 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Image Captioning with Adversarial Semantic Alignment
Paper and Code
Jun 01, 2018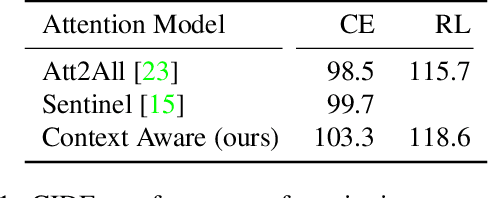
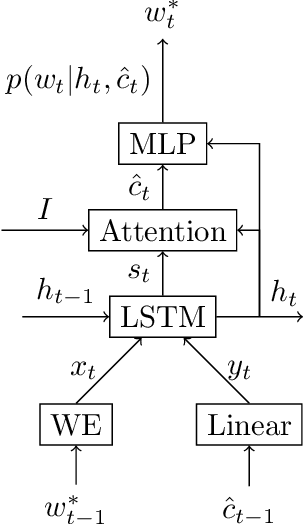
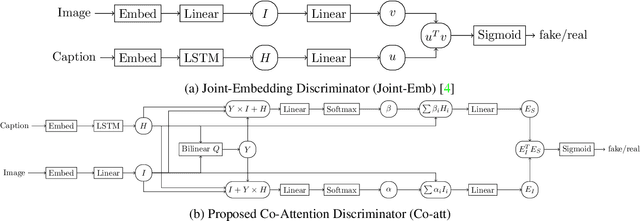
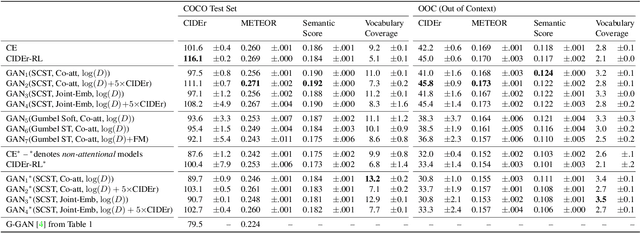
We study image captioning as a conditional GAN training, proposing both a context-aware LSTM captioner and co-attentive discriminator, which enforces semantic alignment between images and captions. We empirically study the viability of two training methods: Self-critical Sequence Training (SCST) and Gumbel Straight-Through (ST). We show that, surprisingly, SCST (a policy gradient method) shows more stable gradient behavior and improved results over Gumbel ST, even without accessing the discriminator gradients directly. We also address the open question of automatic evaluation for these models and introduce a new semantic score and demonstrate its strong correlation to human judgement. As an evaluation paradigm, we suggest that an important criterion is the ability of a captioner to generalize to compositions between objects that do not usually occur together, for which we introduce a captioned Out of Context (OOC) test set. The OOC dataset combined with our semantic score is a new benchmark for the captioning community. Under this OOC benchmark, and the traditional MSCOCO dataset, we show that SCST has a strong performance in both semantic score and human evaluation.