 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Discounting of Implicit Language Models in RNN-Transducers
Feb 21, 2022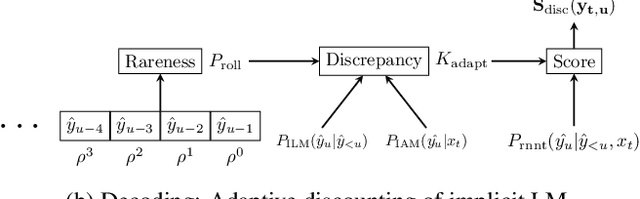
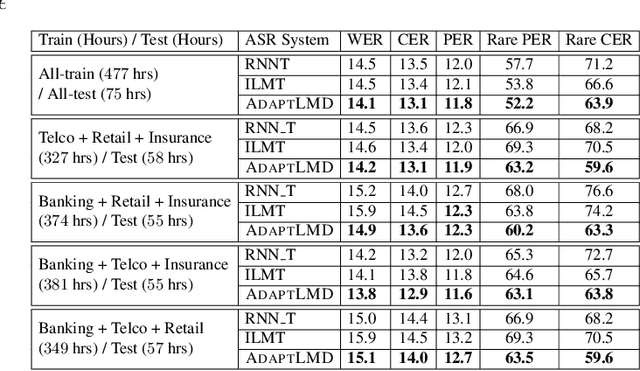
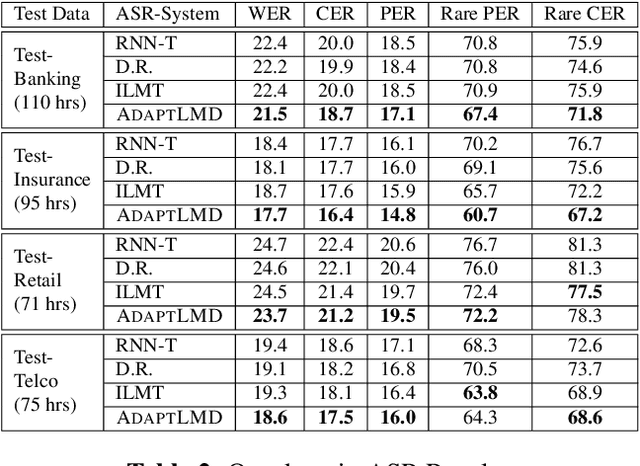
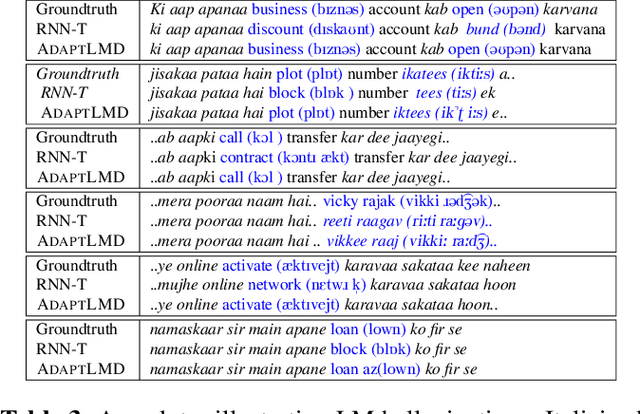
RNN-Transducer (RNN-T) models have become synonymous with streaming end-to-end ASR systems. While they perform competitively on a number of evaluation categories, rare words pose a serious challenge to RNN-T models. One main reason for the degradation in performance on rare words is that the language model (LM) internal to RNN-Ts can become overconfident and lead to hallucinated predictions that are acoustically inconsistent with the underlying speech. To address this issue, we propose a lightweight adaptive LM discounting technique AdaptLMD, that can be used with any RNN-T architecture without requiring any external resources or additional parameters. AdaptLMD uses a two-pronged approach: 1) Randomly mask the prediction network output to encourage the RNN-T to not be overly reliant on it's outputs. 2) Dynamically choose when to discount the implicit LM (ILM) based on rarity of recently predicted tokens and divergence between ILM and implicit acoustic model (IAM) scores. Comparing AdaptLMD to a competitive RNN-T baseline, we obtain up to 4% and 14% relative reductions in overall WER and rare word PER, respectively, on a conversational, code-mixed Hindi-English ASR task.
Representation based meta-learning for few-shot spoken intent recognition
Jun 29, 2021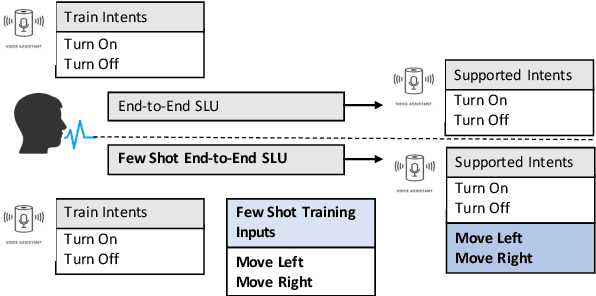
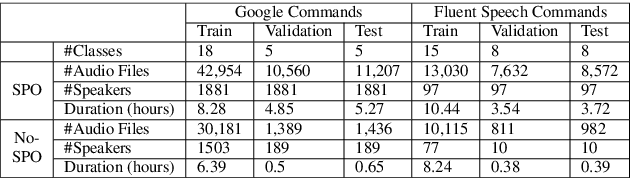
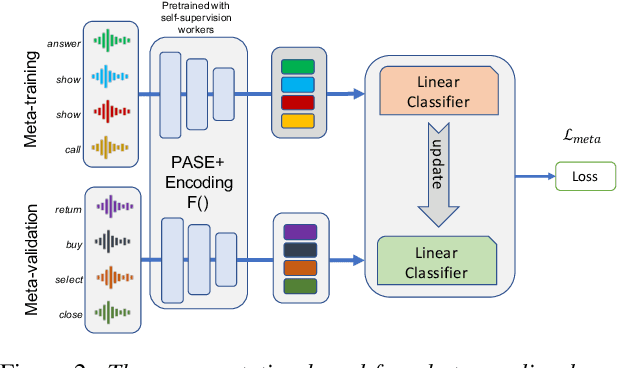
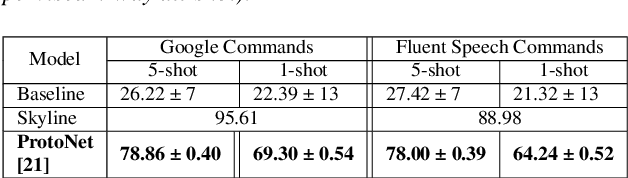
Spoken intent detection has become a popular approach to interface with various smart devices with ease. However, such systems are limited to the preset list of intents-terms or commands, which restricts the quick customization of personal devices to new intents. This paper presents a few-shot spoken intent classification approach with task-agnostic representations via meta-learning paradigm. Specifically, we leverage the popular representation-based meta-learning learning to build a task-agnostic representation of utterances, that then use a linear classifier for prediction. We evaluate three such approaches on our novel experimental protocol developed on two popular spoken intent classification datasets: Google Commands and the Fluent Speech Commands dataset. For a 5-shot (1-shot) classification of novel classes, the proposed framework provides an average classification accuracy of 88.6% (76.3%) on the Google Commands dataset, and 78.5% (64.2%) on the Fluent Speech Commands dataset. The performance is comparable to traditionally supervised classification models with abundant training samples.
Multilingual and code-switching ASR challenges for low resource Indian languages
Apr 01, 2021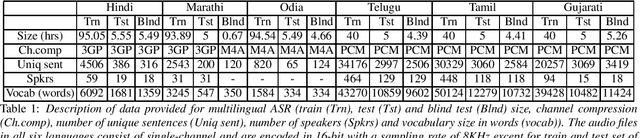
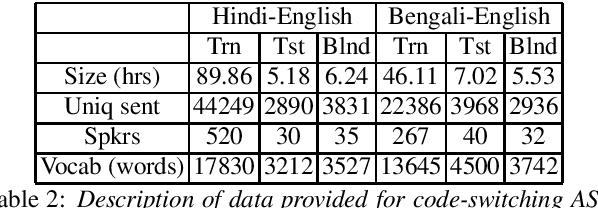
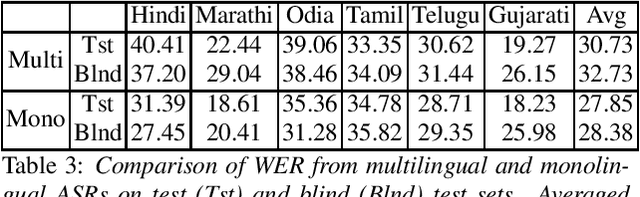
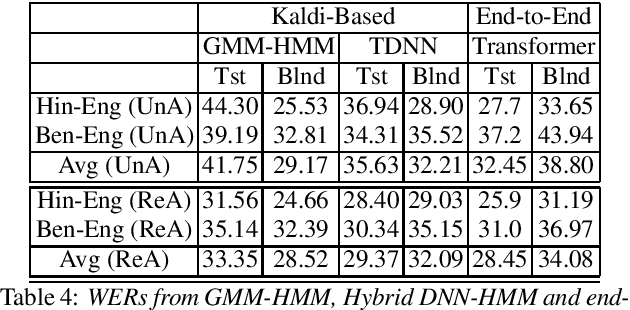
Recently, there is increasing interest in multilingual automatic speech recognition (ASR) where a speech recognition system caters to multiple low resource languages by taking advantage of low amounts of labeled corpora in multiple languages. With multilingualism becoming common in today's world, there has been increasing interest in code-switching ASR as well. In code-switching, multiple languages are freely interchanged within a single sentence or between sentences. The success of low-resource multilingual and code-switching ASR often depends on the variety of languages in terms of their acoustics, linguistic characteristics as well as the amount of data available and how these are carefully considered in building the ASR system. In this challenge, we would like to focus on building multilingual and code-switching ASR systems through two different subtasks related to a total of seven Indian languages, namely Hindi, Marathi, Odia, Tamil, Telugu, Gujarati and Bengali. For this purpose, we provide a total of ~600 hours of transcribed speech data, comprising train and test sets, in these languages including two code-switched language pairs, Hindi-English and Bengali-English. We also provide a baseline recipe for both the tasks with a WER of 30.73% and 32.45% on the test sets of multilingual and code-switching subtasks, respectively.
Adversarial Black-Box Attacks On Text Classifiers Using Multi-Objective Genetic Optimization Guided By Deep Networks
Nov 10, 2020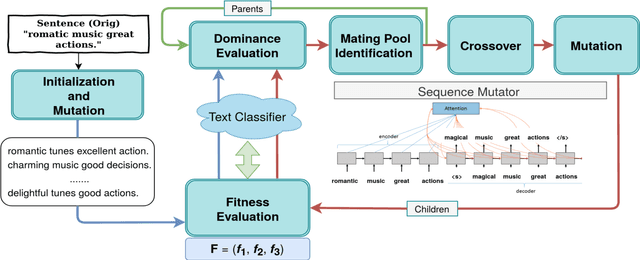

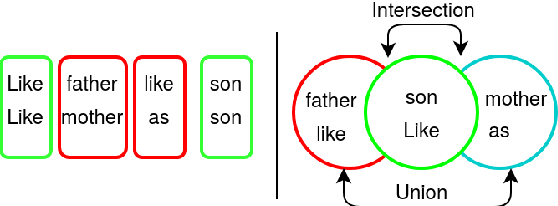

We propose a novel genetic-algorithm technique that generates black-box adversarial examples which successfully fool neural network based text classifiers. We perform a genetic search with multi-objective optimization guided by deep learning based inferences and Seq2Seq mutation to generate semantically similar but imperceptible adversaries. We compare our approach with DeepWordBug (DWB) on SST and IMDB sentiment datasets by attacking three trained models viz. char-LSTM, word-LSTM and elmo-LSTM. On an average, we achieve an attack success rate of 65.67% for SST and 36.45% for IMDB across the three models showing an improvement of 49.48% and 101% respectively. Furthermore, our qualitative study indicates that 94% of the time, the users were not able to distinguish between an original and adversarial sample.
Benchmarking Popular Classification Models' Robustness to Random and Targeted Corruptions
Jan 31, 2020
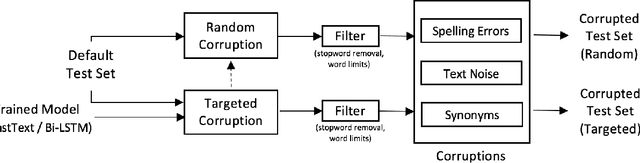

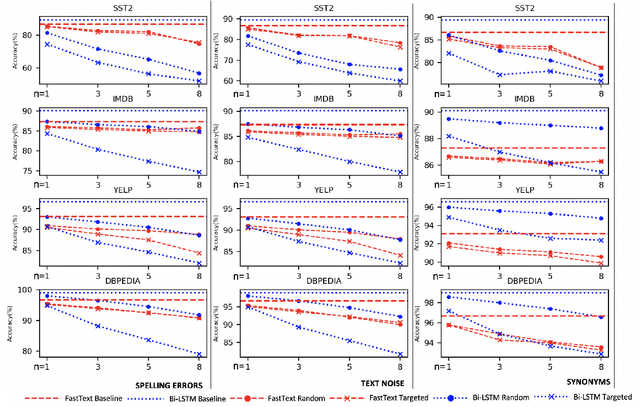
Text classification models, especially neural networks based models, have reached very high accuracy on many popular benchmark datasets. Yet, such models when deployed in real world applications, tend to perform badly. The primary reason is that these models are not tested against sufficient real world natural data. Based on the application users, the vocabulary and the style of the model's input may greatly vary. This emphasizes the need for a model agnostic test dataset, which consists of various corruptions that are natural to appear in the wild. Models trained and tested on such benchmark datasets, will be more robust against real world data. However, such data sets are not easily available. In this work, we address this problem, by extending the benchmark datasets along naturally occurring corruptions such as Spelling Errors, Text Noise and Synonyms and making them publicly available. Through extensive experiments, we compare random and targeted corruption strategies using Local Interpretable Model-Agnostic Explanations(LIME). We report the vulnerabilities in two popular text classification models along these corruptions and also find that targeted corruptions can expose vulnerabilities of a model better than random choices in most cases.
A Visual Programming Paradigm for Abstract Deep Learning Model Development
May 07, 2019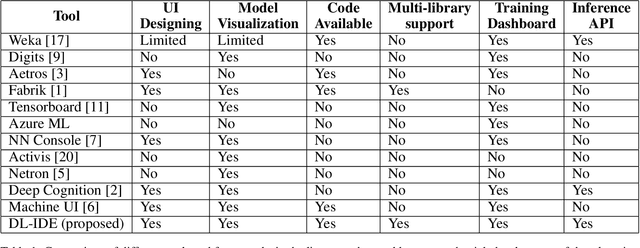
Deep learning is one of the fastest growing technologies in computer science with a plethora of applications. But this unprecedented growth has so far been limited to the consumption of deep learning experts. The primary challenge being a steep learning curve for learning the programming libraries and the lack of intuitive systems enabling non-experts to consume deep learning. Towards this goal, we study the effectiveness of a no-code paradigm for designing deep learning models. Particularly, a visual drag-and-drop interface is found more efficient when compared with the traditional programming and alternative visual programming paradigms. We conduct user studies of different expertise levels to measure the entry level barrier and the developer load across different programming paradigms. We obtain a System Usability Scale (SUS) of 90 and a NASA Task Load index (TLX) score of 21 for the proposed visual programming compared to 68 and 52, respectively, for the traditional programming methods.
Adversarial Black-Box Attacks for Automatic Speech Recognition Systems Using Multi-Objective Genetic Optimization
Nov 04, 2018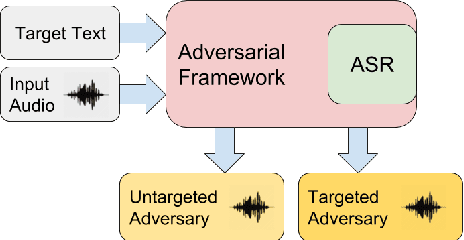

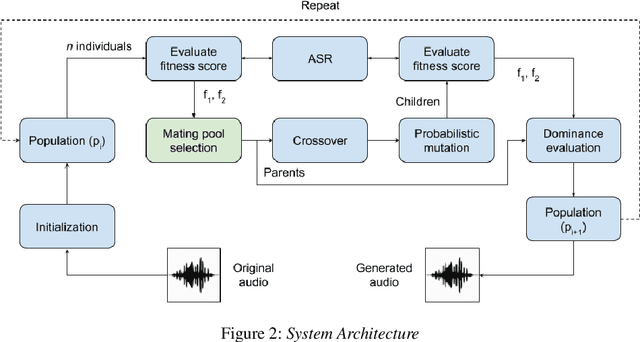
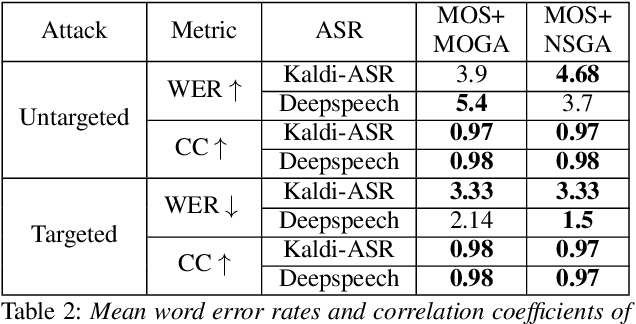
Fooling deep neural networks with adversarial input have exposed a significant vulnerability in current state-of-the-art systems in multiple domains. Both black-box and white-box approaches have been used to either replicate the model itself or to craft examples which cause the model to fail. In this work, we use a multi-objective genetic algorithm based approach to perform both targeted and un-targeted black-box attacks on automatic speech recognition (ASR) systems. The main contribution of this research is the proposal of a generic framework which can be used to attack any ASR system, even if it's internal working is hidden. During the un-targeted attacks, the Word Error Rates (WER) of the ASR degrades from 0.5 to 5.4, indicating the potency of our approach. In targeted attacks, our solution reaches a WER of 2.14. In both attacks, the adversarial samples maintain a high acoustic similarity of 0.98 and 0.97.
DLPaper2Code: Auto-generation of Code from Deep Learning Research Papers
Nov 09, 2017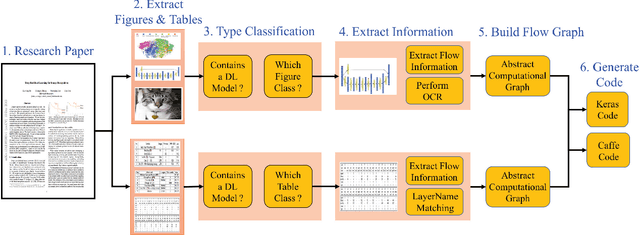
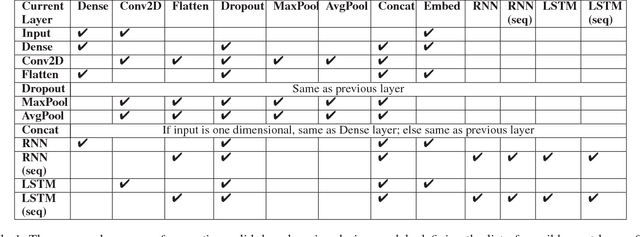

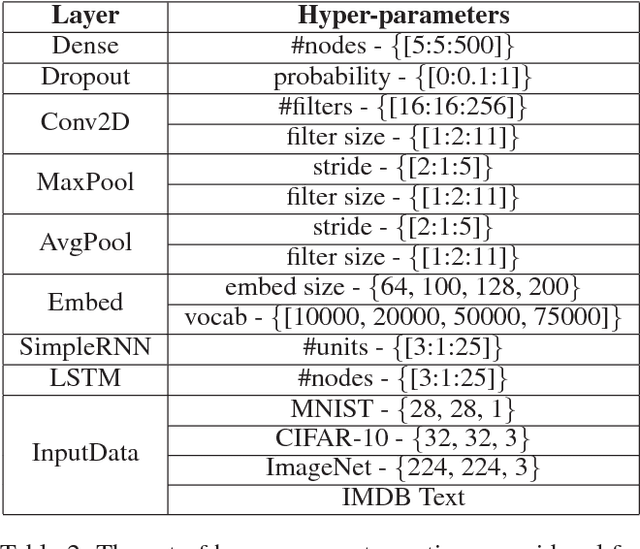
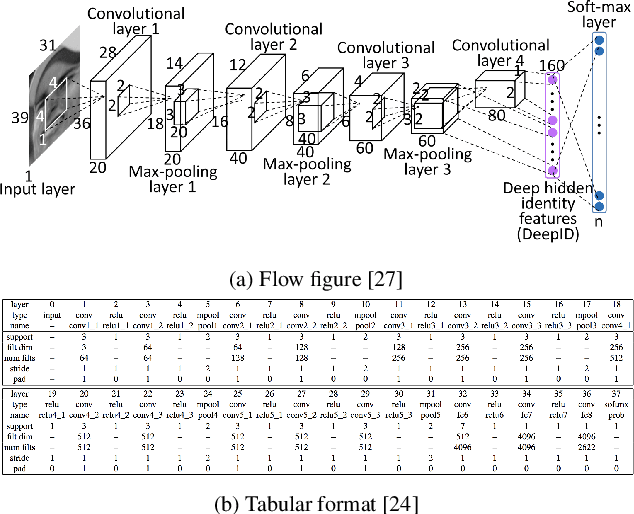
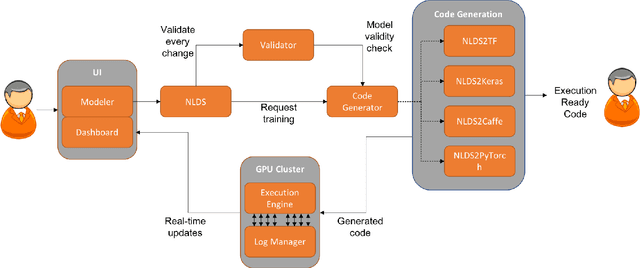
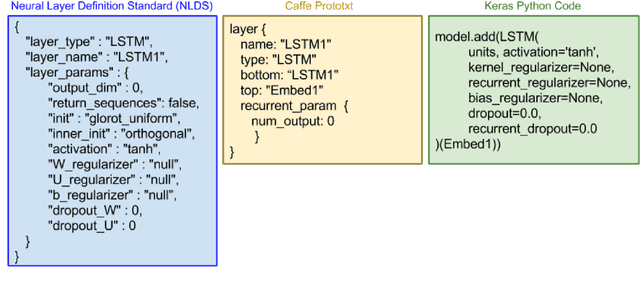
With an abundance of research papers in deep learning, reproducibility or adoption of the existing works becomes a challenge. This is due to the lack of open source implementations provided by the authors. Further, re-implementing research papers in a different library is a daunting task. To address these challenges, we propose a novel extensible approach, DLPaper2Code, to extract and understand deep learning design flow diagrams and tables available in a research paper and convert them to an abstract computational graph. The extracted computational graph is then converted into execution ready source code in both Keras and Caffe, in real-time. An arXiv-like website is created where the automatically generated designs is made publicly available for 5,000 research papers. The generated designs could be rated and edited using an intuitive drag-and-drop UI framework in a crowdsourced manner. To evaluate our approach, we create a simulated dataset with over 216,000 valid design visualizations using a manually defined grammar. Experiments on the simulated dataset show that the proposed framework provide more than $93\%$ accuracy in flow diagram content extraction.
Hi, how can I help you?: Automating enterprise IT support help desks
Nov 02, 2017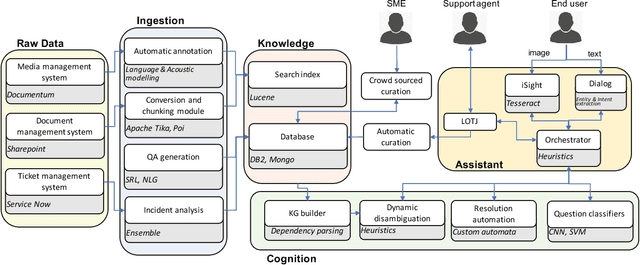
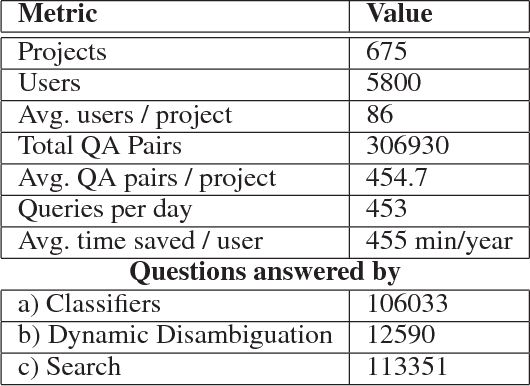
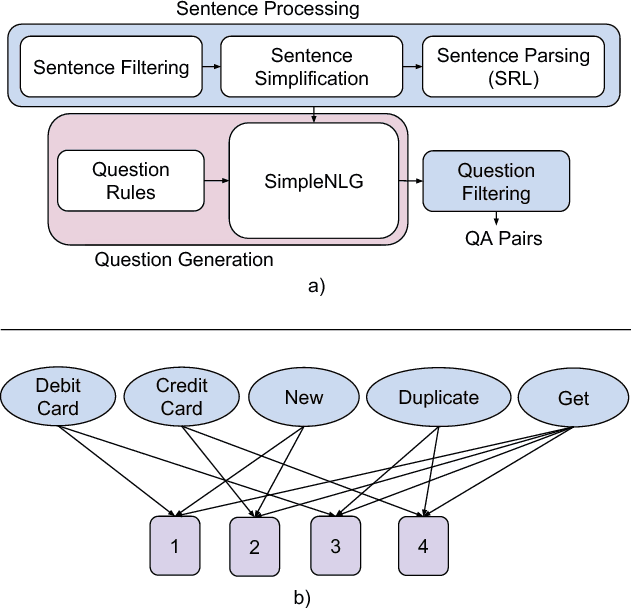
Question answering is one of the primary challenges of natural language understanding. In realizing such a system, providing complex long answers to questions is a challenging task as opposed to factoid answering as the former needs context disambiguation. The different methods explored in the literature can be broadly classified into three categories namely: 1) classification based, 2) knowledge graph based and 3) retrieval based. Individually, none of them address the need of an enterprise wide assistance system for an IT support and maintenance domain. In this domain the variance of answers is large ranging from factoid to structured operating procedures; the knowledge is present across heterogeneous data sources like application specific documentation, ticket management systems and any single technique for a general purpose assistance is unable to scale for such a landscape. To address this, we have built a cognitive platform with capabilities adopted for this domain. Further, we have built a general purpose question answering system leveraging the platform that can be instantiated for multiple products, technologies in the support domain. The system uses a novel hybrid answering model that orchestrates across a deep learning classifier, a knowledge graph based context disambiguation module and a sophisticated bag-of-words search system. This orchestration performs context switching for a provided question and also does a smooth hand-off of the question to a human expert if none of the automated techniques can provide a confident answer. This system has been deployed across 675 internal enterprise IT support and maintenance projects.
mAnI: Movie Amalgamation using Neural Imitation
Aug 16, 2017
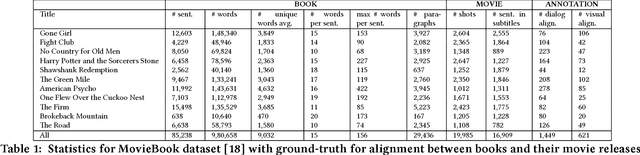

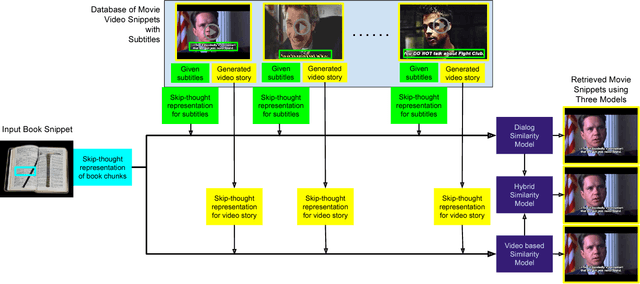
Cross-modal data retrieval has been the basis of various creative tasks performed by Artificial Intelligence (AI). One such highly challenging task for AI is to convert a book into its corresponding movie, which most of the creative film makers do as of today. In this research, we take the first step towards it by visualizing the content of a book using its corresponding movie visuals. Given a set of sentences from a book or even a fan-fiction written in the same universe, we employ deep learning models to visualize the input by stitching together relevant frames from the movie. We studied and compared three different types of setting to match the book with the movie content: (i) Dialog model: using only the dialog from the movie, (ii) Visual model: using only the visual content from the movie, and (iii) Hybrid model: using the dialog and the visual content from the movie. Experiments on the publicly available MovieBook dataset shows the effectiveness of the proposed models.