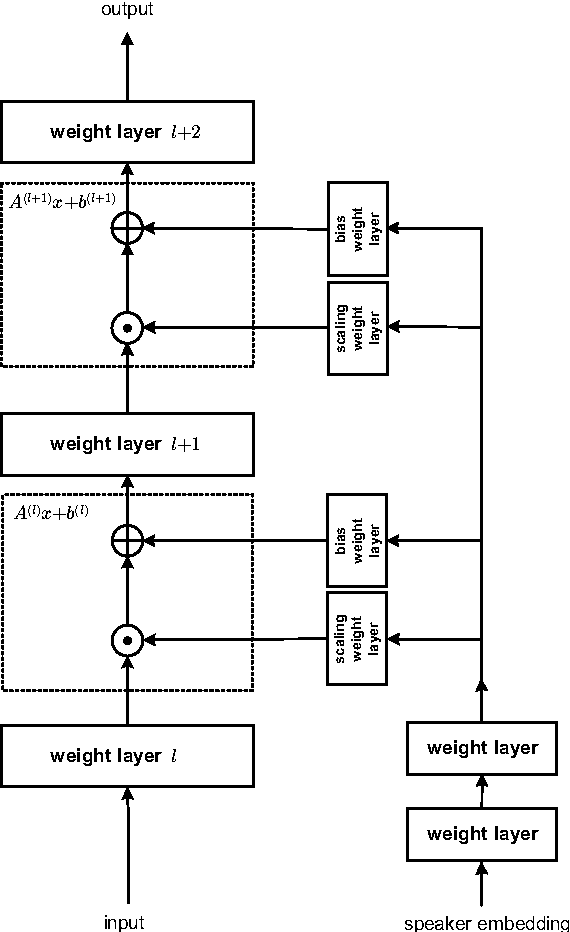

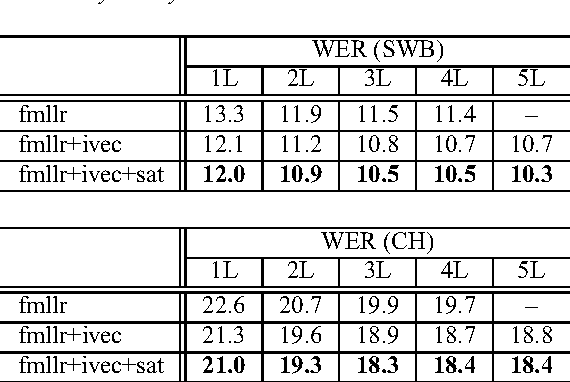
An embedding-based speaker adaptive training (SAT) approach is proposed and investigated in this paper for deep neural network acoustic modeling. In this approach, speaker embedding vectors, which are a constant given a particular speaker, are mapped through a control network to layer-dependent element-wise affine transformations to canonicalize the internal feature representations at the output of hidden layers of a main network. The control network for generating the speaker-dependent mappings is jointly estimated with the main network for the overall speaker adaptive acoustic modeling. Experiments on large vocabulary continuous speech recognition (LVCSR) tasks show that the proposed SAT scheme can yield superior performance over the widely-used speaker-aware training using i-vectors with speaker-adapted input features.
McGan: Mean and Covariance Feature Matching GAN
Jun 08, 2017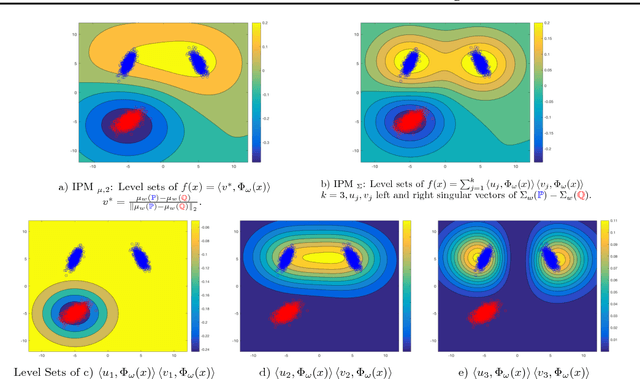
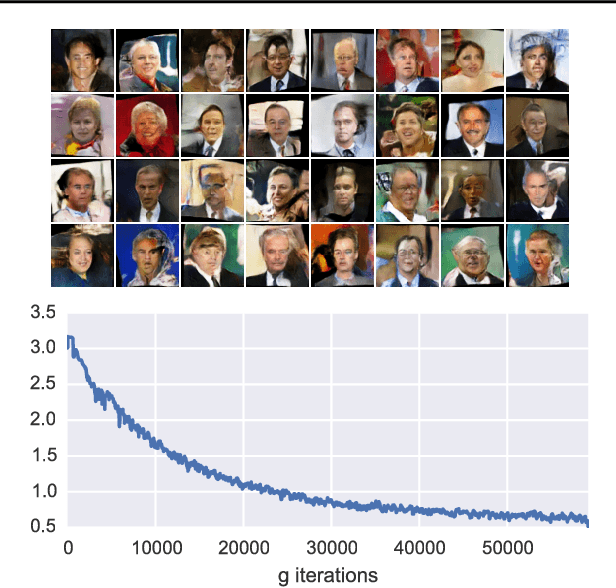
We introduce new families of Integral Probability Metrics (IPM) for training Generative Adversarial Networks (GAN). Our IPMs are based on matching statistics of distributions embedded in a finite dimensional feature space. Mean and covariance feature matching IPMs allow for stable training of GANs, which we will call McGan. McGan minimizes a meaningful loss between distributions.
Dense Prediction on Sequences with Time-Dilated Convolutions for Speech Recognition
Dec 14, 2016

In computer vision pixelwise dense prediction is the task of predicting a label for each pixel in the image. Convolutional neural networks achieve good performance on this task, while being computationally efficient. In this paper we carry these ideas over to the problem of assigning a sequence of labels to a set of speech frames, a task commonly known as framewise classification. We show that dense prediction view of framewise classification offers several advantages and insights, including computational efficiency and the ability to apply batch normalization. When doing dense prediction we pay specific attention to strided pooling in time and introduce an asymmetric dilated convolution, called time-dilated convolution, that allows for efficient and elegant implementation of pooling in time. We show results using time-dilated convolutions in a very deep VGG-style CNN with batch normalization on the Hub5 Switchboard-2000 benchmark task. With a big n-gram language model, we achieve 7.7% WER which is the best single model single-pass performance reported so far.
Asymmetrically Weighted CCA And Hierarchical Kernel Sentence Embedding For Image & Text Retrieval
Dec 05, 2016
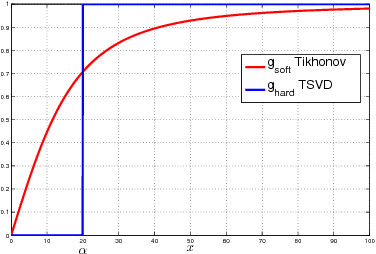
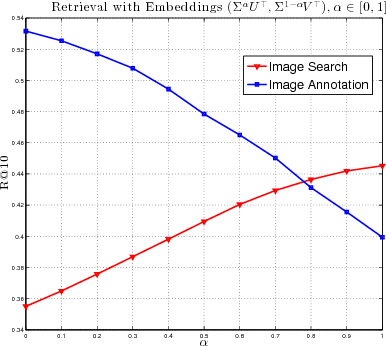
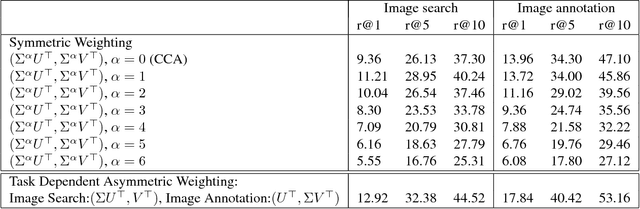
Joint modeling of language and vision has been drawing increasing interest. A multimodal data representation allowing for bidirectional retrieval of images by sentences and vice versa is a key aspect. In this paper we present three contributions in canonical correlation analysis (CCA) based multimodal retrieval. Firstly, we show that an asymmetric weighting of the canonical weights, while achieving a cross view mapping from the search to the query space, improves the retrieval performance. Secondly, we devise a computationally efficient model selection, crucial to generalization and stability, in the framework of the Bj\"ork Golub algorithm for regularized CCA via spectral filtering. Finally, we introduce a Hierarchical Kernel Sentence Embedding (HKSE) that approximates Kernel CCA for a special similarity kernel between distribution of words embedded in a vector space. State of the art results are obtained on MSCOCO and Flickr benchmarks when these three techniques are used in conjunction.
Co-Occuring Directions Sketching for Approximate Matrix Multiply
Oct 25, 2016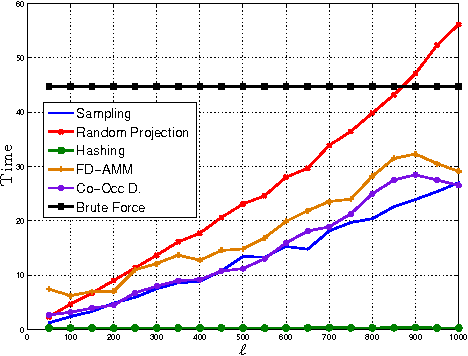
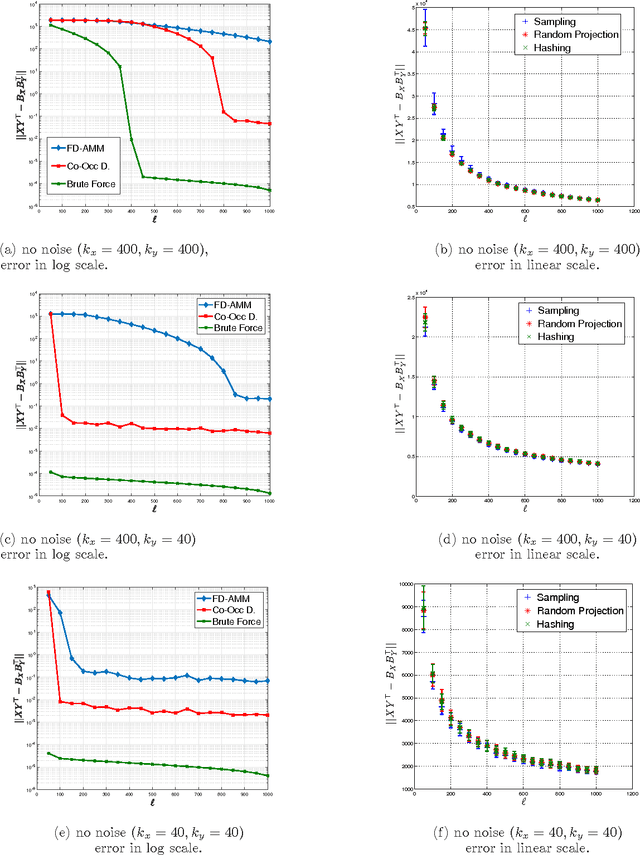
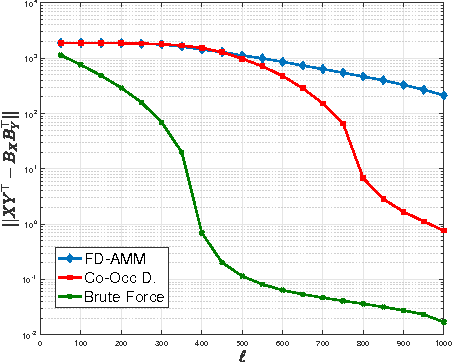
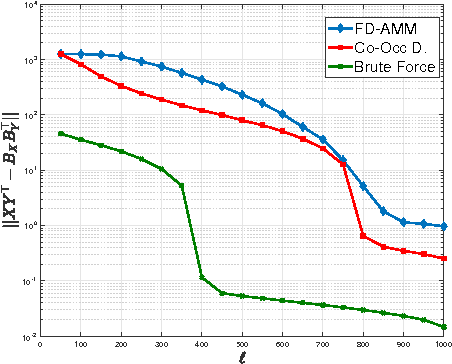
We introduce co-occurring directions sketching, a deterministic algorithm for approximate matrix product (AMM), in the streaming model. We show that co-occuring directions achieves a better error bound for AMM than other randomized and deterministic approaches for AMM. Co-occurring directions gives a $1 + \epsilon$ -approximation of the optimal low rank approximation of a matrix product. Empirically our algorithm outperforms competing methods for AMM, for a small sketch size. We validate empirically our theoretical findings and algorithms
Advances in Very Deep Convolutional Neural Networks for LVCSR
Jun 25, 2016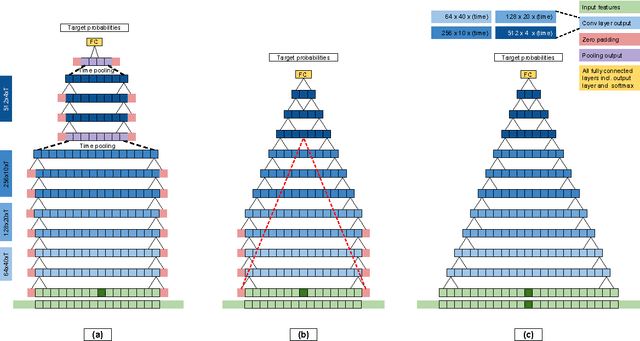
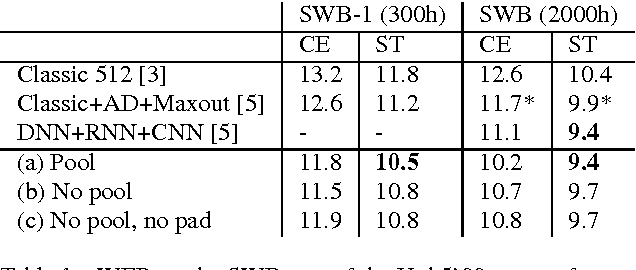

Very deep CNNs with small 3x3 kernels have recently been shown to achieve very strong performance as acoustic models in hybrid NN-HMM speech recognition systems. In this paper we investigate how to efficiently scale these models to larger datasets. Specifically, we address the design choice of pooling and padding along the time dimension which renders convolutional evaluation of sequences highly inefficient. We propose a new CNN design without timepadding and without timepooling, which is slightly suboptimal for accuracy, but has two significant advantages: it enables sequence training and deployment by allowing efficient convolutional evaluation of full utterances, and, it allows for batch normalization to be straightforwardly adopted to CNNs on sequence data. Through batch normalization, we recover the lost peformance from removing the time-pooling, while keeping the benefit of efficient convolutional evaluation. We demonstrate the performance of our models both on larger scale data than before, and after sequence training. Our very deep CNN model sequence trained on the 2000h switchboard dataset obtains 9.4 word error rate on the Hub5 test-set, matching with a single model the performance of the 2015 IBM system combination, which was the previous best published result.
Random Maxout Features
Jun 12, 2015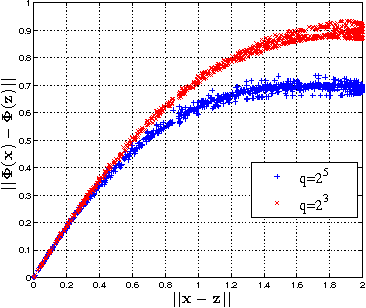

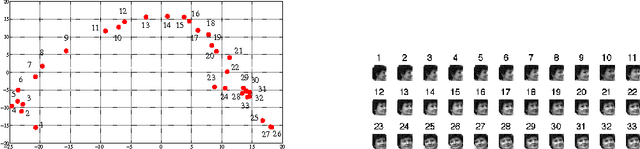
In this paper, we propose and study random maxout features, which are constructed by first projecting the input data onto sets of randomly generated vectors with Gaussian elements, and then outputing the maximum projection value for each set. We show that the resulting random feature map, when used in conjunction with linear models, allows for the locally linear estimation of the function of interest in classification tasks, and for the locally linear embedding of points when used for dimensionality reduction or data visualization. We derive generalization bounds for learning that assess the error in approximating locally linear functions by linear functions in the maxout feature space, and empirically evaluate the efficacy of the approach on the MNIST and TIMIT classification tasks.
Deep Multimodal Learning for Audio-Visual Speech Recognition
Jan 22, 2015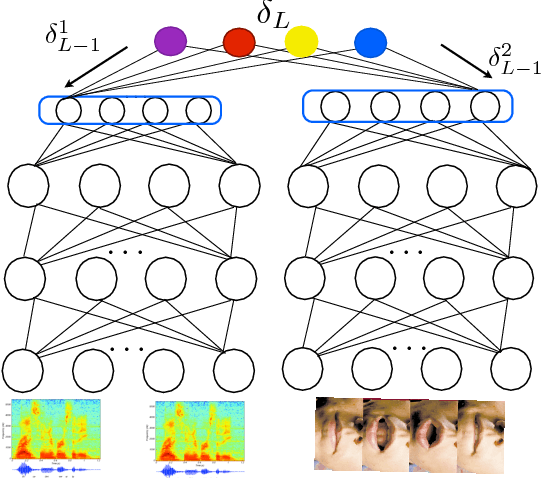


In this paper, we present methods in deep multimodal learning for fusing speech and visual modalities for Audio-Visual Automatic Speech Recognition (AV-ASR). First, we study an approach where uni-modal deep networks are trained separately and their final hidden layers fused to obtain a joint feature space in which another deep network is built. While the audio network alone achieves a phone error rate (PER) of $41\%$ under clean condition on the IBM large vocabulary audio-visual studio dataset, this fusion model achieves a PER of $35.83\%$ demonstrating the tremendous value of the visual channel in phone classification even in audio with high signal to noise ratio. Second, we present a new deep network architecture that uses a bilinear softmax layer to account for class specific correlations between modalities. We show that combining the posteriors from the bilinear networks with those from the fused model mentioned above results in a further significant phone error rate reduction, yielding a final PER of $34.03\%$.