Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe IBM 2015 English Conversational Telephone Speech Recognition System
Paper and Code
May 21, 2015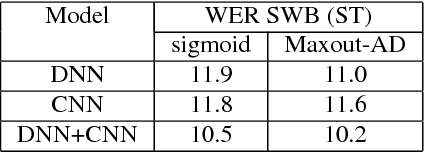
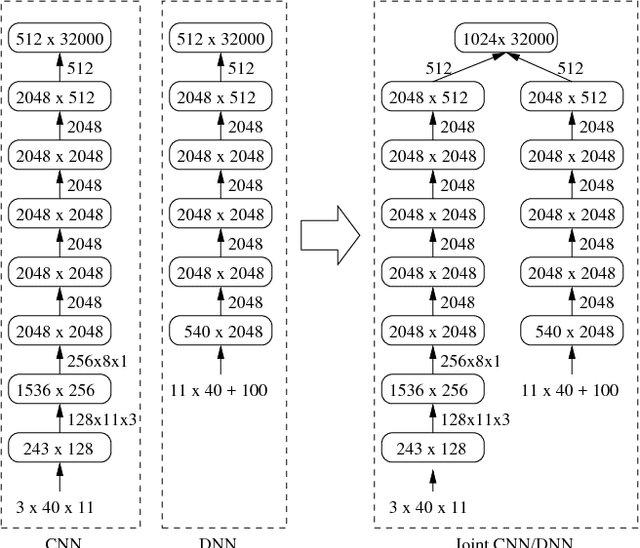

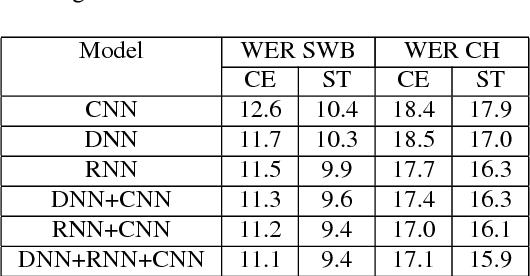
We describe the latest improvements to the IBM English conversational telephone speech recognition system. Some of the techniques that were found beneficial are: maxout networks with annealed dropout rates; networks with a very large number of outputs trained on 2000 hours of data; joint modeling of partially unfolded recurrent neural networks and convolutional nets by combining the bottleneck and output layers and retraining the resulting model; and lastly, sophisticated language model rescoring with exponential and neural network LMs. These techniques result in an 8.0% word error rate on the Switchboard part of the Hub5-2000 evaluation test set which is 23% relative better than our previous best published result.
* Submitted to Interspeech 2015
View paper on