 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeechBlender: Speech Augmentation Framework for Mispronunciation Data Generation
Paper and Code
Nov 02, 2022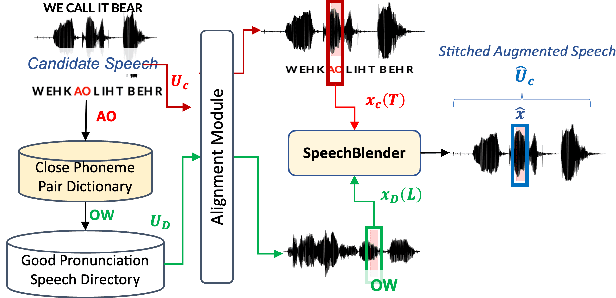

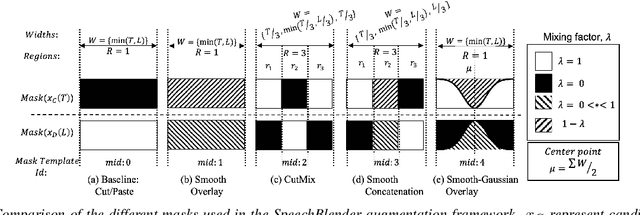
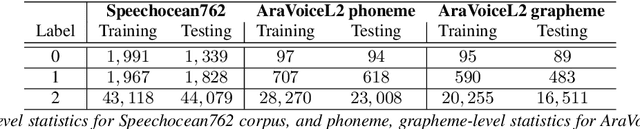
One of the biggest challenges in designing mispronunciation detection models is the unavailability of labeled L2 speech data. To overcome such data scarcity, we introduce SpeechBlender -- a fine-grained data augmentation pipeline for generating mispronunciation errors. The SpeechBlender utilizes varieties of masks to target different regions of a phonetic unit, and use the mixing factors to linearly interpolate raw speech signals while generating erroneous pronunciation instances. The masks facilitate smooth blending of the signals, thus generating more effective samples than the `Cut/Paste' method. We show the effectiveness of our augmentation technique in a phoneme-level pronunciation quality assessment task, leveraging only a good pronunciation dataset. With SpeechBlender augmentation, we observed a 3% and 2% increase in Pearson correlation coefficient (PCC) compared to no-augmentation and goodness of pronunciation augmentation scenarios respectively for Speechocean762 testset. Moreover, a 2% rise in PCC is observed when comparing our single-task phoneme-level mispronunciation detection model with a multi-task learning model using multiple-granularity information.