 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM driven Text-to-Table Generation through Sub-Tasks Guidance and Iterative Refinement
Aug 12, 2025Transforming unstructured text into structured data is a complex task, requiring semantic understanding, reasoning, and structural comprehension. While Large Language Models (LLMs) offer potential, they often struggle with handling ambiguous or domain-specific data, maintaining table structure, managing long inputs, and addressing numerical reasoning. This paper proposes an efficient system for LLM-driven text-to-table generation that leverages novel prompting techniques. Specifically, the system incorporates two key strategies: breaking down the text-to-table task into manageable, guided sub-tasks and refining the generated tables through iterative self-feedback. We show that this custom task decomposition allows the model to address the problem in a stepwise manner and improves the quality of the generated table. Furthermore, we discuss the benefits and potential risks associated with iterative self-feedback on the generated tables while highlighting the trade-offs between enhanced performance and computational cost. Our methods achieve strong results compared to baselines on two complex text-to-table generation datasets available in the public domain.
The Mighty ToRR: A Benchmark for Table Reasoning and Robustness
Feb 26, 2025



Despite its real-world significance, model performance on tabular data remains underexplored, leaving uncertainty about which model to rely on and which prompt configuration to adopt. To address this gap, we create ToRR, a benchmark for Table Reasoning and Robustness, that measures model performance and robustness on table-related tasks. The benchmark includes 10 datasets that cover different types of table reasoning capabilities across varied domains. ToRR goes beyond model performance rankings, and is designed to reflect whether models can handle tabular data consistently and robustly, across a variety of common table representation formats. We present a leaderboard as well as comprehensive analyses of the results of leading models over ToRR. Our results reveal a striking pattern of brittle model behavior, where even strong models are unable to perform robustly on tabular data tasks. Although no specific table format leads to consistently better performance, we show that testing over multiple formats is crucial for reliably estimating model capabilities. Moreover, we show that the reliability boost from testing multiple prompts can be equivalent to adding more test examples. Overall, our findings show that table understanding and reasoning tasks remain a significant challenge.
Data Readiness Report
Oct 15, 2020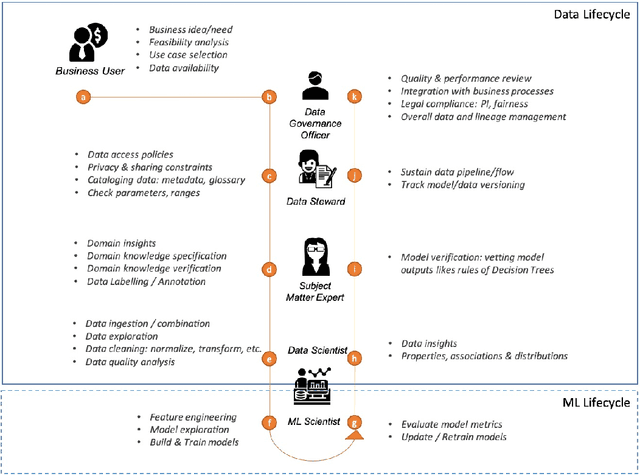
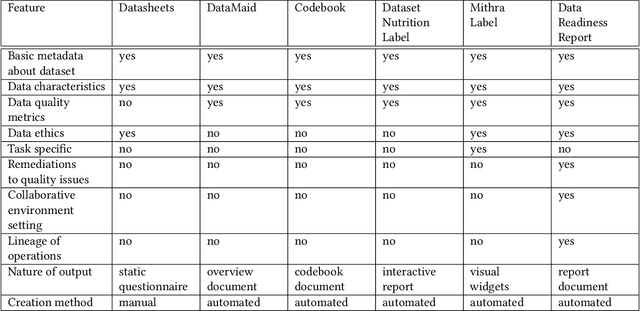
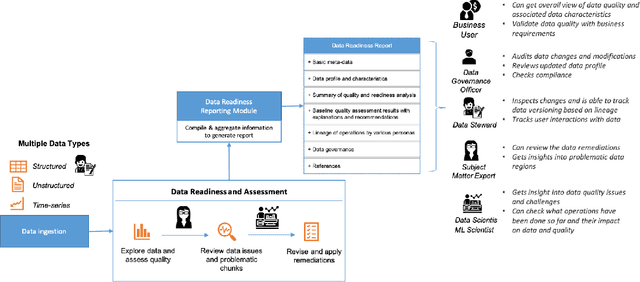

Data exploration and quality analysis is an important yet tedious process in the AI pipeline. Current practices of data cleaning and data readiness assessment for machine learning tasks are mostly conducted in an arbitrary manner which limits their reuse and results in loss of productivity. We introduce the concept of a Data Readiness Report as an accompanying documentation to a dataset that allows data consumers to get detailed insights into the quality of input data. Data characteristics and challenges on various quality dimensions are identified and documented keeping in mind the principles of transparency and explainability. The Data Readiness Report also serves as a record of all data assessment operations including applied transformations. This provides a detailed lineage for the purpose of data governance and management. In effect, the report captures and documents the actions taken by various personas in a data readiness and assessment workflow. Overtime this becomes a repository of best practices and can potentially drive a recommendation system for building automated data readiness workflows on the lines of AutoML [8]. We anticipate that together with the Datasheets [9], Dataset Nutrition Label [11], FactSheets [1] and Model Cards [15], the Data Readiness Report makes significant progress towards Data and AI lifecycle documentation.