 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQVoice: Arabic Speech Pronunciation Learning Application
May 09, 2023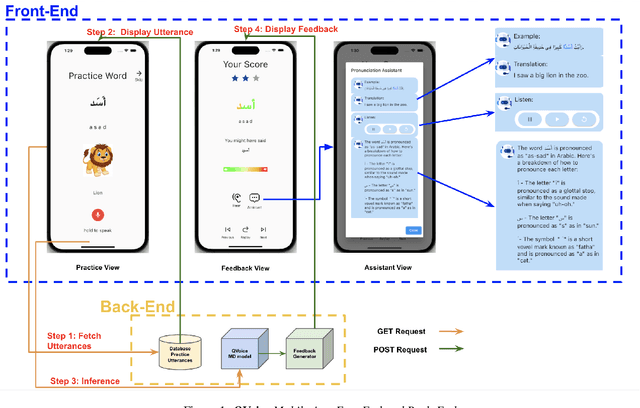
This paper introduces a novel Arabic pronunciation learning application QVoice, powered with end-to-end mispronunciation detection and feedback generator module. The application is designed to support non-native Arabic speakers in enhancing their pronunciation skills, while also helping native speakers mitigate any potential influence from regional dialects on their Modern Standard Arabic (MSA) pronunciation. QVoice employs various learning cues to aid learners in comprehending meaning, drawing connections with their existing knowledge of English language, and offers detailed feedback for pronunciation correction, along with contextual examples showcasing word usage. The learning cues featured in QVoice encompass a wide range of meaningful information, such as visualizations of phrases/words and their translations, as well as phonetic transcriptions and transliterations. QVoice provides pronunciation feedback at the character level and assesses performance at the word level.
* 2 pages, Accepted InterSpeech23 Show & Tell Demo Session
AutoDOViz: Human-Centered Automation for Decision Optimization
Feb 19, 2023



We present AutoDOViz, an interactive user interface for automated decision optimization (AutoDO) using reinforcement learning (RL). Decision optimization (DO) has classically being practiced by dedicated DO researchers where experts need to spend long periods of time fine tuning a solution through trial-and-error. AutoML pipeline search has sought to make it easier for a data scientist to find the best machine learning pipeline by leveraging automation to search and tune the solution. More recently, these advances have been applied to the domain of AutoDO, with a similar goal to find the best reinforcement learning pipeline through algorithm selection and parameter tuning. However, Decision Optimization requires significantly more complex problem specification when compared to an ML problem. AutoDOViz seeks to lower the barrier of entry for data scientists in problem specification for reinforcement learning problems, leverage the benefits of AutoDO algorithms for RL pipeline search and finally, create visualizations and policy insights in order to facilitate the typical interactive nature when communicating problem formulation and solution proposals between DO experts and domain experts. In this paper, we report our findings from semi-structured expert interviews with DO practitioners as well as business consultants, leading to design requirements for human-centered automation for DO with RL. We evaluate a system implementation with data scientists and find that they are significantly more open to engage in DO after using our proposed solution. AutoDOViz further increases trust in RL agent models and makes the automated training and evaluation process more comprehensible. As shown for other automation in ML tasks, we also conclude automation of RL for DO can benefit from user and vice-versa when the interface promotes human-in-the-loop.
SpeechBlender: Speech Augmentation Framework for Mispronunciation Data Generation
Nov 02, 2022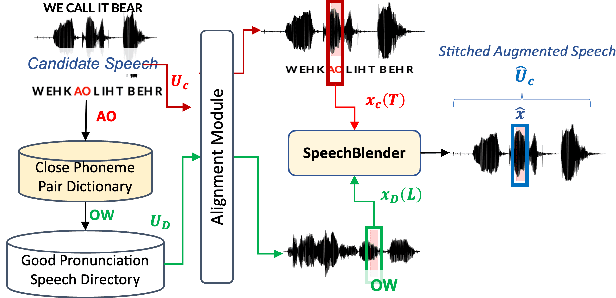

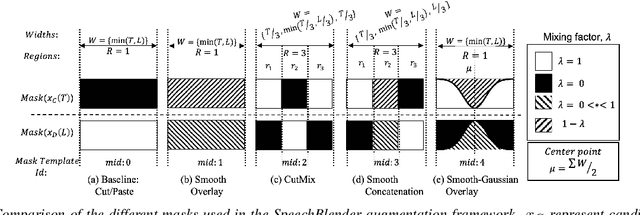
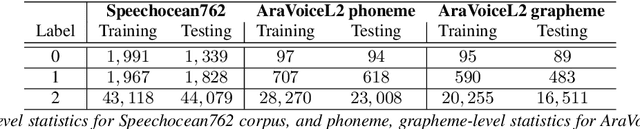
One of the biggest challenges in designing mispronunciation detection models is the unavailability of labeled L2 speech data. To overcome such data scarcity, we introduce SpeechBlender -- a fine-grained data augmentation pipeline for generating mispronunciation errors. The SpeechBlender utilizes varieties of masks to target different regions of a phonetic unit, and use the mixing factors to linearly interpolate raw speech signals while generating erroneous pronunciation instances. The masks facilitate smooth blending of the signals, thus generating more effective samples than the `Cut/Paste' method. We show the effectiveness of our augmentation technique in a phoneme-level pronunciation quality assessment task, leveraging only a good pronunciation dataset. With SpeechBlender augmentation, we observed a 3% and 2% increase in Pearson correlation coefficient (PCC) compared to no-augmentation and goodness of pronunciation augmentation scenarios respectively for Speechocean762 testset. Moreover, a 2% rise in PCC is observed when comparing our single-task phoneme-level mispronunciation detection model with a multi-task learning model using multiple-granularity information.
Data Quality Toolkit: Automatic assessment of data quality and remediation for machine learning datasets
Sep 05, 2021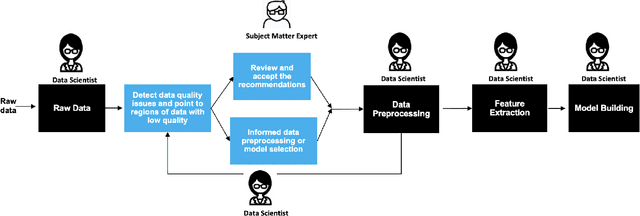

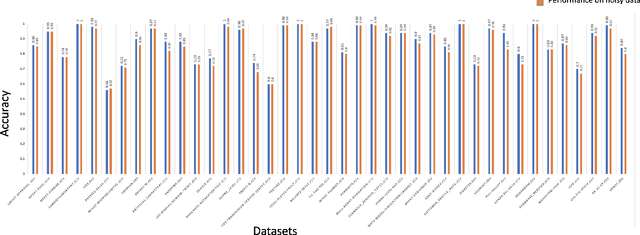
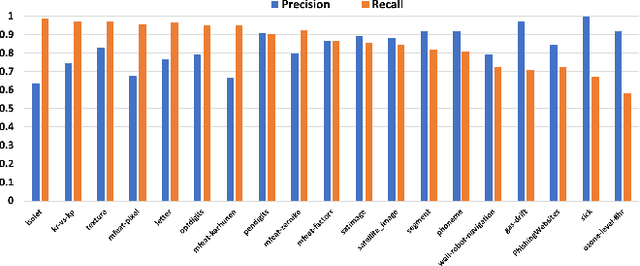
The quality of training data has a huge impact on the efficiency, accuracy and complexity of machine learning tasks. Various tools and techniques are available that assess data quality with respect to general cleaning and profiling checks. However these techniques are not applicable to detect data issues in the context of machine learning tasks, like noisy labels, existence of overlapping classes etc. We attempt to re-look at the data quality issues in the context of building a machine learning pipeline and build a tool that can detect, explain and remediate issues in the data, and systematically and automatically capture all the changes applied to the data. We introduce the Data Quality Toolkit for machine learning as a library of some key quality metrics and relevant remediation techniques to analyze and enhance the readiness of structured training datasets for machine learning projects. The toolkit can reduce the turn-around times of data preparation pipelines and streamline the data quality assessment process. Our toolkit is publicly available via IBM API Hub [1] platform, any developer can assess the data quality using the IBM's Data Quality for AI apis [2]. Detailed tutorials are also available on IBM Learning Path [3].
Data Readiness Report
Oct 15, 2020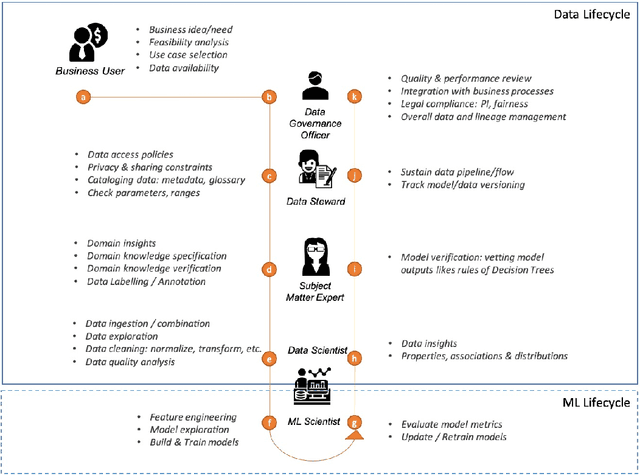
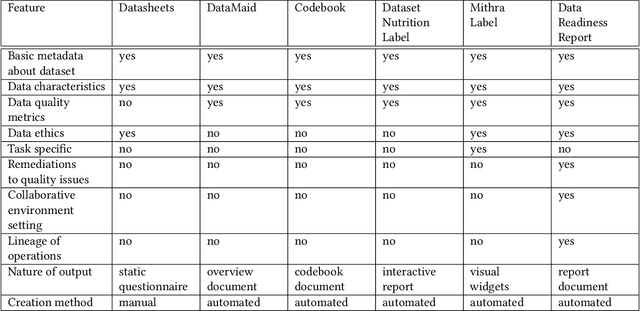
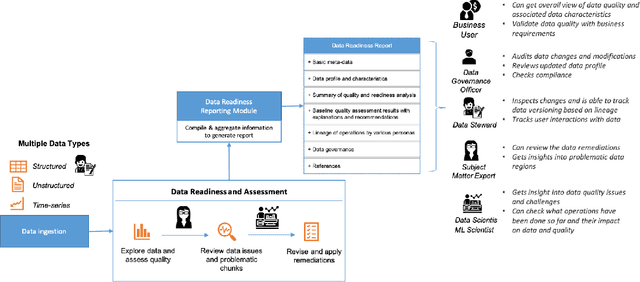

Data exploration and quality analysis is an important yet tedious process in the AI pipeline. Current practices of data cleaning and data readiness assessment for machine learning tasks are mostly conducted in an arbitrary manner which limits their reuse and results in loss of productivity. We introduce the concept of a Data Readiness Report as an accompanying documentation to a dataset that allows data consumers to get detailed insights into the quality of input data. Data characteristics and challenges on various quality dimensions are identified and documented keeping in mind the principles of transparency and explainability. The Data Readiness Report also serves as a record of all data assessment operations including applied transformations. This provides a detailed lineage for the purpose of data governance and management. In effect, the report captures and documents the actions taken by various personas in a data readiness and assessment workflow. Overtime this becomes a repository of best practices and can potentially drive a recommendation system for building automated data readiness workflows on the lines of AutoML [8]. We anticipate that together with the Datasheets [9], Dataset Nutrition Label [11], FactSheets [1] and Model Cards [15], the Data Readiness Report makes significant progress towards Data and AI lifecycle documentation.