 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffNMR2: NMR Guided Sampling Acquisition Through Diffusion Model Uncertainty
Feb 06, 2025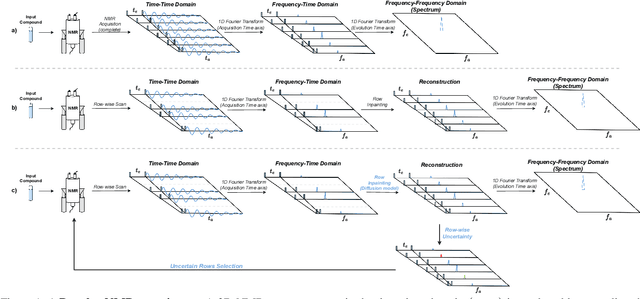
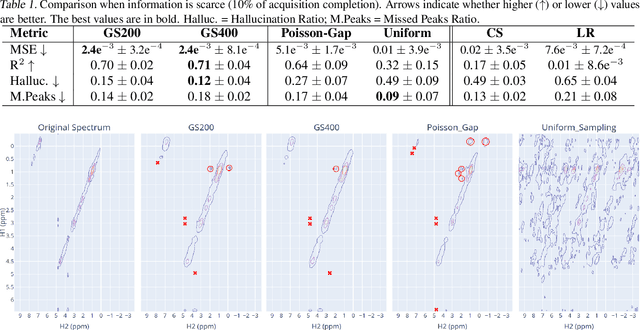
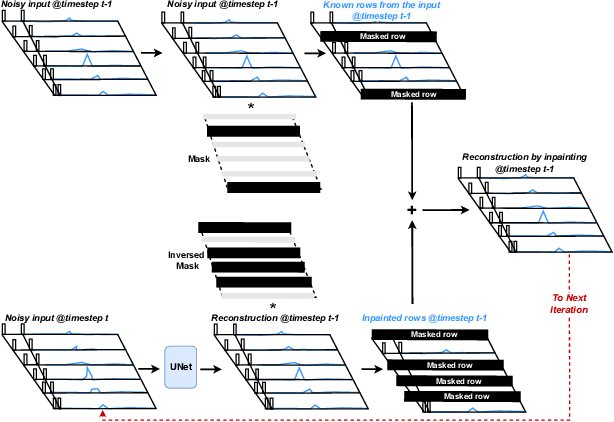
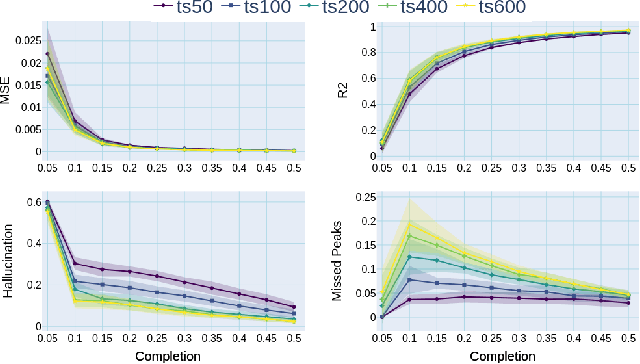
Nuclear Magnetic Resonance (NMR) spectrometry uses electro-frequency pulses to probe the resonance of a compound's nucleus, which is then analyzed to determine its structure. The acquisition time of high-resolution NMR spectra remains a significant bottleneck, especially for complex biological samples such as proteins. In this study, we propose a novel and efficient sub-sampling strategy based on a diffusion model trained on protein NMR data. Our method iteratively reconstructs under-sampled spectra while using model uncertainty to guide subsequent sampling, significantly reducing acquisition time. Compared to state-of-the-art strategies, our approach improves reconstruction accuracy by 52.9\%, reduces hallucinated peaks by 55.6%, and requires 60% less time in complex NMR experiments. This advancement holds promise for many applications, from drug discovery to materials science, where rapid and high-resolution spectral analysis is critical.
Multilingual and code-switching ASR challenges for low resource Indian languages
Apr 01, 2021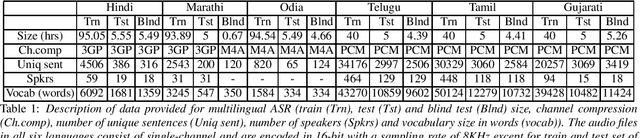
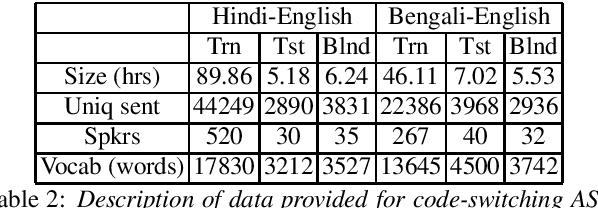
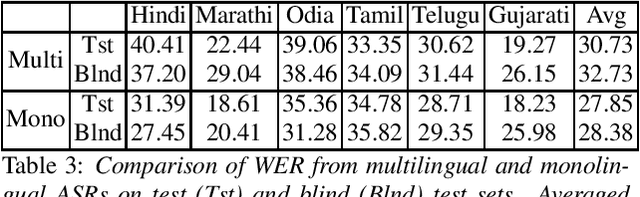
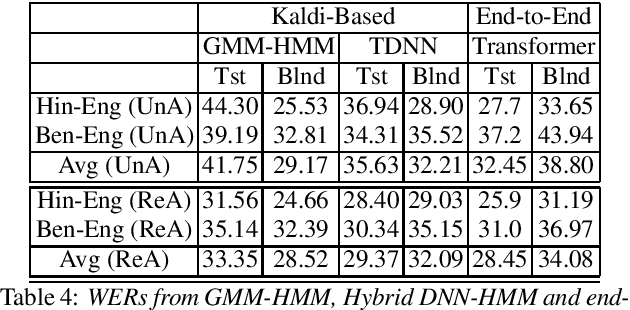
Recently, there is increasing interest in multilingual automatic speech recognition (ASR) where a speech recognition system caters to multiple low resource languages by taking advantage of low amounts of labeled corpora in multiple languages. With multilingualism becoming common in today's world, there has been increasing interest in code-switching ASR as well. In code-switching, multiple languages are freely interchanged within a single sentence or between sentences. The success of low-resource multilingual and code-switching ASR often depends on the variety of languages in terms of their acoustics, linguistic characteristics as well as the amount of data available and how these are carefully considered in building the ASR system. In this challenge, we would like to focus on building multilingual and code-switching ASR systems through two different subtasks related to a total of seven Indian languages, namely Hindi, Marathi, Odia, Tamil, Telugu, Gujarati and Bengali. For this purpose, we provide a total of ~600 hours of transcribed speech data, comprising train and test sets, in these languages including two code-switched language pairs, Hindi-English and Bengali-English. We also provide a baseline recipe for both the tasks with a WER of 30.73% and 32.45% on the test sets of multilingual and code-switching subtasks, respectively.