 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reasoning-Aware Explainable VQA
Nov 09, 2022The domain of joint vision-language understanding, especially in the context of reasoning in Visual Question Answering (VQA) models, has garnered significant attention in the recent past. While most of the existing VQA models focus on improving the accuracy of VQA, the way models arrive at an answer is oftentimes a black box. As a step towards making the VQA task more explainable and interpretable, our method is built upon the SOTA VQA framework by augmenting it with an end-to-end explanation generation module. In this paper, we investigate two network architectures, including Long Short-Term Memory (LSTM) and Transformer decoder, as the explanation generator. Our method generates human-readable textual explanations while maintaining SOTA VQA accuracy on the GQA-REX (77.49%) and VQA-E (71.48%) datasets. Approximately 65.16% of the generated explanations are approved by humans as valid. Roughly 60.5% of the generated explanations are valid and lead to the correct answers.
A study on native American English speech recognition by Indian listeners with varying word familiarity level
Dec 08, 2021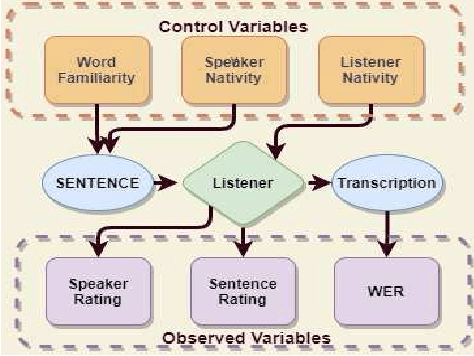
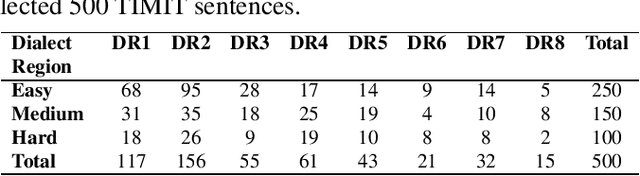
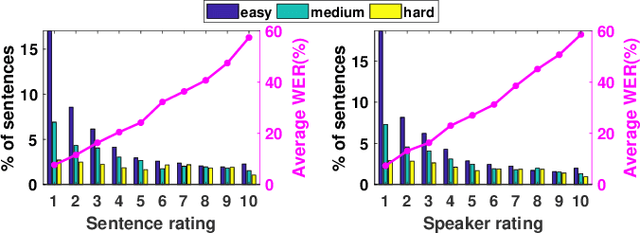
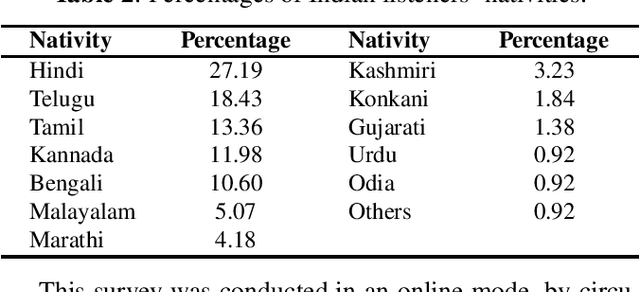
In this study, listeners of varied Indian nativities are asked to listen and recognize TIMIT utterances spoken by American speakers. We have three kinds of responses from each listener while they recognize an utterance: 1. Sentence difficulty ratings, 2. Speaker difficulty ratings, and 3. Transcription of the utterance. From these transcriptions, word error rate (WER) is calculated and used as a metric to evaluate the similarity between the recognized and the original sentences.The sentences selected in this study are categorized into three groups: Easy, Medium and Hard, based on the frequency ofoccurrence of the words in them. We observe that the sentence, speaker difficulty ratings and the WERs increase from easy to hard categories of sentences. We also compare the human speech recognition performance with that using three automatic speech recognition (ASR) under following three combinations of acoustic model (AM) and language model(LM): ASR1) AM trained with recordings from speakers of Indian origin and LM built on TIMIT text, ASR2) AM using recordings from native American speakers and LM built ontext from LIBRI speech corpus, and ASR3) AM using recordings from native American speakers and LM build on LIBRI speech and TIMIT text. We observe that HSR performance is similar to that of ASR1 whereas ASR3 achieves the best performance. Speaker nativity wise analysis shows that utterances from speakers of some nativity are more difficult to recognize by Indian listeners compared to few other nativities
Multilingual and code-switching ASR challenges for low resource Indian languages
Apr 01, 2021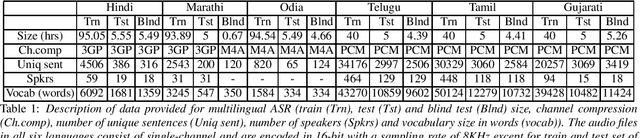
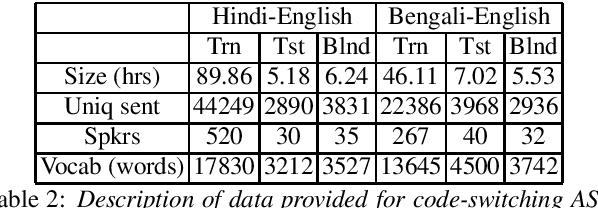
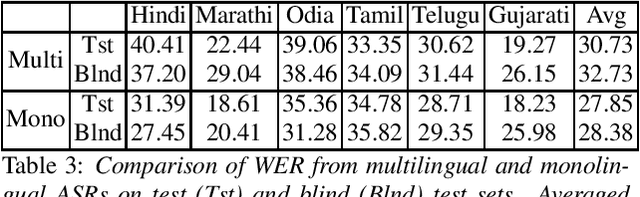
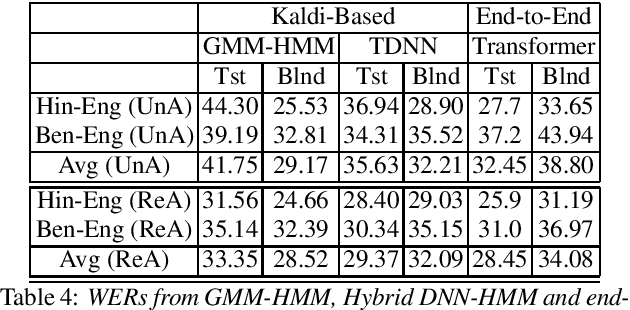
Recently, there is increasing interest in multilingual automatic speech recognition (ASR) where a speech recognition system caters to multiple low resource languages by taking advantage of low amounts of labeled corpora in multiple languages. With multilingualism becoming common in today's world, there has been increasing interest in code-switching ASR as well. In code-switching, multiple languages are freely interchanged within a single sentence or between sentences. The success of low-resource multilingual and code-switching ASR often depends on the variety of languages in terms of their acoustics, linguistic characteristics as well as the amount of data available and how these are carefully considered in building the ASR system. In this challenge, we would like to focus on building multilingual and code-switching ASR systems through two different subtasks related to a total of seven Indian languages, namely Hindi, Marathi, Odia, Tamil, Telugu, Gujarati and Bengali. For this purpose, we provide a total of ~600 hours of transcribed speech data, comprising train and test sets, in these languages including two code-switched language pairs, Hindi-English and Bengali-English. We also provide a baseline recipe for both the tasks with a WER of 30.73% and 32.45% on the test sets of multilingual and code-switching subtasks, respectively.