 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Fashion IQ Dataset: Retrieving Images by Combining Side Information and Relative Natural Language Feedback
May 30, 2019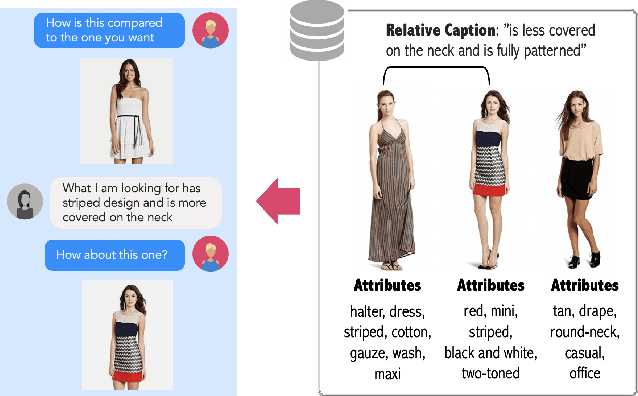
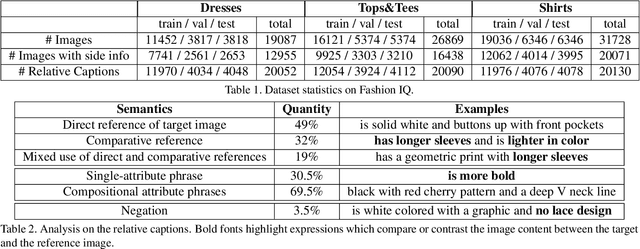
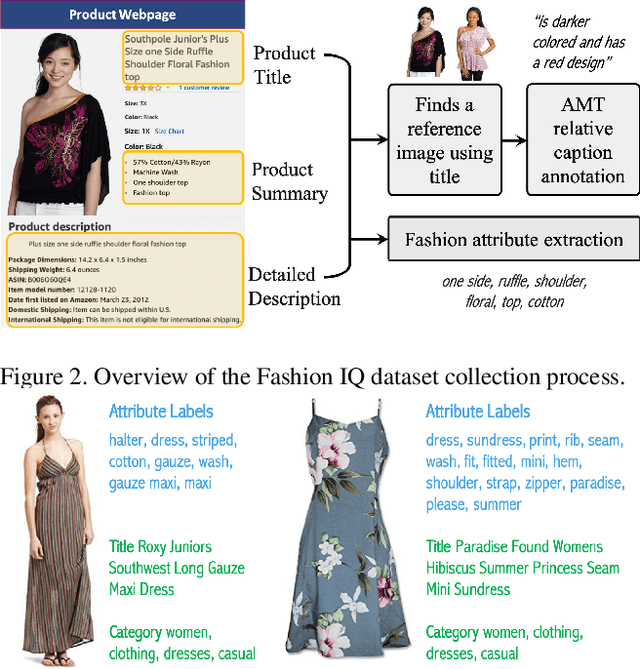
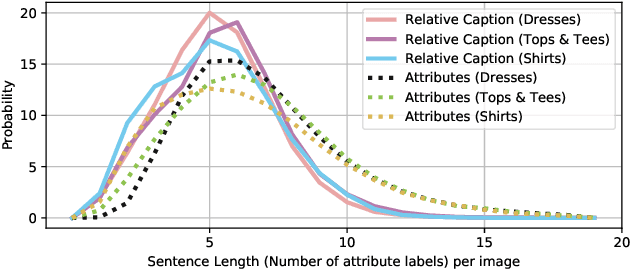
We contribute a new dataset and a novel method for natural language based fashion image retrieval. Unlike previous fashion datasets, we provide natural language annotations to facilitate the training of interactive image retrieval systems, as well as the commonly used attribute based labels. We propose a novel approach and empirically demonstrate that combining natural language feedback with visual attribute information results in superior user feedback modeling and retrieval performance relative to using either of these modalities. We believe that our dataset can encourage further work on developing more natural and real-world applicable conversational shopping assistants.
Dialog-based Interactive Image Retrieval
Nov 01, 2018

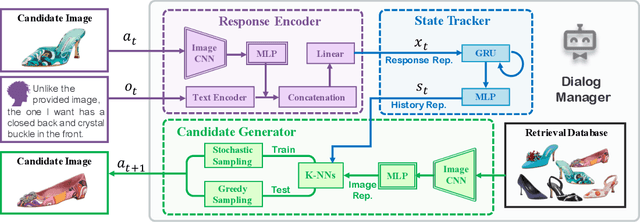
Existing methods for interactive image retrieval have demonstrated the merit of integrating user feedback, improving retrieval results. However, most current systems rely on restricted forms of user feedback, such as binary relevance responses, or feedback based on a fixed set of relative attributes, which limits their impact. In this paper, we introduce a new approach to interactive image search that enables users to provide feedback via natural language, allowing for more natural and effective interaction. We formulate the task of dialog-based interactive image retrieval as a reinforcement learning problem, and reward the dialog system for improving the rank of the target image during each dialog turn. To mitigate the cumbersome and costly process of collecting human-machine conversations as the dialog system learns, we train our system with a user simulator, which is itself trained to describe the differences between target and candidate images. The efficacy of our approach is demonstrated in a footwear retrieval application. Experiments on both simulated and real-world data show that 1) our proposed learning framework achieves better accuracy than other supervised and reinforcement learning baselines and 2) user feedback based on natural language rather than pre-specified attributes leads to more effective retrieval results, and a more natural and expressive communication interface.
BlockDrop: Dynamic Inference Paths in Residual Networks
Apr 12, 2018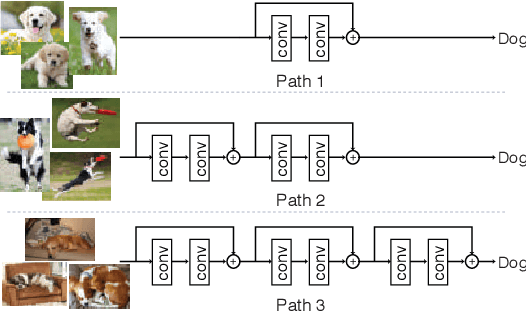
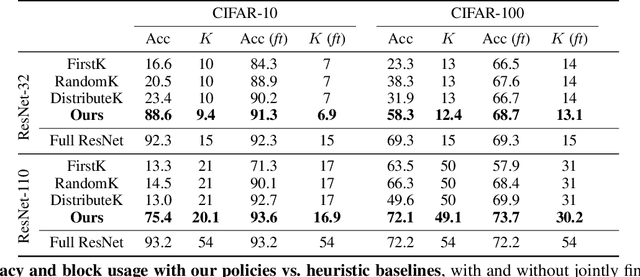
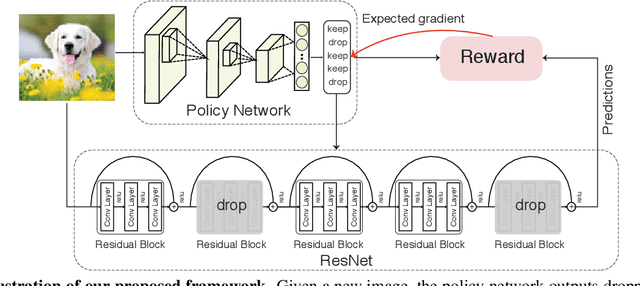
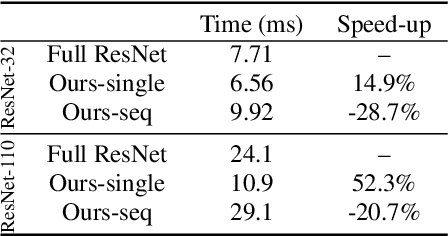
Very deep convolutional neural networks offer excellent recognition results, yet their computational expense limits their impact for many real-world applications. We introduce BlockDrop, an approach that learns to dynamically choose which layers of a deep network to execute during inference so as to best reduce total computation without degrading prediction accuracy. Exploiting the robustness of Residual Networks (ResNets) to layer dropping, our framework selects on-the-fly which residual blocks to evaluate for a given novel image. In particular, given a pretrained ResNet, we train a policy network in an associative reinforcement learning setting for the dual reward of utilizing a minimal number of blocks while preserving recognition accuracy. We conduct extensive experiments on CIFAR and ImageNet. The results provide strong quantitative and qualitative evidence that these learned policies not only accelerate inference but also encode meaningful visual information. Built upon a ResNet-101 model, our method achieves a speedup of 20\% on average, going as high as 36\% for some images, while maintaining the same 76.4\% top-1 accuracy on ImageNet.
The IBM 2016 English Conversational Telephone Speech Recognition System
Jun 22, 2016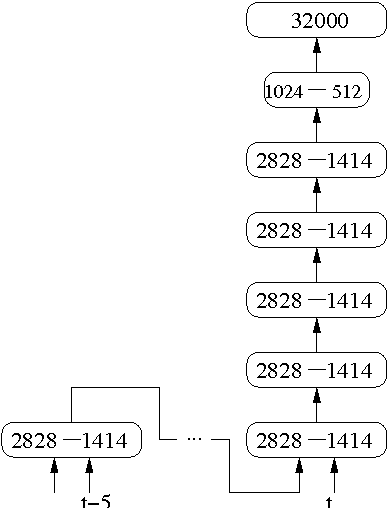
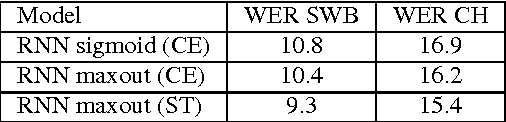
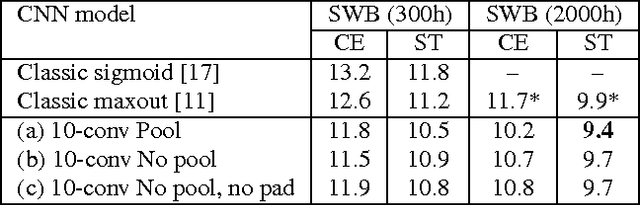
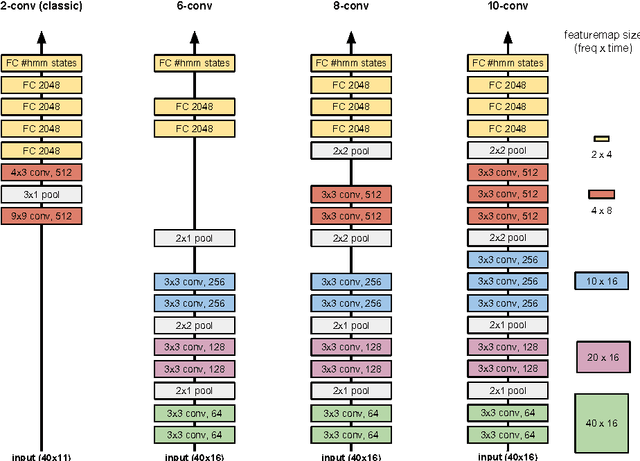
We describe a collection of acoustic and language modeling techniques that lowered the word error rate of our English conversational telephone LVCSR system to a record 6.6% on the Switchboard subset of the Hub5 2000 evaluation testset. On the acoustic side, we use a score fusion of three strong models: recurrent nets with maxout activations, very deep convolutional nets with 3x3 kernels, and bidirectional long short-term memory nets which operate on FMLLR and i-vector features. On the language modeling side, we use an updated model "M" and hierarchical neural network LMs.
Random Maxout Features
Jun 12, 2015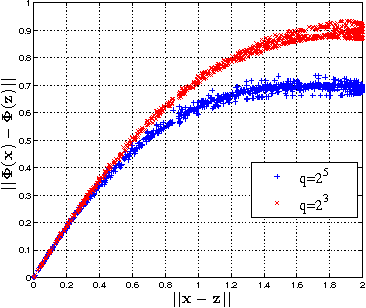

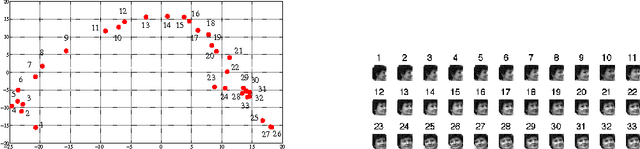
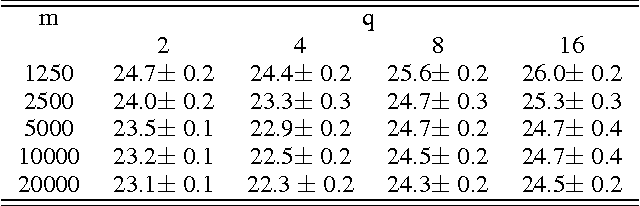
In this paper, we propose and study random maxout features, which are constructed by first projecting the input data onto sets of randomly generated vectors with Gaussian elements, and then outputing the maximum projection value for each set. We show that the resulting random feature map, when used in conjunction with linear models, allows for the locally linear estimation of the function of interest in classification tasks, and for the locally linear embedding of points when used for dimensionality reduction or data visualization. We derive generalization bounds for learning that assess the error in approximating locally linear functions by linear functions in the maxout feature space, and empirically evaluate the efficacy of the approach on the MNIST and TIMIT classification tasks.
The IBM 2015 English Conversational Telephone Speech Recognition System
May 21, 2015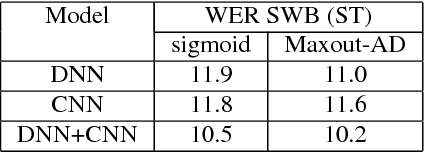
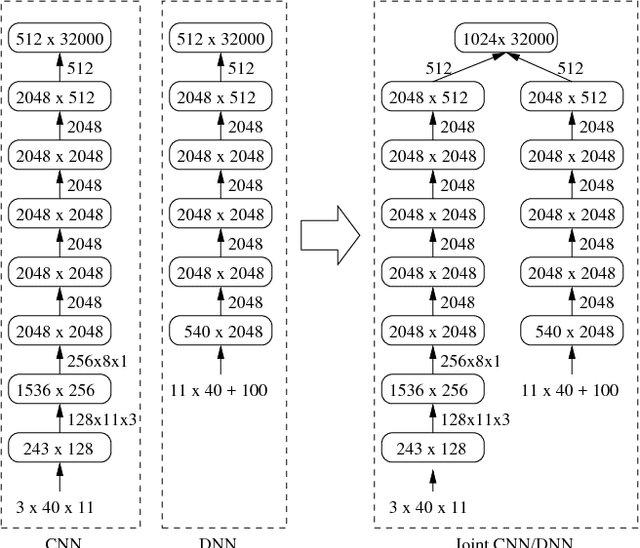

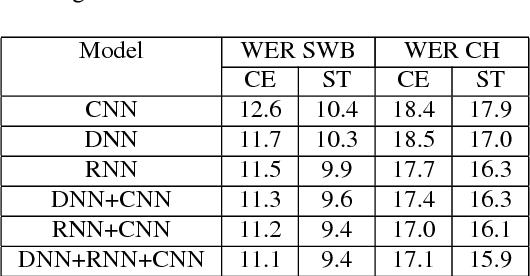
We describe the latest improvements to the IBM English conversational telephone speech recognition system. Some of the techniques that were found beneficial are: maxout networks with annealed dropout rates; networks with a very large number of outputs trained on 2000 hours of data; joint modeling of partially unfolded recurrent neural networks and convolutional nets by combining the bottleneck and output layers and retraining the resulting model; and lastly, sophisticated language model rescoring with exponential and neural network LMs. These techniques result in an 8.0% word error rate on the Switchboard part of the Hub5-2000 evaluation test set which is 23% relative better than our previous best published result.