 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditing and Generating Synthetic Data with Controllable Trust Trade-offs
May 02, 2023



Data collected from the real world tends to be biased, unbalanced, and at risk of exposing sensitive and private information. This reality has given rise to the idea of creating synthetic datasets to alleviate risk, bias, harm, and privacy concerns inherent in the real data. This concept relies on Generative AI models to produce unbiased, privacy-preserving synthetic data while being true to the real data. In this new paradigm, how can we tell if this approach delivers on its promises? We present an auditing framework that offers a holistic assessment of synthetic datasets and AI models trained on them, centered around bias and discrimination prevention, fidelity to the real data, utility, robustness, and privacy preservation. We showcase our framework by auditing multiple generative models on diverse use cases, including education, healthcare, banking, human resources, and across different modalities, from tabular, to time-series, to natural language. Our use cases demonstrate the importance of a holistic assessment in order to ensure compliance with socio-technical safeguards that regulators and policymakers are increasingly enforcing. For this purpose, we introduce the trust index that ranks multiple synthetic datasets based on their prescribed safeguards and their desired trade-offs. Moreover, we devise a trust-index-driven model selection and cross-validation procedure via auditing in the training loop that we showcase on a class of transformer models that we dub TrustFormers, across different modalities. This trust-driven model selection allows for controllable trust trade-offs in the resulting synthetic data. We instrument our auditing framework with workflows that connect different stakeholders from model development to audit and certification via a synthetic data auditing report.
Cloud-Based Real-Time Molecular Screening Platform with MolFormer
Aug 13, 2022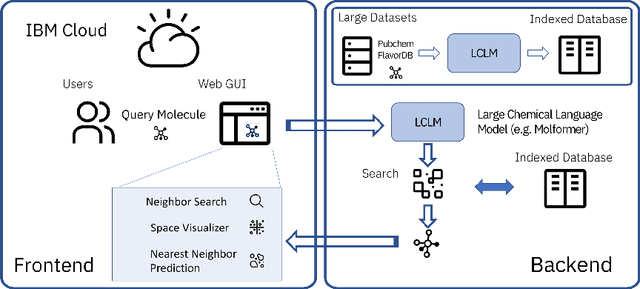
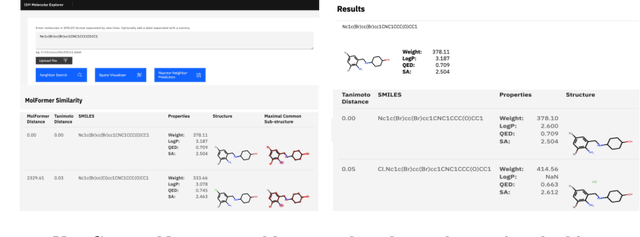

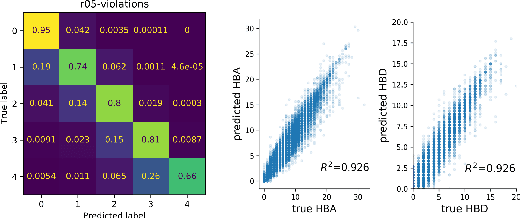
With the prospect of automating a number of chemical tasks with high fidelity, chemical language processing models are emerging at a rapid speed. Here, we present a cloud-based real-time platform that allows users to virtually screen molecules of interest. For this purpose, molecular embeddings inferred from a recently proposed large chemical language model, named MolFormer, are leveraged. The platform currently supports three tasks: nearest neighbor retrieval, chemical space visualization, and property prediction. Based on the functionalities of this platform and results obtained, we believe that such a platform can play a pivotal role in automating chemistry and chemical engineering research, as well as assist in drug discovery and material design tasks. A demo of our platform is provided at \url{www.ibm.biz/molecular_demo}.
Image Captioning as an Assistive Technology: Lessons Learned from VizWiz 2020 Challenge
Dec 21, 2020
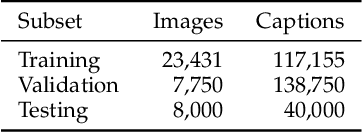
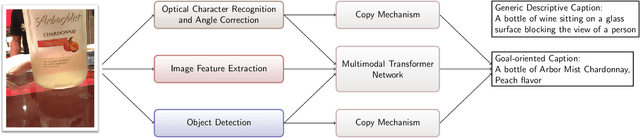
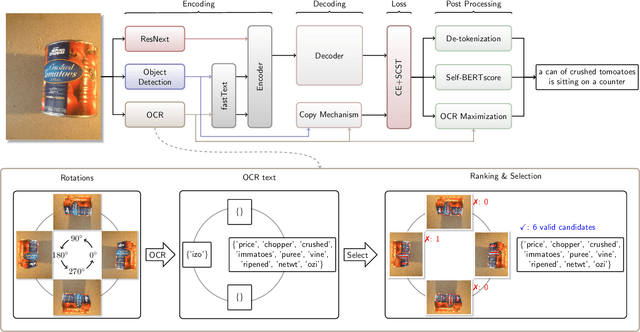
Image captioning has recently demonstrated impressive progress largely owing to the introduction of neural network algorithms trained on curated dataset like MS-COCO. Often work in this field is motivated by the promise of deployment of captioning systems in practical applications. However, the scarcity of data and contexts in many competition datasets renders the utility of systems trained on these datasets limited as an assistive technology in real-world settings, such as helping visually impaired people navigate and accomplish everyday tasks. This gap motivated the introduction of the novel VizWiz dataset, which consists of images taken by the visually impaired and captions that have useful, task-oriented information. In an attempt to help the machine learning computer vision field realize its promise of producing technologies that have positive social impact, the curators of the VizWiz dataset host several competitions, including one for image captioning. This work details the theory and engineering from our winning submission to the 2020 captioning competition. Our work provides a step towards improved assistive image captioning systems.