 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Quality Toolkit: Automatic assessment of data quality and remediation for machine learning datasets
Sep 05, 2021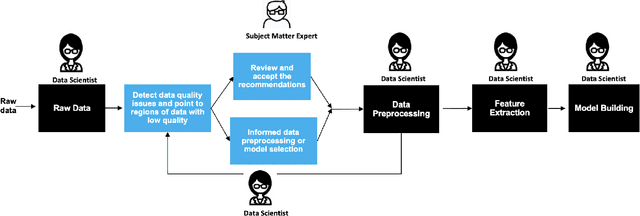

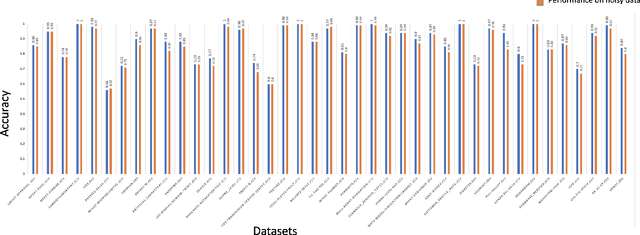
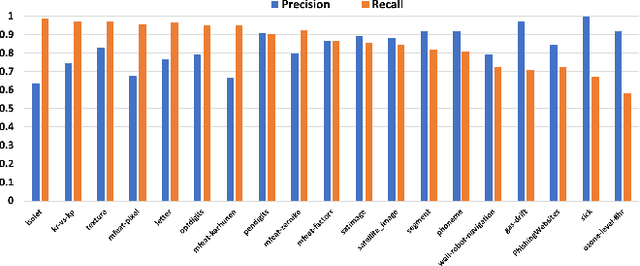
The quality of training data has a huge impact on the efficiency, accuracy and complexity of machine learning tasks. Various tools and techniques are available that assess data quality with respect to general cleaning and profiling checks. However these techniques are not applicable to detect data issues in the context of machine learning tasks, like noisy labels, existence of overlapping classes etc. We attempt to re-look at the data quality issues in the context of building a machine learning pipeline and build a tool that can detect, explain and remediate issues in the data, and systematically and automatically capture all the changes applied to the data. We introduce the Data Quality Toolkit for machine learning as a library of some key quality metrics and relevant remediation techniques to analyze and enhance the readiness of structured training datasets for machine learning projects. The toolkit can reduce the turn-around times of data preparation pipelines and streamline the data quality assessment process. Our toolkit is publicly available via IBM API Hub [1] platform, any developer can assess the data quality using the IBM's Data Quality for AI apis [2]. Detailed tutorials are also available on IBM Learning Path [3].
Generate Your Counterfactuals: Towards Controlled Counterfactual Generation for Text
Dec 08, 2020
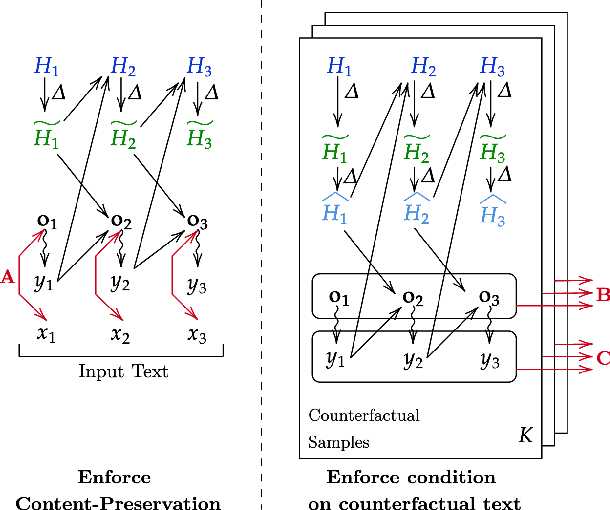

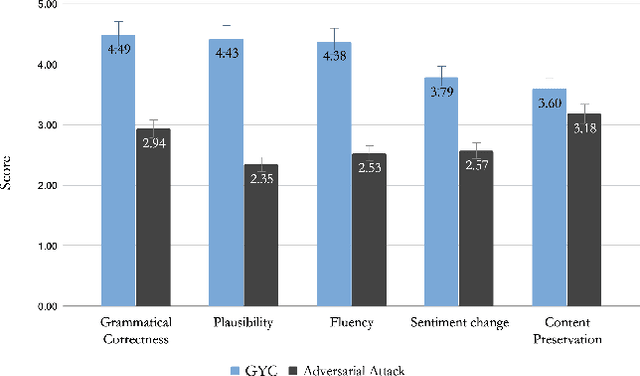
Machine Learning has seen tremendous growth recently, which has led to a larger adoption of ML systems for educational assessments, credit risk, healthcare, employment, criminal justice, to name a few. Trustworthiness of ML and NLP systems is a crucial aspect and requires guarantee that the decisions they make are fair and robust. Aligned with this, we propose a framework GYC, to generate a set of counterfactual text samples, which are crucial for testing these ML systems. Our main contributions include a) We introduce GYC, a framework to generate counterfactual samples such that the generation is plausible, diverse, goal-oriented, and effective, b) We generate counterfactual samples, that can direct the generation towards a corresponding condition such as named-entity tag, semantic role label, or sentiment. Our experimental results on various domains show that GYC generates counterfactual text samples exhibiting the above four properties. %The generated counterfactuals can then be fed complementary to the existing data augmentation for improving the debiasing algorithms performance as compared to existing counterfactuals generated by token substitution. GYC generates counterfactuals that can act as test cases to evaluate a model and any text debiasing algorithm.
Reducing Overlearning through Disentangled Representations by Suppressing Unknown Tasks
May 20, 2020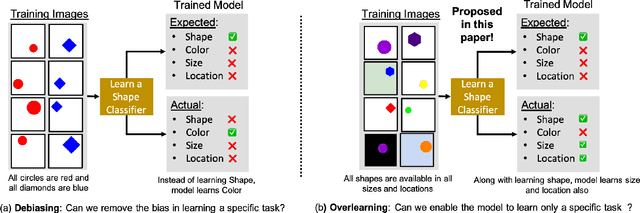
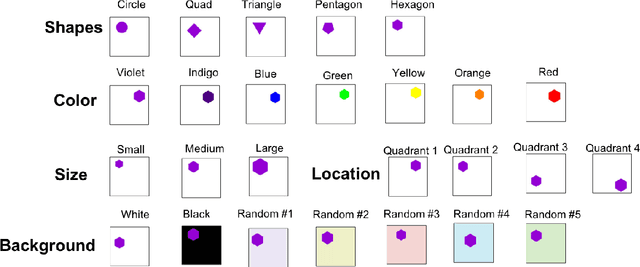
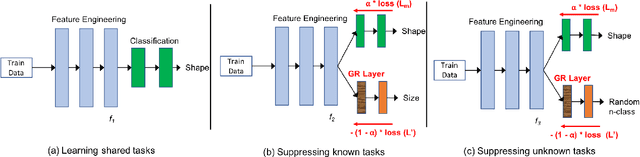
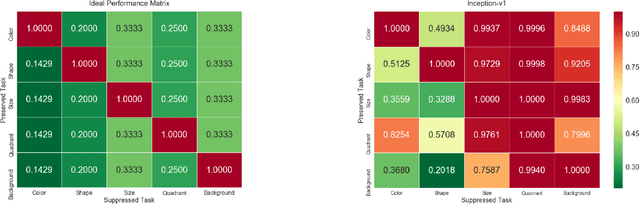
Existing deep learning approaches for learning visual features tend to overlearn and extract more information than what is required for the task at hand. From a privacy preservation perspective, the input visual information is not protected from the model; enabling the model to become more intelligent than it is trained to be. Current approaches for suppressing additional task learning assume the presence of ground truth labels for the tasks to be suppressed during training time. In this research, we propose a three-fold novel contribution: (i) a model-agnostic solution for reducing model overlearning by suppressing all the unknown tasks, (ii) a novel metric to measure the trust score of a trained deep learning model, and (iii) a simulated benchmark dataset, PreserveTask, having five different fundamental image classification tasks to study the generalization nature of models. In the first set of experiments, we learn disentangled representations and suppress overlearning of five popular deep learning models: VGG16, VGG19, Inception-v1, MobileNet, and DenseNet on PreserverTask dataset. Additionally, we show results of our framework on color-MNIST dataset and practical applications of face attribute preservation in Diversity in Faces (DiF) and IMDB-Wiki dataset.
A Visual Programming Paradigm for Abstract Deep Learning Model Development
May 07, 2019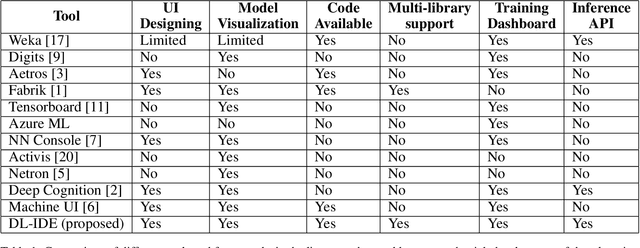
Deep learning is one of the fastest growing technologies in computer science with a plethora of applications. But this unprecedented growth has so far been limited to the consumption of deep learning experts. The primary challenge being a steep learning curve for learning the programming libraries and the lack of intuitive systems enabling non-experts to consume deep learning. Towards this goal, we study the effectiveness of a no-code paradigm for designing deep learning models. Particularly, a visual drag-and-drop interface is found more efficient when compared with the traditional programming and alternative visual programming paradigms. We conduct user studies of different expertise levels to measure the entry level barrier and the developer load across different programming paradigms. We obtain a System Usability Scale (SUS) of 90 and a NASA Task Load index (TLX) score of 21 for the proposed visual programming compared to 68 and 52, respectively, for the traditional programming methods.
Sanskrit Sandhi Splitting using $\pmb{seq2^2}$
Aug 27, 2018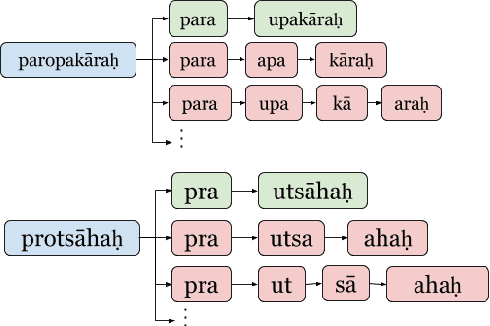
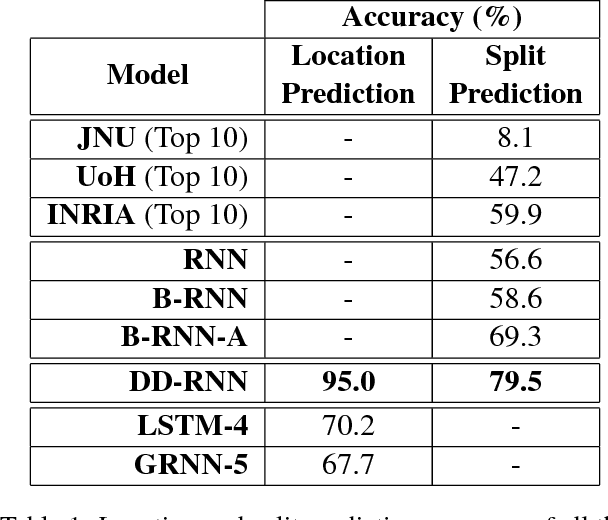
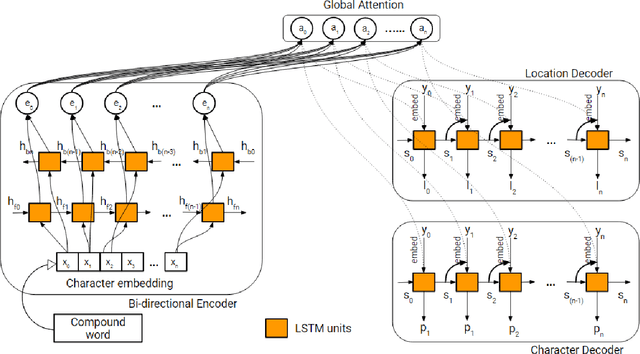
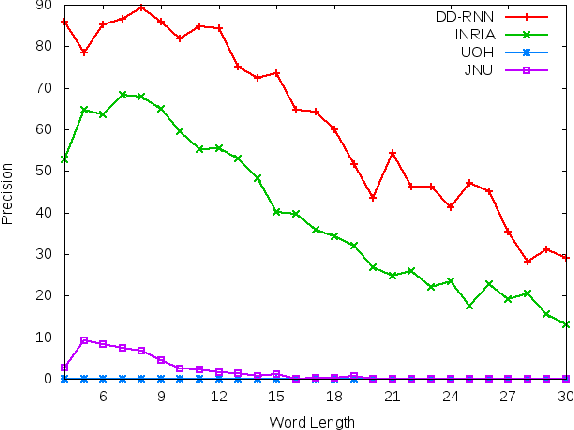
In Sanskrit, small words (morphemes) are combined to form compound words through a process known as Sandhi. Sandhi splitting is the process of splitting a given compound word into its constituent morphemes. Although rules governing word splitting exists in the language, it is highly challenging to identify the location of the splits in a compound word. Though existing Sandhi splitting systems incorporate these pre-defined splitting rules, they have a low accuracy as the same compound word might be broken down in multiple ways to provide syntactically correct splits. In this research, we propose a novel deep learning architecture called Double Decoder RNN (DD-RNN), which (i) predicts the location of the split(s) with 95% accuracy, and (ii) predicts the constituent words (learning the Sandhi splitting rules) with 79.5% accuracy, outperforming the state-of-art by 20%. Additionally, we show the generalization capability of our deep learning model, by showing competitive results in the problem of Chinese word segmentation, as well.
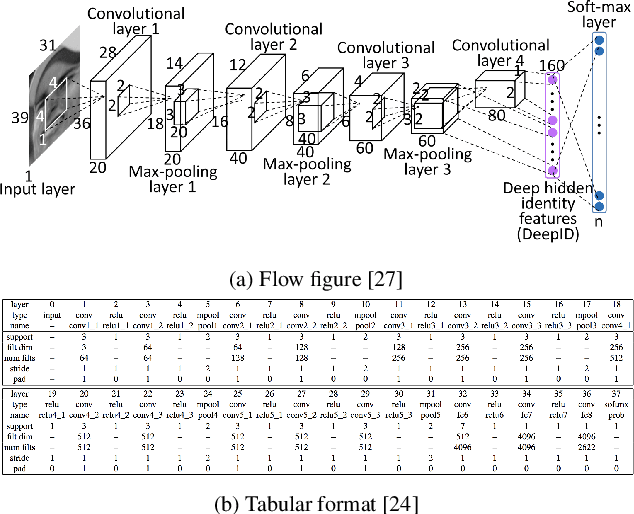
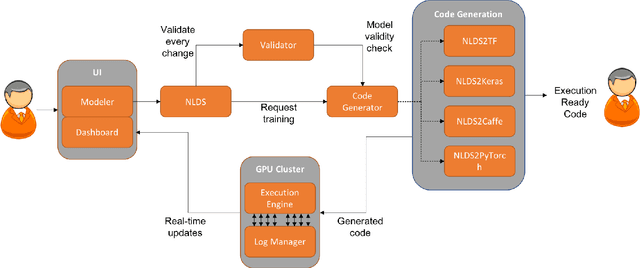
DLPaper2Code: Auto-generation of Code from Deep Learning Research Papers
Nov 09, 2017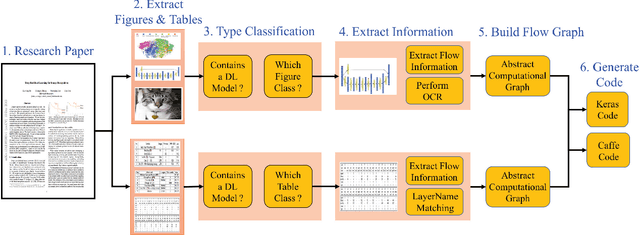
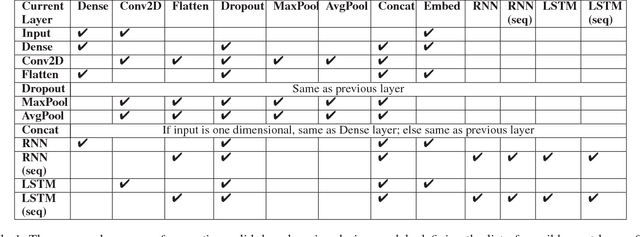

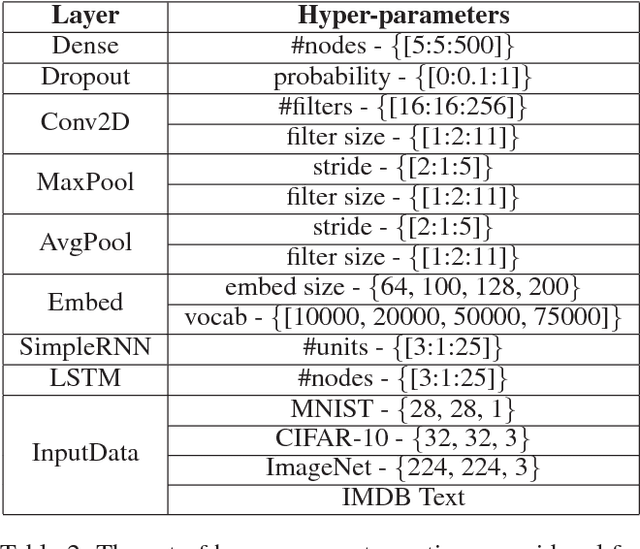
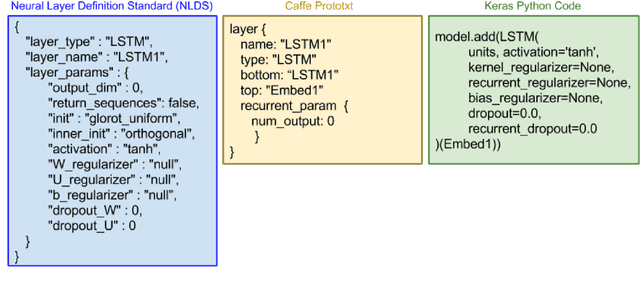
With an abundance of research papers in deep learning, reproducibility or adoption of the existing works becomes a challenge. This is due to the lack of open source implementations provided by the authors. Further, re-implementing research papers in a different library is a daunting task. To address these challenges, we propose a novel extensible approach, DLPaper2Code, to extract and understand deep learning design flow diagrams and tables available in a research paper and convert them to an abstract computational graph. The extracted computational graph is then converted into execution ready source code in both Keras and Caffe, in real-time. An arXiv-like website is created where the automatically generated designs is made publicly available for 5,000 research papers. The generated designs could be rated and edited using an intuitive drag-and-drop UI framework in a crowdsourced manner. To evaluate our approach, we create a simulated dataset with over 216,000 valid design visualizations using a manually defined grammar. Experiments on the simulated dataset show that the proposed framework provide more than $93\%$ accuracy in flow diagram content extraction.
mAnI: Movie Amalgamation using Neural Imitation
Aug 16, 2017
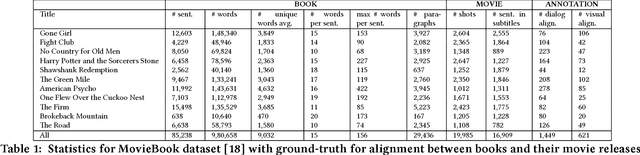

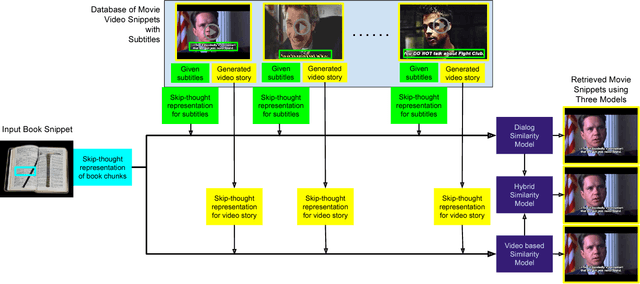
Cross-modal data retrieval has been the basis of various creative tasks performed by Artificial Intelligence (AI). One such highly challenging task for AI is to convert a book into its corresponding movie, which most of the creative film makers do as of today. In this research, we take the first step towards it by visualizing the content of a book using its corresponding movie visuals. Given a set of sentences from a book or even a fan-fiction written in the same universe, we employ deep learning models to visualize the input by stitching together relevant frames from the movie. We studied and compared three different types of setting to match the book with the movie content: (i) Dialog model: using only the dialog from the movie, (ii) Visual model: using only the visual content from the movie, and (iii) Hybrid model: using the dialog and the visual content from the movie. Experiments on the publicly available MovieBook dataset shows the effectiveness of the proposed models.