 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Significant Fault Detection in Azure Core Workload Insights
Apr 14, 2024



Azure Core workload insights have time-series data with different metric units. Faults or Anomalies are observed in these time-series data owing to faults observed with respect to metric name, resources region, dimensions, and its dimension value associated with the data. For Azure Core, an important task is to highlight faults or anomalies to the user on a dashboard that they can perceive easily. The number of anomalies reported should be highly significant and in a limited number, e.g., 5-20 anomalies reported per hour. The reported anomalies will have significant user perception and high reconstruction error in any time-series forecasting model. Hence, our task is to automatically identify 'high significant anomalies' and their associated information for user perception.
Counterfactual Multi-Token Fairness in Text Classification
Feb 09, 2022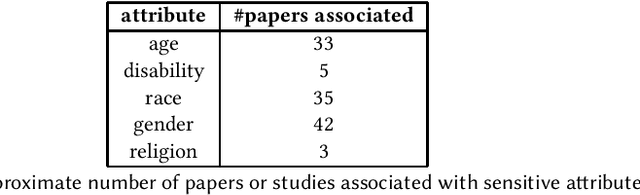
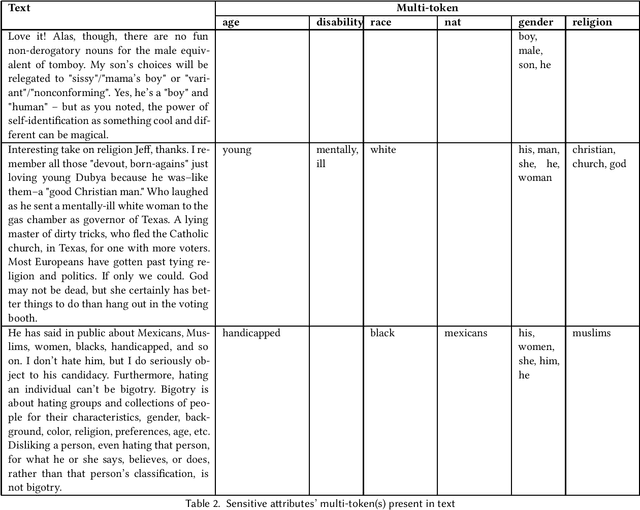


The counterfactual token generation has been limited to perturbing only a single token in texts that are generally short and single sentences. These tokens are often associated with one of many sensitive attributes. With limited counterfactuals generated, the goal to achieve invariant nature for machine learning classification models towards any sensitive attribute gets bounded, and the formulation of Counterfactual Fairness gets narrowed. In this paper, we overcome these limitations by solving root problems and opening bigger domains for understanding. We have curated a resource of sensitive tokens and their corresponding perturbation tokens, even extending the support beyond traditionally used sensitive attributes like Age, Gender, Race to Nationality, Disability, and Religion. The concept of Counterfactual Generation has been extended to multi-token support valid over all forms of texts and documents. We define the method of generating counterfactuals by perturbing multiple sensitive tokens as Counterfactual Multi-token Generation. The method has been conceptualized to showcase significant performance improvement over single-token methods and validated over multiple benchmark datasets. The emendation in counterfactual generation propagates in achieving improved Counterfactual Multi-token Fairness.
Data Quality Toolkit: Automatic assessment of data quality and remediation for machine learning datasets
Sep 05, 2021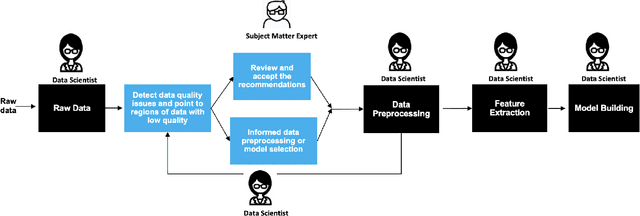

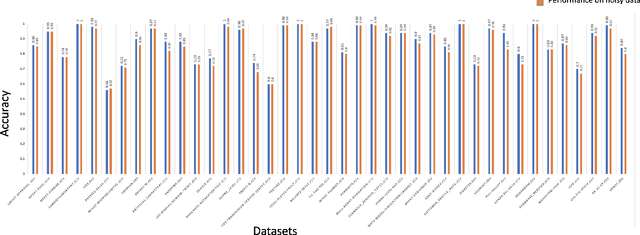
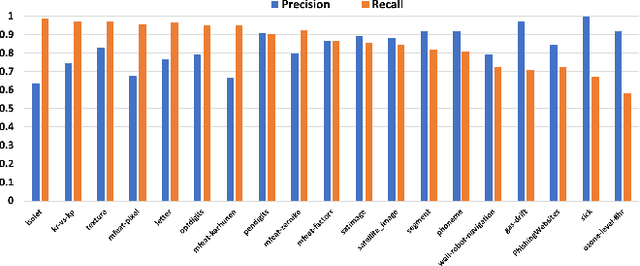
The quality of training data has a huge impact on the efficiency, accuracy and complexity of machine learning tasks. Various tools and techniques are available that assess data quality with respect to general cleaning and profiling checks. However these techniques are not applicable to detect data issues in the context of machine learning tasks, like noisy labels, existence of overlapping classes etc. We attempt to re-look at the data quality issues in the context of building a machine learning pipeline and build a tool that can detect, explain and remediate issues in the data, and systematically and automatically capture all the changes applied to the data. We introduce the Data Quality Toolkit for machine learning as a library of some key quality metrics and relevant remediation techniques to analyze and enhance the readiness of structured training datasets for machine learning projects. The toolkit can reduce the turn-around times of data preparation pipelines and streamline the data quality assessment process. Our toolkit is publicly available via IBM API Hub [1] platform, any developer can assess the data quality using the IBM's Data Quality for AI apis [2]. Detailed tutorials are also available on IBM Learning Path [3].
Priority-based Post-Processing Bias Mitigation for Individual and Group Fairness
Jan 31, 2021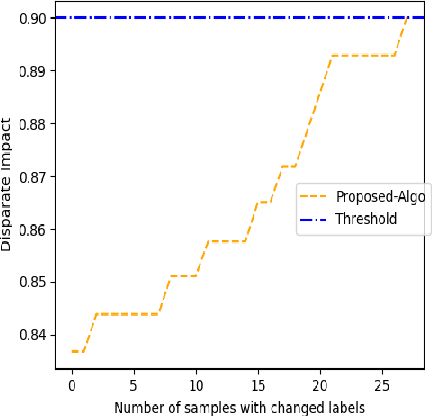
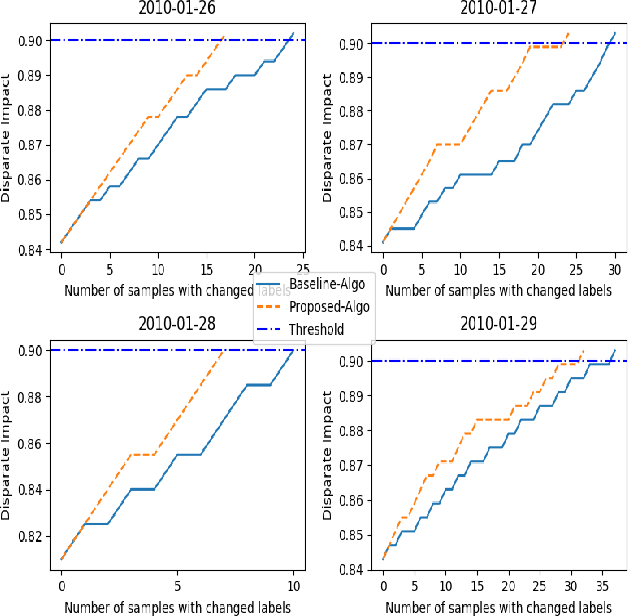
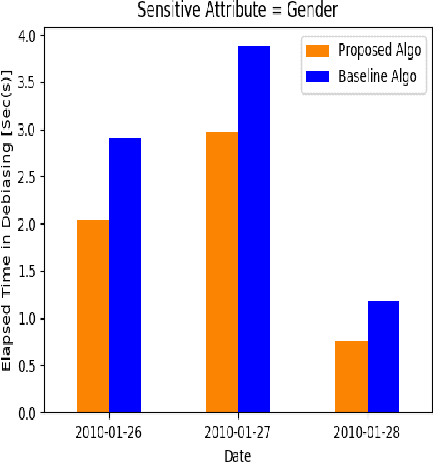
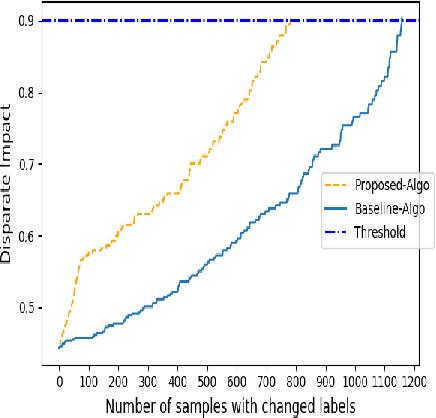
Previous post-processing bias mitigation algorithms on both group and individual fairness don't work on regression models and datasets with multi-class numerical labels. We propose a priority-based post-processing bias mitigation on both group and individual fairness with the notion that similar individuals should get similar outcomes irrespective of socio-economic factors and more the unfairness, more the injustice. We establish this proposition by a case study on tariff allotment in a smart grid. Our novel framework establishes it by using a user segmentation algorithm to capture the consumption strategy better. This process ensures priority-based fair pricing for group and individual facing the maximum injustice. It upholds the notion of fair tariff allotment to the entire population taken into consideration without modifying the in-built process for tariff calculation. We also validate our method and show superior performance to previous work on a real-world dataset in criminal sentencing.
AI Fairness 360: An Extensible Toolkit for Detecting, Understanding, and Mitigating Unwanted Algorithmic Bias
Oct 03, 2018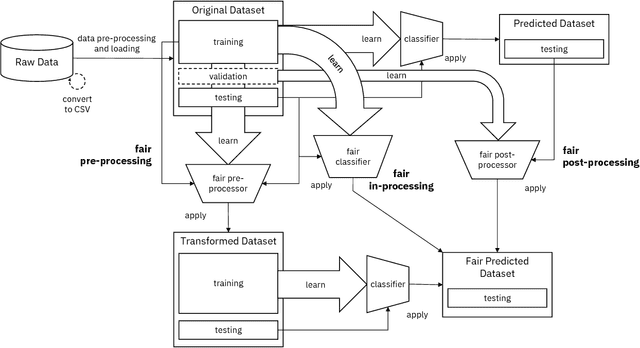
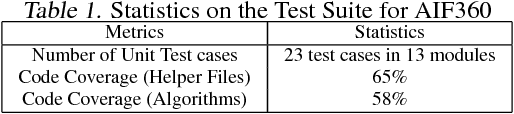
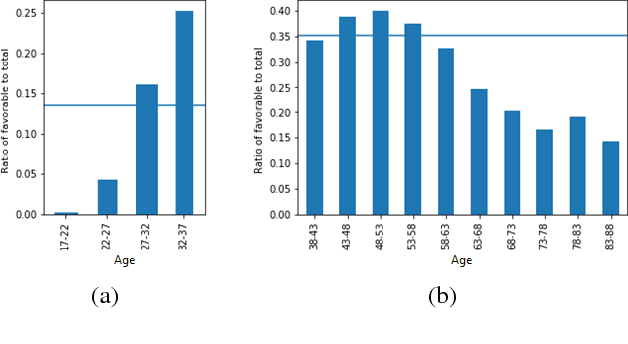
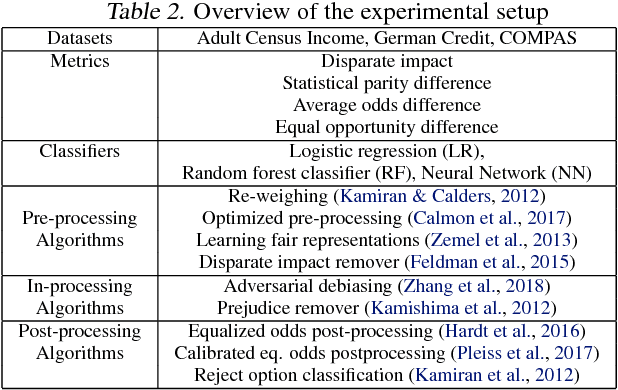
Fairness is an increasingly important concern as machine learning models are used to support decision making in high-stakes applications such as mortgage lending, hiring, and prison sentencing. This paper introduces a new open source Python toolkit for algorithmic fairness, AI Fairness 360 (AIF360), released under an Apache v2.0 license {https://github.com/ibm/aif360). The main objectives of this toolkit are to help facilitate the transition of fairness research algorithms to use in an industrial setting and to provide a common framework for fairness researchers to share and evaluate algorithms. The package includes a comprehensive set of fairness metrics for datasets and models, explanations for these metrics, and algorithms to mitigate bias in datasets and models. It also includes an interactive Web experience (https://aif360.mybluemix.net) that provides a gentle introduction to the concepts and capabilities for line-of-business users, as well as extensive documentation, usage guidance, and industry-specific tutorials to enable data scientists and practitioners to incorporate the most appropriate tool for their problem into their work products. The architecture of the package has been engineered to conform to a standard paradigm used in data science, thereby further improving usability for practitioners. Such architectural design and abstractions enable researchers and developers to extend the toolkit with their new algorithms and improvements, and to use it for performance benchmarking. A built-in testing infrastructure maintains code quality.
Automated Test Generation to Detect Individual Discrimination in AI Models
Sep 10, 2018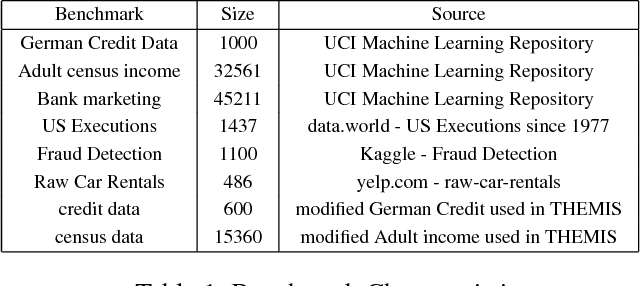

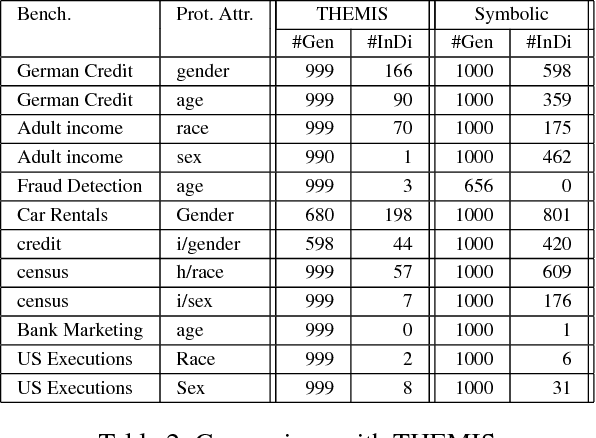
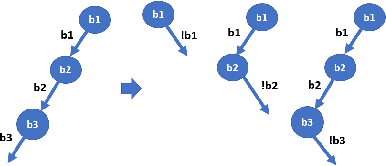
Dependability on AI models is of utmost importance to ensure full acceptance of the AI systems. One of the key aspects of the dependable AI system is to ensure that all its decisions are fair and not biased towards any individual. In this paper, we address the problem of detecting whether a model has an individual discrimination. Such a discrimination exists when two individuals who differ only in the values of their protected attributes (such as, gender/race) while the values of their non-protected ones are exactly the same, get different decisions. Measuring individual discrimination requires an exhaustive testing, which is infeasible for a non-trivial system. In this paper, we present an automated technique to generate test inputs, which is geared towards finding individual discrimination. Our technique combines the well-known technique called symbolic execution along with the local explainability for generation of effective test cases. Our experimental results clearly demonstrate that our technique produces 3.72 times more successful test cases than the existing state-of-the-art across all our chosen benchmarks.
Video Analysis of "YouTube Funnies" to Aid the Study of Human Gait and Falls - Preliminary Results and Proof of Concept
Oct 26, 2016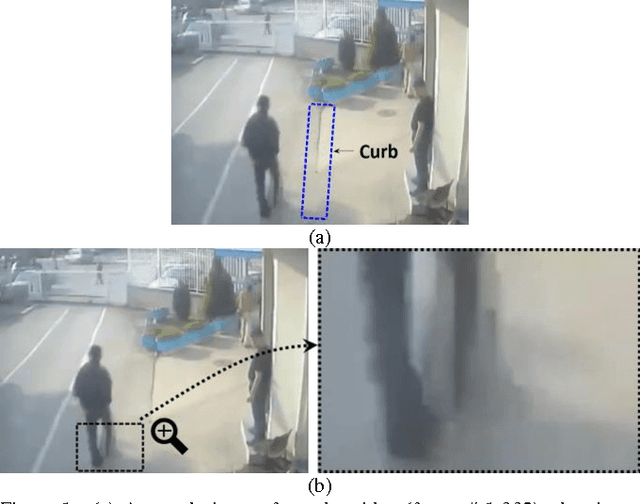


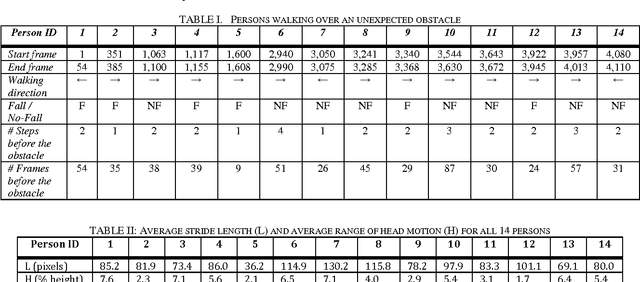
Because falls are funny, YouTube and other video sharing sites contain a large repository of real-life falls. We propose extracting gait and balance information from these videos to help us better understand some of the factors that contribute to falls. Proof-of-concept is explored in a single video containing multiple (n=14) falls/non-falls in the presence of an unexpected obstacle. The analysis explores: computing spatiotemporal parameters of gait in a video captured from an arbitrary viewpoint; the relationship between parameters of gait from the last few steps before the obstacle and falling vs. not falling; and the predictive capacity of a multivariate model in predicting a fall in the presence of an unexpected obstacle. Homography transformations correct the perspective projection distortion and allow for the consistent tracking of gait parameters as an individual walks in an arbitrary direction in the scene. A synthetic top view allows for computing the average stride length and a synthetic side view allows for measuring up and down motions of the head. In leave-one-out cross-validation, we were able to correctly predict whether a person would fall or not in 11 out of the 14 cases (78.6%), just by looking at the average stride length and the range of vertical head motion during the 1-4 most recent steps prior to reaching the obstacle.